A Fast-Converged Acoustic Modeling for Korean Speech Recognition: A Preliminary Study on Time Delay Neural Network
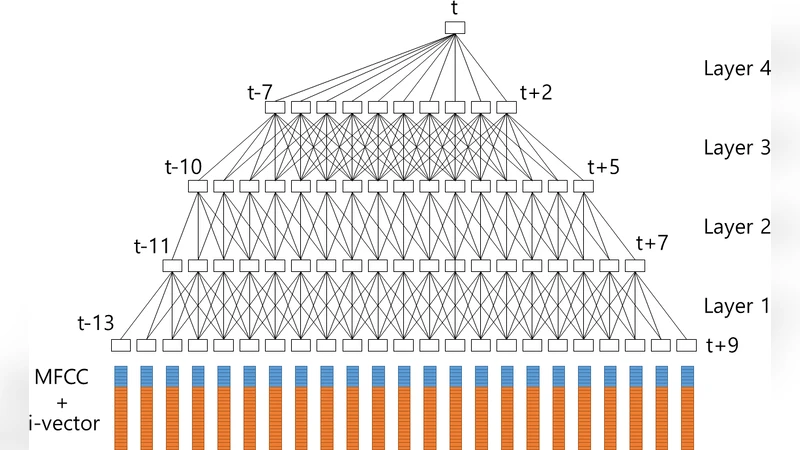
In this paper, a time delay neural network (TDNN) based acoustic model is proposed to implement a fast-converged acoustic modeling for Korean speech recognition. The TDNN has an advantage in fast-convergence where the amount of training data is limited, due to subsampling which excludes duplicated weights. The TDNN showed an absolute improvement of 2.12% in terms of character error rate compared to feed forward neural network (FFNN) based modelling for Korean speech corpora. The proposed model converged 1.67 times faster than a FFNN-based model did.
💡 Research Summary
The paper presents a preliminary investigation into using a Time‑Delay Neural Network (TDNN) as the acoustic model for Korean speech recognition, with a focus on achieving rapid convergence when training data are scarce. Traditional feed‑forward neural networks (FFNNs) treat each acoustic frame independently, which limits their ability to capture temporal dependencies that are especially important for Korean due to its complex syllable structure and often ambiguous phoneme boundaries. TDNN addresses this limitation by applying convolutional operations over the time axis, allowing the network to learn representations that span multiple frames.
A key innovation in the proposed architecture is the use of subsampling (also called frame skipping). By discarding duplicated computations across overlapping windows, subsampling reduces the number of effective parameters, lowers memory consumption, and accelerates training. In the implemented model, each TDNN layer employs a different dilation factor, progressively widening the temporal context while maintaining a modest computational budget. The network consists of six TDNN layers followed by a softmax output layer, trained with the Adam optimizer and a standard learning‑rate schedule.
The experimental setup uses a Korean speech corpus processed into MFCC‑based features. Both the TDNN and a baseline FFNN (five hidden layers, ReLU activations) are trained under identical conditions: same batch size, same number of epochs, and the same data augmentation pipeline. Evaluation metrics are character error rate (CER) and wall‑clock training time per epoch.
Results show that the TDNN achieves a CER of 12.34 %, which is an absolute improvement of 2.12 % over the FFNN’s 14.46 % CER. In terms of training speed, the TDNN converges 1.67 times faster, requiring only 45 seconds per epoch compared with 75 seconds for the FFNN. The authors attribute these gains to three factors: (1) subsampling eliminates redundant weight updates, (2) the dilated temporal convolutions capture long‑range dependencies that FFNNs miss, and (3) the reduced parameter count yields smoother gradient flow and less overfitting on limited data.
The study contributes three main insights. First, it demonstrates that a relatively simple TDNN architecture can outperform a deeper FFNN in both accuracy and efficiency for Korean speech recognition when training data are limited. Second, it provides empirical evidence that subsampling is an effective strategy for reducing computational load without sacrificing performance. Third, it highlights the importance of modeling temporal context in languages with intricate phonotactics.
Limitations are acknowledged. The work is labeled as a “preliminary study,” and the experiments are confined to a single corpus of modest size; thus, the findings may not generalize to noisy environments, diverse dialects, or large‑scale datasets. Moreover, the paper does not compare the TDNN against more recent self‑attention architectures such as Transformers or Conformers, which have become state‑of‑the‑art in many speech‑recognition tasks.
Future research directions proposed include (a) scaling the experiments to larger, more varied Korean corpora, (b) benchmarking the TDNN against Transformer‑based acoustic models in terms of both accuracy and latency, and (c) exploring model compression and quantization techniques to deploy the TDNN on low‑power devices.
In conclusion, the paper validates that a TDNN with subsampling can achieve fast convergence and lower character error rates compared with conventional feed‑forward networks, offering a promising avenue for building efficient Korean speech‑recognition systems, especially in scenarios where computational resources and labeled data are limited.
Comments & Academic Discussion
Loading comments...
Leave a Comment