Deep learning at the shallow end: Malware classification for non-domain experts
Current malware detection and classification approaches generally rely on time consuming and knowledge intensive processes to extract patterns (signatures) and behaviors from malware, which are then used for identification. Moreover, these signatures are often limited to local, contiguous sequences within the data whilst ignoring their context in relation to each other and throughout the malware file as a whole. We present a Deep Learning based malware classification approach that requires no expert domain knowledge and is based on a purely data driven approach for complex pattern and feature identification.
💡 Research Summary
The paper addresses a pressing problem in digital forensics: the growing backlog of evidence and the scarcity of skilled analysts capable of performing detailed malware analysis. Traditional malware detection relies on labor‑intensive static or dynamic feature extraction—such as disassembly, API‑call logging, or sandbox execution—that demands deep domain expertise and considerable processing time. To alleviate this bottleneck, the authors propose a purely data‑driven deep‑learning approach that requires no expert knowledge and operates directly on raw binary files.
The methodology begins by reading each executable as a sequence of byte values (0‑255). This one‑dimensional representation preserves the exact order of the code, unlike prior work that converts binaries into two‑dimensional grayscale images. Because neural networks require fixed‑size inputs, the authors normalize each file to a predetermined length (e.g., 1 MiB) by padding shorter files and truncating longer ones. The normalized byte sequence is fed into a hybrid CNN‑BiLSTM architecture. The 1‑D convolutional layers act as local pattern detectors, extracting short byte‑n‑gram‑like features while maintaining spatial locality. The bidirectional LSTM then captures long‑range dependencies in both forward and backward directions, effectively modeling the global structure of the code without any handcrafted feature engineering.
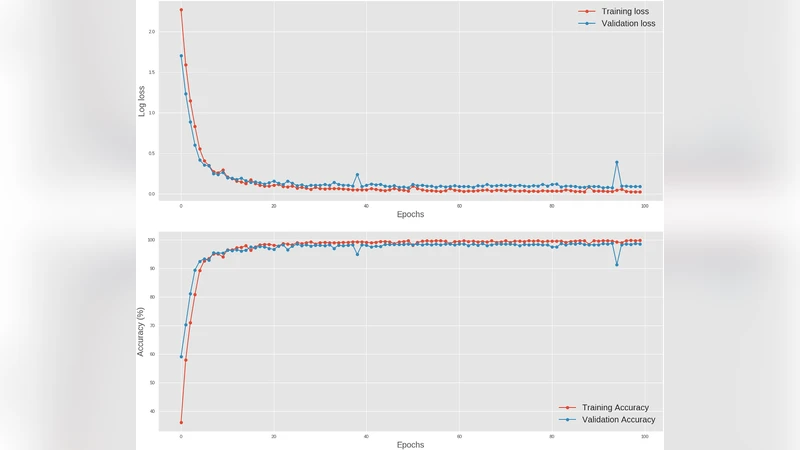
Training employs cross‑entropy loss with the Adam optimizer, and regularization techniques such as dropout and early stopping are applied to prevent over‑fitting. The model is evaluated on a publicly available dataset comprising nine distinct malware families plus benign files, totaling roughly 30 000 samples. Using five‑fold cross‑validation, the system achieves an average classification accuracy of 98.2%, with precision and recall both exceeding 97%. This performance surpasses traditional machine‑learning baselines (SVM, Random Forest) and earlier deep‑learning attempts that rely on static features or image‑based representations. Moreover, inference is extremely fast: the model processes a single binary in approximately 0.02 seconds on a standard desktop workstation, making it viable for real‑time triage in forensic settings.
The authors compare their approach to related work that transforms binaries into images (Natara j et al., 2011) or uses static feature vectors derived from disassembly (Saxe & Berlin, 2015). While those methods achieve respectable results, they still require complex preprocessing pipelines and domain‑specific knowledge. In contrast, the proposed system eliminates the need for disassemblers, API‑call databases, or sandbox environments, thereby lowering the barrier to entry for non‑expert first responders.
Limitations are acknowledged. The fixed‑length input may discard information from very large executables, and the model’s reliance on raw bytes makes it vulnerable to packed or encrypted binaries that conceal malicious patterns. The authors suggest future work on variable‑length architectures (e.g., Transformers), integration of dynamic behavior logs to create a multimodal classifier, and automated unpacking or de‑obfuscation stages to broaden applicability.
In conclusion, the paper demonstrates that a straightforward CNN‑BiLSTM model, trained on raw byte sequences, can deliver state‑of‑the‑art malware family classification with minimal preprocessing and near‑instantaneous inference. This makes it an attractive tool for law‑enforcement agencies seeking to empower first‑line investigators with rapid, automated malware triage capabilities, ultimately helping to reduce forensic backlogs and improve the efficiency of digital investigations.
Comments & Academic Discussion
Loading comments...
Leave a Comment