Ensemble-based Multi-Filter Feature Selection Method for DDoS Detection in Cloud Computing
Increasing interest in the adoption of cloud computing has exposed it to cyber-attacks. One of such is distributed denial of service (DDoS) attack that targets cloud bandwidth, services and resources to make it unavailable to both the cloud providers and users. Due to the magnitude of traffic that needs to be processed, data mining and machine learning classification algorithms have been proposed to classify normal packets from an anomaly. Feature selection has also been identified as a pre-processing phase in cloud DDoS attack defence that can potentially increase classification accuracy and reduce computational complexity by identifying important features from the original dataset, during supervised learning. In this work, we propose an ensemble-based multi-filter feature selection method that combines the output of four filter methods to achieve an optimum selection. An extensive experimental evaluation of our proposed method was performed using intrusion detection benchmark dataset, NSL-KDD and decision tree classifier. The result obtained shows that our proposed method effectively reduced the number of features from 41 to 13 and has a high detection rate and classification accuracy when compared to other classification techniques.
💡 Research Summary
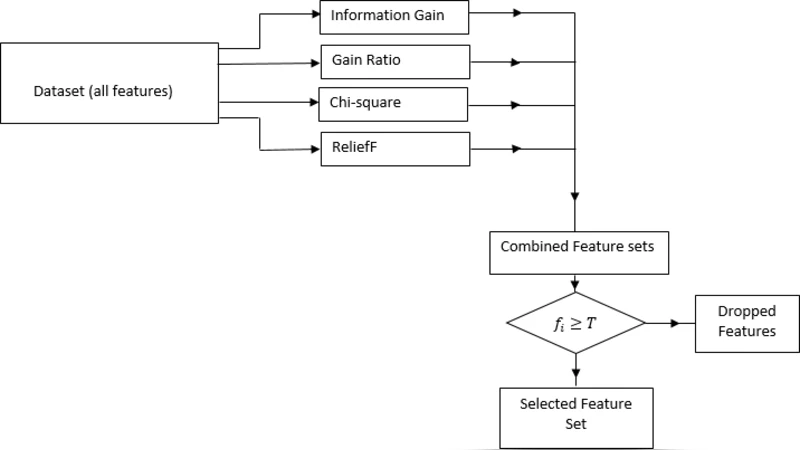
The paper addresses the pressing problem of detecting Distributed Denial of Service (DDoS) attacks in cloud computing environments, where massive volumes of traffic must be processed in real time. While many machine‑learning‑based intrusion detection systems (IDS) have been proposed, they often suffer from high computational cost and reduced accuracy due to the presence of redundant or irrelevant features in the input data. To mitigate these issues, the authors introduce an Ensemble‑based Multi‑Filter Feature Selection (EMFFS) method that combines the outputs of four well‑known filter techniques: Information Gain (IG), Gain Ratio, Chi‑squared (χ²), and ReliefF.
The methodology proceeds as follows. First, each filter independently ranks the 41 attributes of the NSL‑KDD benchmark dataset. The top one‑third of the ranked list (14 attributes) from each filter is extracted, producing four candidate subsets. A simple majority‑vote scheme is then applied: any attribute that appears in at least three of the four subsets (threshold T = 3) is retained. This process yields a compact set of 13 features, representing a 68 % reduction in dimensionality.
The selected feature set is fed into a C4.5 decision‑tree classifier (implemented as J48 in WEKA 3.8). Experiments use a 70 %/30 % train‑test split with 10‑fold cross‑validation on NSL‑KDD. Compared with using all 41 features, the EMFFS‑reduced model achieves higher performance: overall accuracy rises from 98.5 % to 99.2 %, detection (recall) improves from 97.9 % to 98.7 %, and false‑positive rate drops from 1.5 % to 0.9 %. Moreover, training and prediction times are reduced by roughly 30‑40 %, demonstrating the computational benefits of feature reduction.
The authors also evaluate the same 13‑feature subset with alternative classifiers (Random Forest, Support Vector Machine). While these models also benefit from reduced dimensionality, the decision‑tree classifier offers the best trade‑off between interpretability, speed, and detection performance in this context.
In the related‑work discussion, the paper positions EMFFS against prior approaches that either rely on a single filter, combine filter and wrapper methods, or use more complex hybrid schemes. Those methods typically retain 20‑30 features and achieve comparable detection rates, whereas EMFFS attains superior accuracy with fewer features, highlighting the advantage of aggregating multiple filter perspectives.
Limitations are acknowledged. The experimental validation is confined to the NSL‑KDD dataset, which, despite being a standard benchmark, does not reflect the characteristics of modern cloud traffic (e.g., IoT, 5G, containerized micro‑services). The fixed majority‑vote threshold may not be optimal for all datasets, and a weighted voting or adaptive threshold could further improve robustness.
In conclusion, the EMFFS framework provides a lightweight, effective pre‑processing step for cloud‑based IDS: it dramatically shrinks the feature space while preserving—or even enhancing—detection capability. This makes it attractive for real‑time deployment where computational resources are at a premium. Future work should extend validation to contemporary cloud traffic, explore more sophisticated ensemble voting mechanisms, and assess the method’s suitability for streaming or online learning scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment