Subjective and objective experiments on the influence of speakers gender on the unvoiced segments
Subjective and objective experiments are conducted to understand the extent to which a speaker's gender influences the acoustics of unvoiced (U) sounds. U segments of utterances are replaced by the corresponding segments of a speaker of opposite gend…
Authors: A Madhavaraj, T V Ananthapadmanabha, A G Ramakrishnan
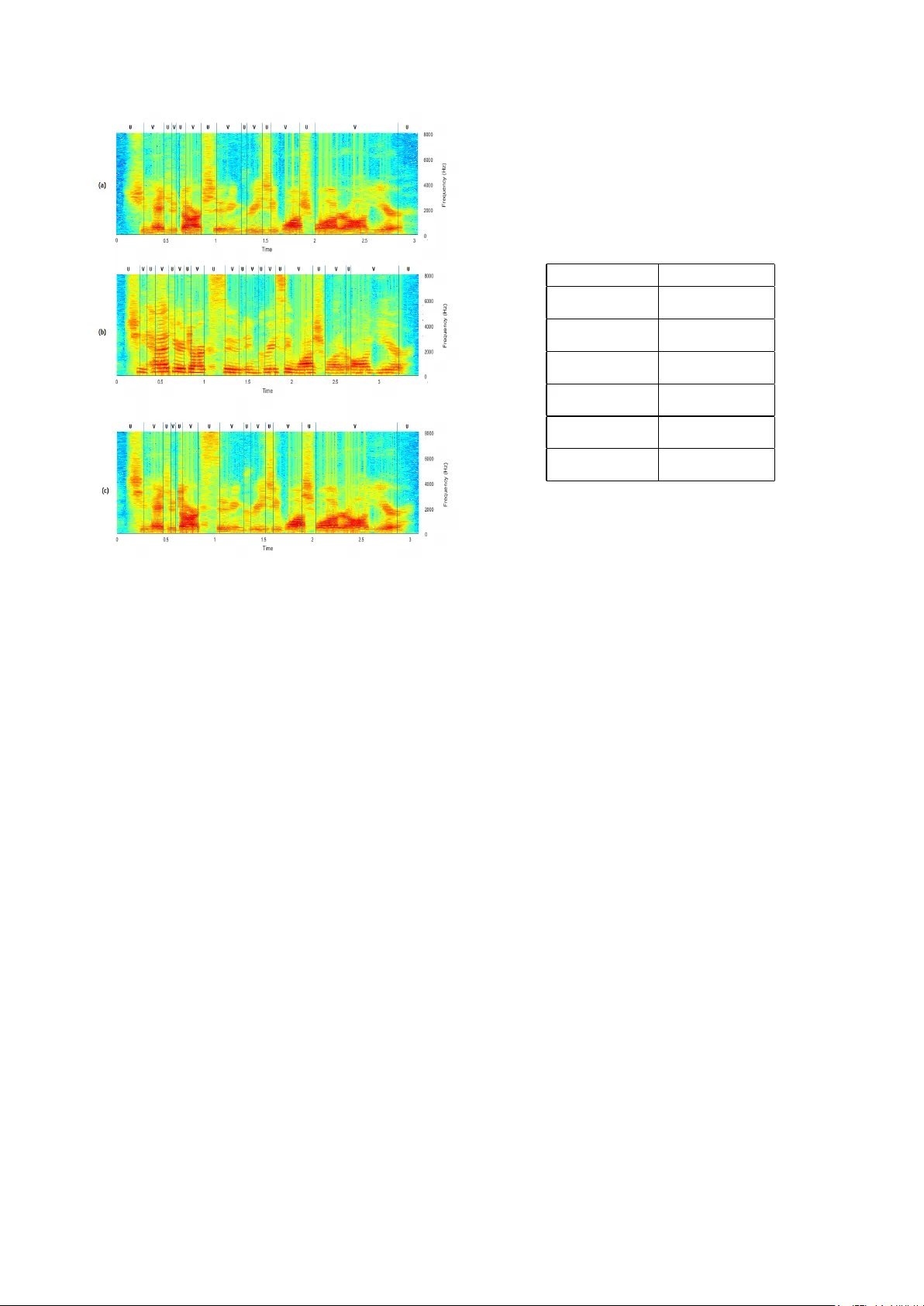
Subjectiv e and objectiv e experiments on the influence of speaker’ s gender on the un voiced segments A Madhavaraj 1 , T V Ananthapadmanabha 2 and A G Ramakrishnan 1 1 MILE Lab, Department of Electrical Engineering, Indian Institute of Science, Bangalore 560012 2 V oice and Speech Systems, Malleswaram, Bangalore 560003, India madhavaraja@iisc.ac.in, tva.blr@gmail.com, agr@iisc.ac.in Abstract Subjectiv e and objectiv e experiments are conducted to un- derstand the extent to which a speaker’ s gender influences the acoustics of un voiced (U) sounds. U segments of utterances are replaced by the corresponding segments of a speaker of opposite gender to prepare modified utterances. Humans are asked to judge if the modified utterance is spoken by one or two speakers. The experiments show that human subjects are unable to distinguish the modified from the original. Thus, lis- teners are able to identify the U segments irrespectiv e of the gender , which may be based on some speaker-independent in- variant acoustic cues. T o test if this finding is purely a per- ceptual phenomenon, objectiv e experiments are also conducted. Gender specific HMM based phoneme recognition systems are trained using the TIMIT training set and tested on (a) utterances spoken by the same gender (b) utterances spoken by the oppo- site gender and (c) the modified utterances of the test set. As expected, the performance is the highest for case (a) and the lowest for case (b). The performance degrades only slightly for case (c). This result shows that the speaker’ s gender does not as strongly influence the acoustics of U sounds as they do the voiced sounds. Index T erms : Unv oiced sounds, v oiced sounds, perception, vo- cal tract, phoneme recognition, gender-dependence, stops. 1. Introduction It has been shown that the formant data of vo wel sounds are strongly influenced by the speaker’ s gender and age [1, 2]. From a speech production point of vie w , a change in size of the vocal tract must affect the v ocal tract frequency response of un voiced sounds as well. Such a view is supported by several pre vious studies. The influence of gender on the perception of un voiced sounds has been reported [3]. Using linear prediction coeffi- cients (LPCs) based features, the highest accuracy for gender recognition has been obtained for voiced fricatives of all the speech sounds [4]. Gradient normalization has been applied on fricati ve sounds in a gender identification perception exper - iment [5]. T o compensate for the speaker’ s influence, spectral warping techniques [6, 7] have been proposed and techniques dev eloped for voiced (V) sounds are applied to the un voiced (U) sounds as well. Speak er recognition accuracy is known to improv e if U sounds are handled separately , indicating speaker specific influence on U sounds [8]. In [9], the relativ e speaker discriminati ve properties of dif- ferent phones are studied and the authors have found that the stop consonants provide the worst performance. Huang and Epps [10] hav e integrated phone segmentation with forensic voice comparison (FVC) system and showed that vowels and nasals contribute the most to the reliability and v alidity of the system. Recently , Moez et. al. [11] have in vestigated the im- pact of each phoneme class for FVC application. They sho wed that vo wels and nasals perform better than av eraged phonemic content, while the fricatives do not perform better than the av- eraged content. The speaker recognition experiments of Jung et. al. [12] indicate that the affricate, stop and fricati ve phone classes do not contribute much in recognition and by selecting lesser number of frames from these classes improv es the recog- nition performance. Since there is no clearly defined formant structure for un- voiced sounds, we attempt to deduce the influence of gender on U sounds indirectly by means of subjective and objectiv e ex- periments. The proposed experiments also indirectly look at the relativ e importance of modeling the human speech production and perception mechanisms in designing speech and speaker recognition systems. This paper is organized as follows. Section 2 describes the algorithm used for generating the stimuli by mixing un voiced and voiced segments from the recordings of the same sentence spoken by two speakers from the opppsite sexes. It also dis- cusses the listening test conducted on 50 human subjects for subjectiv e ev aluation of our hypothesis. In Sec. 3, we illus- trate the ASR experiments that hav e been conducted by training independent phoneme recognition models on male and female recordings and testing those models on the different types of modified utterances produced. Section 4 describes the results of the subjective and objective experiments conducted in our studies. Finally , we conclude the paper in Sec. 5. 2. Subjective Listening Experiments 2.1. Preparation of the modified utterances as stimuli The TIMIT [13] database gives the boundaries of voiced sono- rants and unv oiced segments (silence, fricatives and stops). All vo wels, semi-vo wels and nasals are included under the voiced sonorant phones. Short SX utterances of the TIMIT database, with 4 to 6 words, are used for the perceptual tests. Each orig- inal utterance is modified in two ways: (a) Set1 of test utter- ances: All un voiced segments in the utterance (of an SX file) spoken by a male speaker are replaced by the corresponding (i.e., from the same SX filename) un voiced segments of a fe- male speaker (denoted as M < FU) and vice-versa (F < MU). For this set, five original utterances from each gender are used. (b) Set2 of test utterances: In addition to the replacement of all the un v oiced segments, as in Set1, two consecutiv e sonorant seg- ments of the utterance spoken by a male speaker are replaced by the corresponding sonorant segments of a female speaker (denoted as M < FvU) and vice-versa (F < MvU). For this set, another five utterances are used. The Set2 stimuli utterances are included partly to increase the lev el of confidence of the listeners (that there are indeed utterances with mixed speakers) and partly to study the relative perceptual influence of speaker’ s identity on the voiced and un voiced segments. The procedure to mix two signals is not a straight-forward task, since the same sentence spoken by tw o speakers may ha ve different phonetic transcriptions and therefore differ in the num- ber of phones. T o effecti vely handle such v ariations, we hav e used dynamic programming with back-tracking technique to align the two phone label sequences (and their U-V and V -U transitions). First, we map each phone in the phone label se- quence to either V or U. Next, we note down the time instants, where the transitions from V to U and from U to V occur . W e then use dynamic programming to obtain the optimal path to align the two sequences. Next, we traverse along this optimal path and construct a mapping table, which maps the transition instants in the source wa veform to those in the target w av eform. Using this mapping table, we can now pick the ’V’ segments from the source signal and ’U’ segments from the target signal and stitch them together to finally construct the mixed signal. The mixed signal is smoothed at the points of stitching to a void discontinuities in the signal. This entire procedure is illustrated in Fig. 1. Figures 2 (a) and (b) sho w the spectrograms of one of the sentences spoken by a male (source) and a female (target) speaker , respectiv ely . Figure 2 (c) shows the spectrogram of the mixed signal, where the voiced portion is tak en from the source signal and the un v oiced, from the target signal. 2.2. Listening tests by human subjects Including 10 original utterances, a total of 25 stimuli are pre- sented to each subject in a random order . After each utterance is played, the subject is asked to decide on his/her perception as ’I hear only one speaker’ or ’I hear two speakers’. A total of 50 subjects (25 male + 25 female), in the age group of 18 to 60 years, participated as listeners. The results of the listening tests are presented and discussed in Section 4. 3. Phoneme Recognition Experiments All the phoneme recognition system models described below hav e been trained using the Kaldi toolkit [14]. 3.1. T raining of Acoustic models In the TIMIT training set, there are a total of 3260 and 1360 utterances for male and female speakers, respectively . Using this data, two sets of models have been trained for male and female data, separately . Each model-set comprises the follow- ing four models: (i) monophone (Mono), (ii) triphone (T ri), (iii) triphone with LDA+MLL T (LMT) and (iv) triphone with LD A+MLL T+SA T (LMST). The models hav e been trained in a sequence using force-alignments from the previous stage. Thus, totally eight distinct ASR models hav e been trained for the ob- jectiv e experiments. W e hav e used the standard procedure for training the acous- tic models as used in the s5 TIMIT Kaldi recipe [14]. First, we extract 13-dimensional mel-frequency cepstral coefficients (MFCC) features with delta and delta-delta MFCC to construct a 39-dimensional feature v ector and train a Mono HMM for each of the 48 context-independent phonemes. All HMMs are three state left-to-right models with a total of 1000 Gaus- sian densities shared among all the states. The second model (T ri) is a set of triphone, context-dependent HMM models trained on the 39-dimensional features with a total of 2500 Figure 1: Steps in volved in the cr eation of mixed speech (M < FU and F < MU), where all the un voiced segments of the sour ce utterance ar e replaced by those of the tar get utterance. states and 15000 Gaussians. The third (LMT) is a maximum likelihood, linear transformation based triphone model, trained on 40-dimensional features obtained after splicing and linear transformation (using linear-discriminant analysis). The fourth model (LMST) is a triphone HMM, which is a combination of LD A, MLL T and speaker-adapti ve models trained using max- imum likelihood linear regression. In all our experiments, we hav e used tri-gram phone-lev el language model estimated from the training corpus. 3.2. Recognition tests on the learnt acoustic models W e have neglected those sentences which were spoken by only one gender and generated 714 utterances for male and 392, for female. For each of these utterances, a mixed utterance (M < FU or F < MU; M < FvU or F < MvU) has been created as described in Sec. 2.1. In addition, to test the relati ve influence of stops and fricativ es, a mix ed utterance (M < FSSt) is prepared, where only the silence and stop segments of a male speaker’ s utterance are replaced by the corresponding segments from the utterance of a female speaker and vice-versa (F < MSSt). All the utterances, i.e., the original and the mixed, have been tested by automatic Figure 2: Spectr ograms of (a) a sour ce male utterance, (b) a tar get female utterance of the same sentence, and (c) mixed ut- terance, with all the un voiced segments of the male utterance r eplaced by those of the female, (M < FU). speech recognition (ASR) models trained separately on male or female original utterances only . Several experiments are con- ducted: (i) Male model is tested on male utterances, (ii) Male model is tested on female utterances, (iii) Male model is tested on mixed utterances with male voiced and female un voiced or stop segments, (iv) Male model is tested on mixed utterances with female voiced and male un voiced or stop se gments; (v) Fe- male model was tested on male utterances; (vi) Female model was tested on female utterances; (vii) Female model is tested on mixed utterances, with male voiced and female un v oiced or stop segments; (viii) Female model is tested on mixed utter- ances with female voiced and male un voiced or stop segments. 4. Results and Discussion 4.1. Results of perception experiments For the original utterance, the expected correct response is ’I hear only one speaker’ and for all the mixed utterances, the ex- pected correct response is ’I hear two speakers’. T able 1 lists the mean accuracy of the correct response for all the 25 test utterances by the 50 listeners. The mean accuracy of recogniz- ing the original male utterances by all the listeners is 98.4%. The corresponding value for the original female utterances is 99.2%. When all the un voiced segments (U) and two consecu- tiv e voiced segments (v) of the male utterances are replaced by the corresponding segments from female utterances (M < FvU), the listeners ha ve correctly identified the presence of two speak- ers 99.3% of the time. For a similar mixing of the female utter- ances (F < MvU), listeners identified them correctly 100% of the T able 1: Results of per ceptual tests conducted on 50 subjects, by pr esenting the original and modified utterances. M: utterances spoken by males; F: utterances spoken by females; U: all un- voiced se gments of an utter ance; v: two consecutive voiced se g- ments in the same utterance; vU: T wo consecutive voiced se g- ments, in addition to all un voiced se gments; M < FU (F < MU): U of M (F) r eplaced by U of female (male); M < FvU (F < MvU): vU of M (F) r eplaced by vU of F (M). T est data Accuracy M 98.4 F 99.2 M < FvU 99.3 F < MvU 100.0 M < FU 0.4 F < MU 0.0 time. On the other hand, when only the unv oiced segments of female utterances are replaced (F < MU), none of the listeners could identify even one of the mixed utterances as having parts from two different speakers. Thus, the accuracy of correct re- spose of two speakers is 0%. The corresponding value, when all the unv oiced segments of male utterances are replaced by those of females (M < FU), is only 0.4%. These results clearly indicate that human listeners are unable to detect a change of speaker , when all the unv oiced segments of an utterance (which, usually are nearly 50% in duration) are replaced by those from the utterance spoken by a speaker of opposite gender . 4.2. Phone recognition r esults T able 2 summarizes the recognition results obtained by the 8 different ASR models (4 trained on male speech and the others, trained on female speech). T est data consists of (a) the original test utterances from male speakers and (b) their modifications by the replacement of segments (SSt, U or vU) by the corre- sponding segments of female speak ers. T able 3 summarizes the recognition results obtained by the 8 different ASR models on the test utterances from female speakers and their different mod- ifications by the replacement of segments (SSt, U or vU) by the corresponding segments of male speak ers. The results obtained on the male and female utterances are discussed separately . The phone error rates (PER) are the lowest, when the orig- inal male utterances are recognized by models trained only on male data (left half of T able.2). The PER of 25.3% obtained by the Mono model reduces gradually with the sophistication in the model to triphone, LMT and LMST , and reaches the lowest value of 16.8%. The first four entries (left half of T able.2) in the second to fourth rows also show that the performance sys- tematically de grades as more and more female data replaces the segments of the male utterance. The PER of the best ASR model (LMST) degrades by about 1.4% by the replacement of stops (M < FSSt), whereas by the replacement of all the U segments (both stops and fricatives) (M < FU), the accuracy degrades by 1.8%, a difference of only about 0.4%. In other words, the influence of gender on stop consonants is much more significant (nearly 4 times) than on fricativ es. This may appear contrary to the postulate of the in- variance of stop consonants [15, 16]. Howe ver, it may be ar- gued that the ASR results, which are based on MFCCs, can- not be generalized. Replacement of e ven a couple of sonorant segments brings down the relative accuracy by 4.4%, whereas when all the U segments are replaced, the drop in accuracy is only 1.8%. Referring to the right half of T able 2, as expected, the recog- nition accuracies for the four ASR models trained on female speech are significantly lower than the values obtained by the models trained on male speakers’ data. Referring to rows 2-4, when the same male (original or modified) utterances are rec- ognized by ASR models trained on female speech, the general trend is the opposite. In other words, the PER reduces with in- creased proportion of female speech in the utterances. Howev er , there are exceptions, and in the case of Tri, LMT and LMST models, in some of the cases, the PER increases when more segments are replaced by segments from female speech. Ho w- ev er , the error rates are far higher than the corresponding values for the male ASR models. The results are anomalous, since for the case of M < FU, the result is better than the case of M < FSSt. T able 2: Phone err or rates for the phoneme reco gnition sys- tem for matched, mismatched and mixed test data created fr om male speech. The dif fer ent models used for the ASR experiments ar e: Mono: monophone; T ri: tripohone; LMT :LD A+MLL T tri- phone; LMST : LD A+MLLT+SA T triphone. SSt: Silent and stop consonant se gments of any utterance; M < FSSt: SSt of M r e- placed by SSt of F . The other notations ar e the same as those used in T able 1. T est data HMM trained on male speech HMM trained on female speech Mono T ri LMT LMST Mono T ri LMT LMST M 25.3 19.9 18.2 16.8 39.2 37.4 36.1 26.1 M < FSSt 26.7 21.8 19.6 18.2 38.7 38.0 36.5 27.6 M < FU 27.7 22.7 20.4 18.6 38.1 37.2 35.5 26.9 M < FvU 29.8 26.3 25.9 23.2 36.5 36.1 33.8 28.9 The results for female utterances (T able 3, right half) sho ws that the lowest phone error rate is obtained when the original female utterances are recognized by models trained only on fe- male speech. The PER of 26.0% obtained by the Mono model reduces gradually with the sophistication in the model to tri- phone, LMT and LMST , and reaches the lowest value of 18.6%. The degradation in accurac y due to the replacement of stops by those of male speakers is about 2.1%, whereas the contribution to degradation by fricativ es is only about 0.8%. This once again indicates the significant influence of gender on the stop conso- nants. 5. Conclusion In order to further our understanding of the influence of speaker’ s gender on unv oiced sounds, we have conducted both subjectiv e and objectiv e experiments. When the acoustic sig- nal of all the unv oiced segments is replaced by the correspond- ing signal of a speaker of opposite gender , listeners are unable to detect the speaker change. Howe ver , objectiv e experiments based on the PER of a phoneme recognition system show that the speaker’ s gender does influence the un voiced sounds. Based T able 3: Phone err or rates for the phoneme r ecognition system for matched, mismatched and mixed test data, cr eated fr om fe- male speech. F < MSSt: SSt of F r eplaced by SSt of M. The other notations ar e the same as those used in T able 1. T est data HMM trained on male speech HMM trained on female speech Mono T ri LMT LMST Mono T ri LMT LMST F 39.2 37.0 39.2 25.1 26.0 22.2 20.7 18.6 F < MSSt 38.8 36.4 38.9 26.3 27.2 24.2 22.1 20.7 F < MU 37.1 34.7 37.5 25.7 29.1 25.4 23.9 21.5 F < MvU 36.4 33.8 36.0 27.9 31.5 29.5 27.5 26.3 on these apparently contradictory findings, we infer the follow- ing: (i) listeners may be using speaker -independent acoustic cues, other than MFCCs, for identifying un v oiced sounds; (ii) listeners may not use unv oiced sounds for identifying the gen- der of a speaker; and (iii) listeners may not be making use of any speaker normalization strate gy for un voiced sounds. The phone error rates on the modified utterances are slightly higher than those when the ASR is trained and tested on the samples of the same gender . The PER of the ASR increases monotonically with the increase in the proportion of segments replaced by those of the opposite sex. The degradation due to the replacement of stop segments is more significant than that of fricatives. The results also indicate that the speaker recogni- tion systems must giv e higher weightage to modeling the speech production mechanism, whereas the speech recognition systems ought to giv e more weightage to modeling the speech percep- tion mechanism. 6. References [1] G. Peterson and H. Barney , “Control methods used in a study of the vo wels, ” Journal of Acoustical Society of America , vol. 24, no. 2, pp. 175–184, 1952. [2] G. Fant, Speech sounds and featur es. The MIT Press, 1973. [3] V . A. Mann and B. H. Repp, “Influence of vocalic context on perception of ’ sh’-’s’ distinction, ” P er ception and psychophysics , vol. 28, no. 3, pp. 213–228, 1980. [4] K. W u and D. G. Childers, “Gender recognition from speech. part i: Coarse analysis, ” The journal of the Acoustical society of Amer- ica , vol. 90, no. 4, pp. 1828–1840, 1991. [5] E. A. Strand and K. Johnson, “Gradient and visual speaker nor- malization in the perception of fricatives. ” in K ONVENS , 1996, pp. 14–26. [6] L. Lee and R. C. Rose, “Speaker normalization using efficient frequency warping procedures, ” in Acoustics, Speech, and Signal Pr ocessing, ICASSP , Pr oceedings IEEE International Conference on , vol. 1, pp. 353–356. [7] L. F . Uebel and P . C. W oodland, “ An in vestigation into v ocal tract length normalisation, ” in Sixth European Conference on Speech Communication and T echnolo gy , 1999. [8] G. Pradhan and S. M. Prasanna, “Speaker verification by vo wel and nonvo wel like segmentation, ” IEEE T ransactions on Audio, Speech, and Language Processing , vol. 21, no. 4, pp. 854–867, 2013. [9] J. P . Eatock and J. S. Mason, “ A quantitati ve assessment of the rel- ativ e speaker discriminating properties of phonemes, ” in Acous- tics, Speech, and Signal Processing , ICASSP , IEEE International Confer ence on , vol. 1, Apr 1994, pp. 133–136. [10] C. C. Huang and J. Epps, “ A study of automatic phonetic segmen- tation for forensic voice comparison, ” in IEEE International Con- fer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , March 2012, pp. 1853–1856. [11] A. Moez, B. Jean-Franois, B. K. W aad, R. Solange, and K. Juli- ette, “Phonetic content impact on forensic voice comparison, ” in IEEE Spoken Language T echnology W orkshop (SLT) , Dec 2016, pp. 210–217. [12] C. S. Jung, M. Y . Kim, and H. G. Kang, “Selecting feature frames for automatic speaker recognition using mutual informa- tion, ” IEEE T ransactions on Audio, Speech, and Language Pro- cessing , vol. 18, no. 6, pp. 1332–1340, 2010. [13] J. S. Garofolo, L. F . Lamel, W . M. Fisher, J. G. Fiscus, and D. S. Pallett, “DARP A TIMIT acoustic-phonetic continuous speech corpus cd-rom. nist speech disc 1-1.1, ” NASA STI/Recon T ech- nical Report , vol. 93, 1993. [14] Kaldi toolkit for speech r ecognition . https://github .com/kaldi- asr/kaldi. [15] K. N. Stevens and S. E. Blumstein, “In v ariant cues for place of articulation in stop consonants, ” The Journal of the Acoustical So- ciety of America , vol. 64, no. 5, pp. 1358–1368, 1978. [16] S. E. Blumstein and K. N. Ste vens, “ Acoustic in variance in speech production: Evidence from measurements of the spectral charac- teristics of stop consonants, ” The J ournal of the Acoustical Society of America , vol. 66, no. 4, pp. 1001–1017, 1979.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment