Cross-lingual Argumentation Mining: Machine Translation (and a bit of Projection) is All You Need!
Argumentation mining (AM) requires the identification of complex discourse structures and has lately been applied with success monolingually. In this work, we show that the existing resources are, however, not adequate for assessing cross-lingual AM, due to their heterogeneity or lack of complexity. We therefore create suitable parallel corpora by (human and machine) translating a popular AM dataset consisting of persuasive student essays into German, French, Spanish, and Chinese. We then compare (i) annotation projection and (ii) bilingual word embeddings based direct transfer strategies for cross-lingual AM, finding that the former performs considerably better and almost eliminates the loss from cross-lingual transfer. Moreover, we find that annotation projection works equally well when using either costly human or cheap machine translations. Our code and data are available at \url{http://github.com/UKPLab/coling2018-xling_argument_mining}.
💡 Research Summary
The paper tackles the previously unexplored problem of cross‑lingual argumentation mining (AM) at the token level. While AM has achieved solid results in monolingual settings—most notably in English, German, and Chinese—there is a lack of comparable, high‑quality, multilingual resources. Existing corpora differ in annotation schemes, domain, and granularity, making it impossible to evaluate cross‑lingual transfer methods fairly. To fill this gap, the authors create a new parallel corpus by translating a widely used persuasive‑essay dataset (PE) of 402 English student essays into German, French, Spanish, and Chinese. Both human translations (HT) performed by native speakers and machine translations (MT) generated with Google Translate are provided. Crucially, translators were instructed to preserve the argumentative structure, i.e., to keep each argument component contiguous in the target language, which enables a clean projection of BIO‑style labels.
Two cross‑lingual transfer strategies are compared. The first, annotation projection, aligns source and target sentences using word‑level alignments (fast_align) and projects the source BIO labels onto the target tokens. When multiple source tokens align to a single target token, a simple majority‑vote or probability‑based resolution is applied. The second strategy, direct transfer, relies on bilingual word embeddings (e.g., MUSE) to map source and target vocabularies into a shared vector space; a CRF model trained only on English data is then applied directly to the target language without any label adaptation.
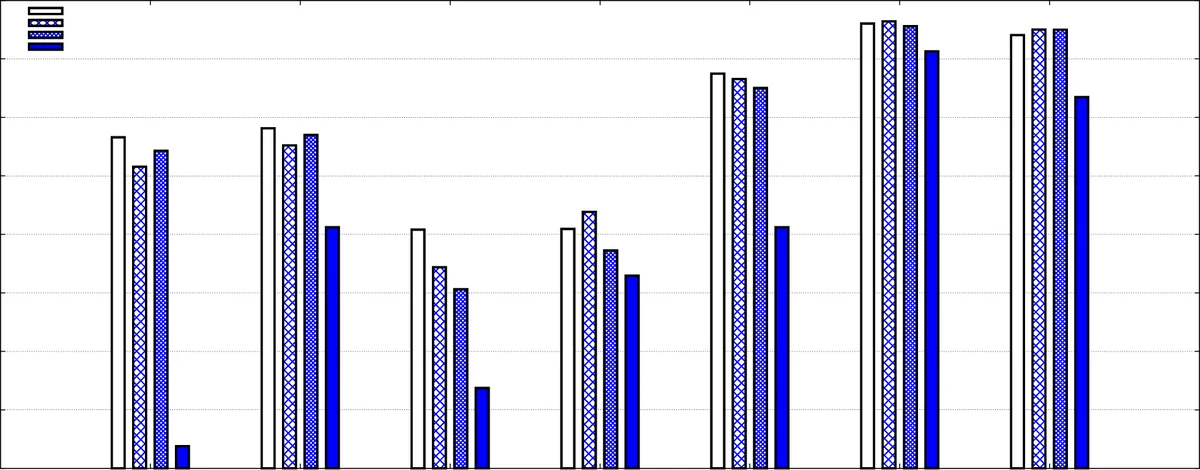
Experiments are conducted on four language pairs (EN‑DE, EN‑FR, EN‑ES, EN‑ZH) using both the human‑translated and machine‑translated versions of PE, as well as on two additional corpora (German‑English micro‑texts MTX and Chinese Review Corpus CRC) to test robustness. Evaluation uses token‑level F1 scores for the five BIO tags (B‑Claim, I‑Claim, B‑Premise, I‑Premise, O). The results are striking: projection consistently outperforms direct transfer by a large margin. With projection, the performance on the target language is within 1–3 % of the monolingual English baseline, and for German and Chinese the gap is virtually eliminated (F1 ≈ 92–94 %). Moreover, there is no statistically significant difference between using human translations and machine translations; modern neural MT provides sufficient fidelity for token‑level label preservation. In contrast, direct transfer lags behind (average F1 ≈ 70 %) because bilingual embeddings, while useful for POS or NER, cannot capture the subtle contextual cues required to distinguish claims from premises.
A cost analysis shows that producing the human‑translated parallel PE corpus required about 270 hours of work and roughly USD 3,000, whereas the machine‑translated versions were generated in a few hours automatically. Since performance is essentially identical, the authors argue that inexpensive MT combined with projection is the most practical route for scaling AM to many languages, especially low‑resource ones where manual annotation would be prohibitive.
The paper also discusses methodological insights. Argumentation mining differs from POS tagging or NER in that label‑token dependencies are weaker and often span longer contexts; therefore, models that rely solely on shared lexical representations (as in direct transfer) struggle. Projection, by directly transferring the gold‑standard annotation through alignment, sidesteps this issue. The authors note that alignment quality is the critical factor; even imperfect MT output can be compensated by robust alignment algorithms. They suggest future work on more sophisticated alignment (e.g., neural attention‑based aligners), semi‑supervised bootstrapping for truly low‑resource languages, and extending the approach to capture argumentative relations (support, attack) beyond component segmentation.
In summary, the study demonstrates that (i) existing AM resources are insufficient for cross‑lingual evaluation, (ii) creating parallel corpora via human or machine translation is feasible, (iii) annotation projection dramatically outperforms bilingual‑embedding direct transfer and essentially closes the cross‑lingual performance gap, and (iv) modern neural machine translation is already good enough to enable high‑quality, token‑level cross‑lingual AM without additional annotation effort. This work paves the way for scalable, multilingual argumentation mining and suggests that projection‑based transfer should be the default strategy for complex, structure‑rich NLP tasks across languages.
Comments & Academic Discussion
Loading comments...
Leave a Comment