UniParse: A universal graph-based parsing toolkit
This paper describes the design and use of the graph-based parsing framework and toolkit UniParse, released as an open-source python software package. UniParse as a framework novelly streamlines research prototyping, development and evaluation of graph-based dependency parsing architectures. UniParse does this by enabling highly efficient, sufficiently independent, easily readable, and easily extensible implementations for all dependency parser components. We distribute the toolkit with ready-made configurations as re-implementations of all current state-of-the-art first-order graph-based parsers, including even more efficient Cython implementations of both encoders and decoders, as well as the required specialised loss functions.
💡 Research Summary
**
The paper introduces UniParse, an open‑source Python toolkit designed to streamline research on graph‑based dependency parsing. The authors argue that existing parsers—both classic sparse‑feature models such as the MST parser (McDonald & Pereira, 2006) and modern neural architectures like Kiperwasser & Goldberg (2016) and Dozat & Manning (2017)—are typically implemented as monolithic code bases where encoder, parameter, and decoder components are tightly coupled. This coupling hampers rapid prototyping, fair benchmarking, and reproducibility.
UniParse addresses these issues by defining a unified abstraction for graph‑based parsers: an encoder Γ, a parameter set λ, and a decoder h. In modern neural parsers the encoder and parameters are merged into a single trainable space, so the toolkit treats only λ (the full set of learnable parameters) and h (the decoding algorithm) as the essential components. This abstraction allows both sparse‑feature and neural parsers to be expressed through the same API.
The toolkit offers two levels of interaction. The high‑level API provides a wrapper class (e.g., CustomParser) that requires the user to specify only a decoder, loss function, optimizer, and batching strategy. With this interface, a full parser can be instantiated in a handful of lines of code, as demonstrated by the re‑implementation of Kiperwasser & Goldberg’s neural parser. The low‑level API exposes modular implementations of each component, enabling researchers to mix and match custom encoders, loss functions, or decoders without rewriting other parts of the system.
Key modules include:
- Vocabulary – parses CoNLL‑U files, builds token‑to‑ID maps, and aligns tokens with pre‑trained embeddings.
- DataProvider – organizes tokenized sentences into batches. It supports length‑based bucketing, fixed‑size padding, and approximate clustering‑based batching (as used in Dozat & Manning).
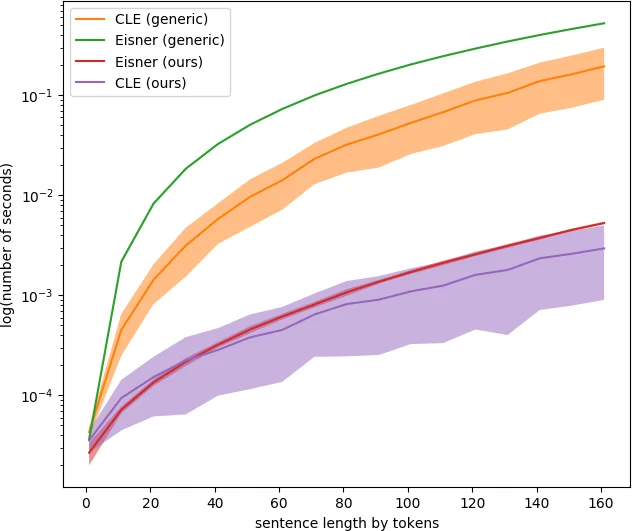
- Decoders – optimized Cython implementations of first‑order parsers: Eisner’s algorithm and Chu‑Liu‑Edmonds (CLE). Both Cython and pure‑Python versions are shipped for comparison. Benchmarks show the Cython versions are an order of magnitude faster (e.g., decoding an entire dataset in ~1.5 s versus >15 s for the generic Python versions).
- Evaluation – computes Unlabeled Attachment Score (UAS) and Labeled Attachment Score (LAS) with explicit handling of two common variations: (1) optional removal of punctuation arcs (punctuation defined by the Unicode standard) and (2) optional partial matching of composite labels (e.g., matching “obl” against “obl:tmod”). This explicitness eliminates hidden preprocessing differences that often invalidate cross‑paper comparisons.
- Loss Functions – for sparse‑feature parsers the toolkit implements direct loss computation based on Crammer & Singer’s online multiclass formulation. For neural parsers a generic loss interface accepts the score tensor, an optional predicted tree, and the gold tree, allowing researchers to experiment with hinge, cross‑entropy, or custom structured losses.
UniParse ships with three ready‑made configurations that reproduce state‑of‑the‑art first‑order parsers:
- MSTparser – a re‑implementation of the 2006 online learning MST parser (restricted to first‑order features).
- Kiperwasser & Goldberg (2016) – a BiLSTM‑based encoder with a simple MLP scorer and Eisner decoding.
- Dozat & Manning (2017) – a deep biaffine attention model with CLE decoding.
Experiments are conducted on English Penn Treebank (converted to dependencies) and on Universal Dependencies (English UD and Danish UD). Table 2 compares UniParse’s reproduced results with the original papers. The reproduced scores are virtually identical (differences within 0.2 % for UAS/LAS), confirming the correctness of the implementations. Neural parsers are evaluated over multiple runs (10 runs for Kiperwasser & Goldberg, 3 runs for Dozat & Manning) to report stable averages, while the MSTparser is reported from a single run.
The authors also demonstrate extensibility by integrating contextualized embeddings (ELMo) and Temporal Convolutional Network (TCN) representations, showing that swapping the encoder component requires only a few lines of code.
In conclusion, UniParse delivers a highly efficient, modular, and reproducible environment for graph‑based dependency parsing research. By unifying sparse‑feature and neural paradigms under a common terminology and providing both high‑level convenience and low‑level flexibility, it removes the engineering overhead that has traditionally slowed experimentation. The toolkit’s open‑source GPL license encourages community contributions, and its design paves the way for future extensions such as higher‑order parsers, multi‑task learning, or GPU‑accelerated decoding.
Comments & Academic Discussion
Loading comments...
Leave a Comment