A Model for Evaluating Algorithmic Systems Accountability
Algorithmic systems make decisions that have a great impact in our lives. As our dependency on them is growing so does the need for transparency and holding them accountable. This paper presents a model for evaluating how transparent these systems are by focusing on their algorithmic part as well as the maturity of the organizations that utilize them. We applied this model on a classification algorithm created and utilized by a large financial institution. The results of our analysis indicated that the organization was only partially in control of their algorithm and they lacked the necessary benchmark to interpret the deducted results and assess the validity of its inferencing.
💡 Research Summary
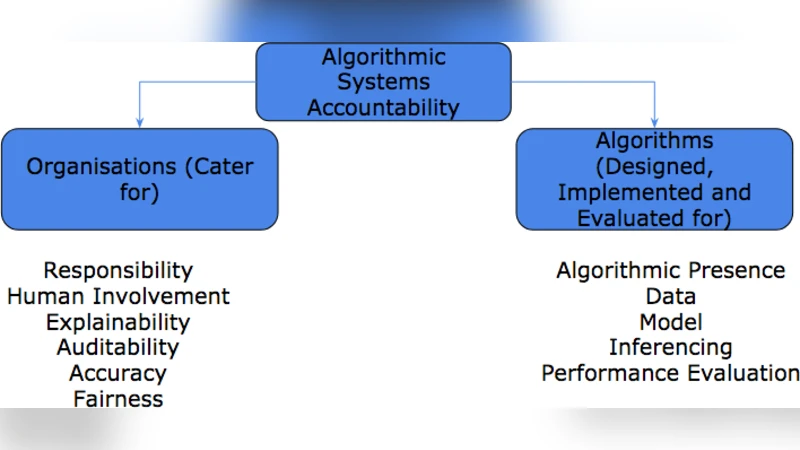
The paper addresses the growing societal demand for transparency and accountability in algorithmic decision‑making systems. Recognizing that technical transparency alone is insufficient, the authors propose an integrated evaluation model that simultaneously assesses the algorithmic component and the maturity of the organization that deploys it. The model is built around two primary dimensions: Algorithmic Transparency and Organizational Maturity.
Algorithmic Transparency is broken down into six sub‑dimensions: Responsibility, Human Involvement, Explainability, Accuracy, Auditability, and Fairness. For each sub‑dimension the authors define concrete metrics (e.g., existence of responsibility policies, proportion of human‑in‑the‑loop steps, model interpretability scores, performance metrics, logging completeness, bias detection measures) and prescribe data‑collection methods such as document review, stakeholder interviews, and quantitative analysis.
Organizational Maturity comprises five domains: Policy & Process, Data Management, Model Management, Risk Management, and Ethics & Legal Compliance. Each domain is evaluated on a maturity scale ranging from Initial to Optimized/Innovative, with specific criteria (e.g., documented data governance, version‑controlled model repositories, risk assessment procedures, ethical review boards).
Scoring is performed by assigning a numeric value to each metric, applying pre‑determined weights (derived from expert surveys and literature review), and aggregating the results into a composite score for each dimension and an overall accountability score. The weighting scheme is designed to be adaptable to different industry contexts.
To validate the model, the authors apply it to a real‑world case: a classification algorithm used by a large financial institution to assign credit risk categories to customers. The assessment follows four stages: (1) Data Collection & Pre‑processing – data quality policies exist but labeling criteria are undocumented, resulting in a low score; (2) Model Design & Training – thorough documentation of model choice and hyper‑parameter tuning yields a high score; (3) Deployment & Operations – a CI/CD pipeline and monitoring are in place, giving a moderate maturity rating; (4) Result Interpretation & Feedback – this stage scores poorly across Explainability, Responsibility, and Auditability. The institution lacks a clear benchmark for interpreting model outputs, has no formal policy assigning responsibility for algorithmic errors, and its logging and access‑control mechanisms are insufficient for external audits.
Overall, the financial institution demonstrates strong technical performance but only partial organizational control over the algorithm, leading to an overall accountability score below the acceptable threshold. This finding underscores the paper’s central claim: effective algorithmic accountability requires both robust technical transparency and mature organizational governance.
The authors discuss practical implications. Regulators could adopt the model as a benchmark for assessing corporate algorithmic risk, while internal audit teams can use it as a periodic health‑check or pre‑deployment checklist. The model is extensible; future versions could incorporate additional ethical dimensions such as data sovereignty, user privacy, and broader AI ethics guidelines.
Limitations are acknowledged: the weighting of metrics is partly subjective, and validation is based on a single case study, limiting generalizability. Future work is proposed to include multi‑industry, multi‑case validation, optimization of weightings via statistical methods, development of an automated assessment tool, and integration with real‑time monitoring dashboards.
In conclusion, the paper contributes a comprehensive, multi‑layered framework for evaluating algorithmic accountability, demonstrates its application in a high‑stakes financial context, and highlights the critical interplay between algorithmic design and organizational processes in achieving responsible AI deployment.
Comments & Academic Discussion
Loading comments...
Leave a Comment