SpeechPy - A Library for Speech Processing and Recognition
SpeechPy is an open source Python package that contains speech preprocessing techniques, speech features, and important post-processing operations. It provides most frequent used speech features including MFCCs and filterbank energies alongside with …
Authors: Amirsina Torfi
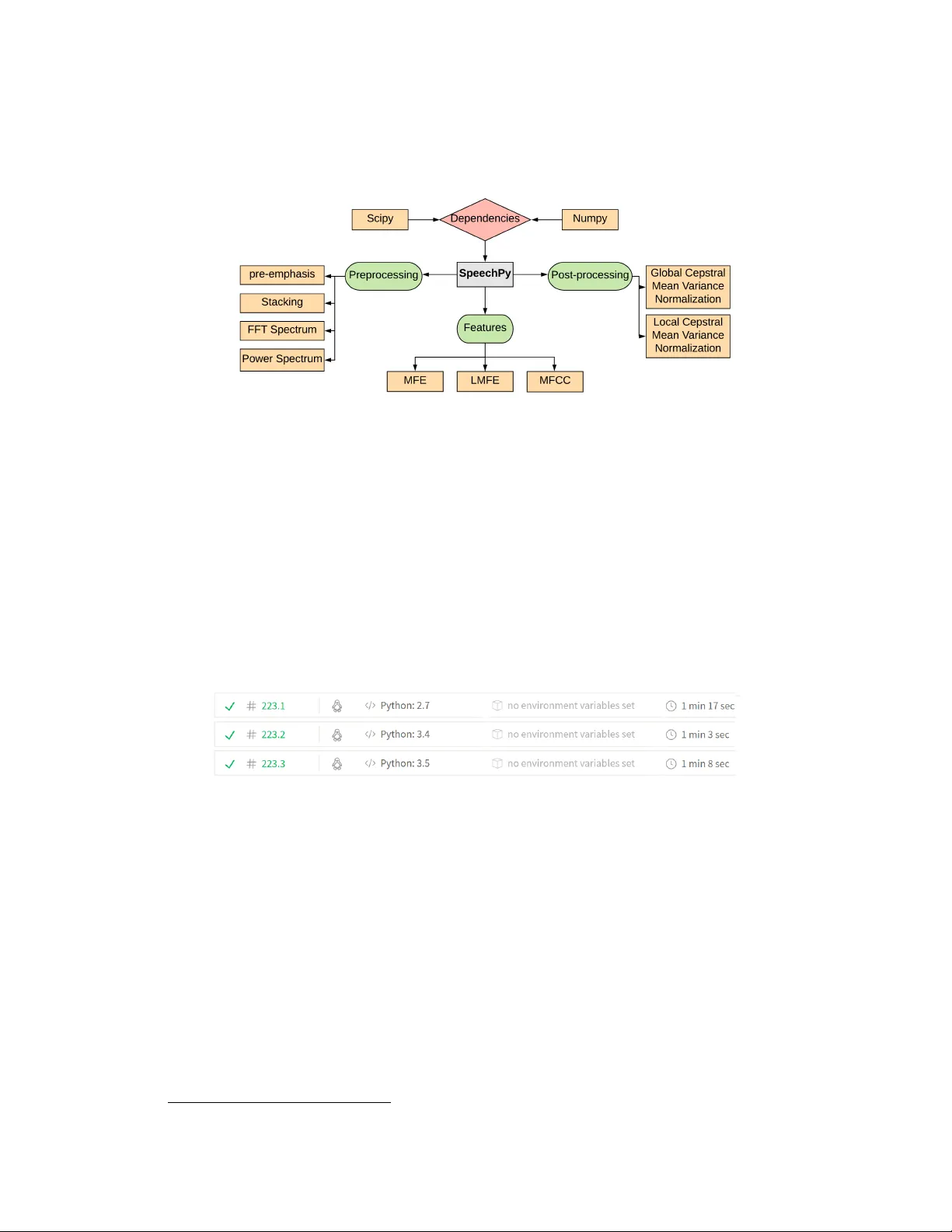
SpeechPy - A Library f or Speech Pr ocessing and Recognition Amirsina T orfi Department of Computer Science V ir ginia T ech amirsina.torfi@gmail.com Abstract SpeechPy is an open source Python package that contains speech preprocessing techniques, speech features, and important post-processing operations. It pro- vides most frequent used speech features including MFCCs and filterbank ener- gies alongside with the log-energy of filter-banks. The aim of the package is to provide researchers with a simple tool for speech feature extraction and process- ing purposes in applications such as Automatic Speech Recognition and Speaker V erification. 1 Overview Automatic Speech Recognition (ASR) requires three main components for further analysis: Pre- processing, feature extraction, and post-processing. Feature extraction, in an abstract meaning, is extracting descriptiv e features from raw signal for speech classification purposes (Fig. 1). Due to the high dimensionality , the raw signal can be less informative compared to extracted higher lev el features. Feature extraction comes to our rescue for turning the high dimensional signal to a lower di- mensional and yet more informativ e v ersion of that for sound recognition and classification [1, 2, 3]. Figure 1: Scheme of speech recognition system. Feature extraction, in essence, should be done considering the specific application at hand. For example, in ASR applications, the linguistic characteristics of the raw signal are of great importance and the other characteristics must be ignored [4, 5]. On the other hand, in Speaker Recognition (SR) task, solely voice-associated information must be contained in extracted feature [6]. So the feature extraction goal is to extract the relev ant feature from the raw signal and map it to a lower dimensional feature space. The problem of feature extraction has been in v estigated in pattern classification aimed at preventing the curse of dimensionality . There are some feature extraction approaches based on information theory [7, 8] applied to multimodal signals and demonstrated promising results [9]. The speech features can be categorized into two general types of acoustic and linguistic features. The former one is mainly related to non-verbal sounds and the later one is associated with ASR and SR systems for which verbal part has the major role. Perhaps one the most famous linguistic feature which is hard to beat is the Mel-Frequency Cepstral Coef ficients (MFCC). It uses speech raw frames in the range from 20ms to 40ms for having stationary characteristics [5]. MFCC is widely used for both ASR and SR tasks and more recently in the associated deep learning applications as the input to the network rather than directly feeding the signal [10, 11, 12]. W ith the advent of deep learning [13, 14], major improvements have been achiev ed by using deep neural networks rather than traditional methods for speech recognition applications [15, 16, 17]. W ith the av ailability of free software for speech recognition such as VOICEBO X 1 , most of these softwares are Matlab-based which limits their reproducibility due to commercial issues. Another great package is PyAudioAnalysis [18], which is a comprehensive package dev eloped in Python. Howe ver , the issue with PyAudioAnalysis is that its comple xity and being too verbose for extracting simple features and it also lacks some important preprocessing and post-processing operations for its current version. Considering the recent advent of deep learning in ASR and SR and the importance of the accurate speech feature extraction, here are the moti vations behind SpeechPy package: • De veloping a free open source package which cov ers important preprocessing techniques, speech features, and post-processing operations required for ASR and SR applications. • A simple package with a minimum de gree of complexity should be av ailable for beginners. • A well-tested and continuously integrated package for future de velopments should be de- veloped. SpeechPy has been de veloped to satisfy the aforementioned needs. It contains the most important preprocessing and post-processing operations and a selection of frequently used speech features. The package is free and released as an open source software 2 . Continuous integration using for instant error check and validity of changes has been deployed for SpeechPy . Moreover , prior to the latest official release of SpeechPy , the package has successfully been utilized for research purposes [19, 20]. 2 Package Eco-system SpeechPy has been de veloped using Python language for its interface and backed as well. An em- pirical study demonstrated that Python as a scripting language, is more ef fecti ve and producti ve than con ventional languages 3 for some programming problems and memory consumption is often ”bet- ter than Java and not much worse than C or C++” [21]. W e chose Python due to its simplicity and popularity . Third-party libraries are av oided e xcept Numpy and Scipy for handling data and numeric computations. 2.1 Complexity As the user should not and does not even need to manipulate the internal package structure, object- oriented programming is mostly used for package dev elopment which provides easier interf ace for the user with a sacrifice to the simplicity of the code. Howe ver , the internal code complexity of the package does not af fect the user experience since the modules can easily be called with the associated arguments. SpeechPy is a library with a collection of sub-modules. The general scheme of the package is provided in Fig. 2. 2.2 Code Style and Documentation SpeechPy is constructed based on PEP 8 style guide for Python codes. Moreov er , it is extensi vely documented using the formatted docstrings and Sphinx 4 for further automatic modifications to the 1 http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html 2 https://github.com/astorfi/speechpy 3 such as C and Jav a 4 http://www.sphinx- doc.org 2 document in case of changing internal modules. The full documentation of the project will be generated in HTML and PDF format using Sphinx and is hosted online. The official releases of the project are hosted on the Zenodo as well 5 [22]. Figure 2: A general view of the package. 2.3 Continuous T esting and Extensibility The output of each function has been ev aluated as well using different tests as opposed to the other existing standard packages. For continuous testing, the code is hosted on GitHub and integrated with T ravis CI. Each modification to the code must pass the unit tests defined for the continuous integra- tion. This will ensure the package does not break with unadapted code scripts. Howe ver , the v alidity of the modifications should always be in vestigated with the owner or authorized collaborators of the project. The code will be tested at each time of modification for Python versions ”2.7” , ”3.4” and ”3.5” . In the future, these versions are subject to change. The T ravis CI interface is depicted in Fig. 3. Figure 3: Tra vic CI web interface after testing SpeechPy against a ne w change. 3 A vailability Operating system T ested on Ubuntu 14.04 and 16.04 L TS Linux, Apple Mac OS X 10.9.5 , and Microsoft Windo ws 7 & 10. W e expect that SpeechPy works on any distribution as long as Python and the package dependencies are installed. Programming language The package has been tested Python 2.7, 3.4 and 3.5. Howe ver , using Python 3.5 is suggested. 5 https://zenodo.org/record/810391 3 Additional system requir ements & dependencies SpeechPy is a light package and small computational power would be enough for running it. Al- though the speed of the ex ecution is totally dependent to the system architecture. The dependencies are as follows: • Numpy • SciPy 4 Aknowledgement This work has been completed in part with computational resources provided by the W est V irginia Univ ersity and is based upon a work supported by the Center for Identification T echnology Re- search (CIT eR) and the National Science Foundation (NSF) under Grant #1650474. References [1] Sadaoki Furui. Speaker -independent isolated word recognition using dynamic features of speech spectrum. IEEE T ransactions on Acoustics, Speech, and Signal Pr ocessing , 34(1): 52–59, 1986. [2] Isabelle Guyon, Ste ve Gunn, Masoud Nikra vesh, and Lofti A Zadeh. F eature extraction: foun- dations and applications , volume 207. Springer, 2008. [3] Hans-G ¨ unter Hirsch and David Pearce. The aurora experimental framew ork for the per- formance ev aluation of speech recognition systems under noisy conditions. In ASR2000- Automatic Speech Recognition: Challenges for the new Millenium ISCA T utorial and Researc h W orkshop (ITRW) , 2000. [4] Dong Y u and Li Deng. A UTOMA TIC SPEECH RECOGNITION. Springer, 2016. [5] La wrence R Rabiner and Biing-Hwang Juang. Fundamentals of speech r ecognition , vol- ume 14. PTR Prentice Hall Englew ood Cliffs, 1993. [6] Joseph P Campbell. Speaker recognition: A tutorial. Pr oceedings of the IEEE , 85(9):1437– 1462, 1997. [7] Amisina T orfi, Sobhan Soleymani, and V ahid T abataba V akili. On the construction of polar codes for achie ving the capacity of marginal channels. arXiv pr eprint arXiv:1707.04512 , 2017. [8] Claude Elwood Shannon. A mathematical theory of communication. ACM SIGMOBILE Mo- bile Computing and Communications Revie w , 5(1):3–55, 2001. [9] Mihai Gurban and Jean-Philippe Thiran. Information theoretic feature extraction for audio- visual speech recognition. IEEE T ransactions on signal pr ocessing , 57(12):4765–4776, 2009. [10] Li Deng, Jinyu Li, Jui-Ting Huang, Kaisheng Y ao, Dong Y u, Frank Seide, Michael Seltzer, Ge- off Zweig, Xiaodong He, Jason W illiams, et al. Recent advances in deep learning for speech research at microsoft. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2013 IEEE In- ternational Confer ence on , pages 8604–8608. IEEE, 2013. [11] Honglak Lee, Peter Pham, Y an Largman, and Andrew Y Ng. Unsupervised feature learn- ing for audio classification using con volutional deep belief networks. In Advances in neural information pr ocessing systems , pages 1096–1104, 2009. [12] Dong Y u and Michael L Seltzer . Improv ed bottleneck features using pretrained deep neural networks. In T welfth Annual Confer ence of the International Speech Communication Associa- tion , 2011. [13] Y ann LeCun, Y oshua Bengio, and Geoffre y Hinton. Deep learning. natur e , 521(7553):436, 2015. 4 [14] Amirsina T orfi and Rouzbeh A Shirv ani. Attention-based guided structured sparsity of deep neural networks. arXiv pr eprint arXiv:1802.09902 , 2018. [15] Ehsan V ariani, Xin Lei, Erik McDermott, Ignacio Lopez Moreno, and Javier Gonzalez- Dominguez. Deep neural networks for small footprint text-dependent speaker verification. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE International Confer ence on , pages 4052–4056. IEEE, 2014. [16] Geof frey Hinton, Li Deng, Dong Y u, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly , Andrew Senior , V incent V anhoucke, Patrick Nguyen, T ara N Sainath, et al. Deep neural net- works for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Pr ocessing Magazine , 29(6):82–97, 2012. [17] Y uan Liu, Y anmin Qian, Nanxin Chen, T ianfan Fu, Y a Zhang, and Kai Y u. Deep feature for text-dependent speaker v erification. Speech Communication , 73:1–13, 2015. [18] Theodoros Giannakopoulos. pyaudioanalysis: An open-source python library for audio signal analysis. PloS one , 10(12), 2015. [19] Amirsina T orfi, Se yed Mehdi Iranmanesh, Nasser Nasrabadi, and Jeremy Dawson. 3d con v o- lutional neural networks for cross audio-visual matching recognition. IEEE Access , 5:22081– 22091, 2017. [20] Amirsina T orfi, Nasser M Nasrabadi, and Jeremy Dawson. T e xt-independent speaker verifica- tion using 3d con volutional neural netw orks. arXiv preprint , 2017. [21] Lutz Prechelt. An empirical comparison of c, c++, jav a, perl, python, rexx and tcl. IEEE Computer , 33(10):23–29, 2000. [22] Amirsina T orfi. SpeechPy: Speech recognition and feature extraction, August 2017. URL https://doi.org/10.5281/zenodo.810391 . 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment