HyperNets and their application to learning spatial transformations
In this paper we propose a conceptual framework for higher-order artificial neural networks. The idea of higher-order networks arises naturally when a model is required to learn some group of transformations, every element of which is well-approximated by a traditional feedforward network. Thus the group as a whole can be represented as a hyper network. One of typical examples of such groups is spatial transformations. We show that the proposed framework, which we call HyperNets, is able to deal with at least two basic spatial transformations of images: rotation and affine transformation. We show that HyperNets are able not only to generalize rotation and affine transformation, but also to compensate the rotation of images bringing them into canonical forms.
💡 Research Summary
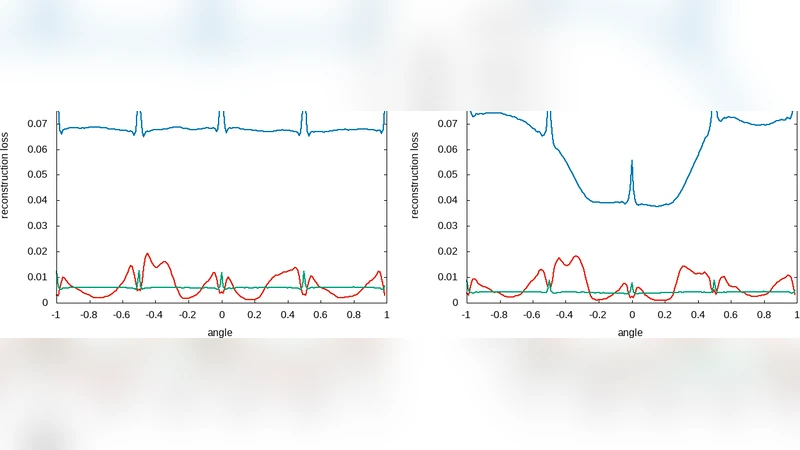
The paper introduces a novel framework called “HyperNets” that treats neural networks as higher‑order functions capable of generating the parameters of a core network conditioned on transformation parameters. Traditional feed‑forward networks learn a mapping f(x, φ) where x is an image and φ denotes a spatial transformation (e.g., rotation angle, affine matrix). In a HyperNet, a separate higher‑order module h_ω receives φ and outputs the weight vector θ(φ) for the core network g_θ. Consequently, the overall mapping becomes g_{h_ω(φ)}(x), which can be interpreted as a curried version of the original function. This design enables the system to learn a whole family of transformations with a single model, rather than training a separate network for each specific φ.
The authors evaluate HyperNets on three tasks using the MNIST dataset: (1) rotation generalization, (2) affine‑transformation generalization, and (3) rotation compensation without explicit angle information. For rotation, they compare a simple one‑layer HyperNet, a deeper HyperNet (including convolutional layers), and a conventional auto‑encoder (AE). Training is performed either on a discrete set of angles (0°, 45°, 90°, …) or on the full continuous range
Comments & Academic Discussion
Loading comments...
Leave a Comment