Foreign English Accent Adjustment by Learning Phonetic Patterns
State-of-the-art automatic speech recognition (ASR) systems struggle with the lack of data for rare accents. For sufficiently large datasets, neural engines tend to outshine statistical models in most natural language processing problems. However, a speech accent remains a challenge for both approaches. Phonologists manually create general rules describing a speaker’s accent, but their results remain underutilized. In this paper, we propose a model that automatically retrieves phonological generalizations from a small dataset. This method leverages the difference in pronunciation between a particular dialect and General American English (GAE) and creates new accented samples of words. The proposed model is able to learn all generalizations that previously were manually obtained by phonologists. We use this statistical method to generate a million phonological variations of words from the CMU Pronouncing Dictionary and train a sequence-to-sequence RNN to recognize accented words with 59% accuracy.
💡 Research Summary
**
The paper tackles the persistent problem of accent variability in automatic speech recognition (ASR) by proposing a two‑stage pipeline that automatically extracts phonological generalizations from a modestly sized accented speech corpus, uses these generalizations to synthesize a massive set of accented pronunciations, and then trains a sequence‑to‑sequence (seq2seq) recurrent neural network (RNN) to map accented phoneme strings back to a standard General American English (GAE) representation.
Data collection and preprocessing
The authors start with the Speech Accent Archive (GMU) containing 2,511 audio recordings covering 239 ethnicity codes. Each recording is manually transcribed in the International Phonetic Alphabet (IPA). To make the data tractable for automatic processing, they create a “reduction dictionary” that maps the 169 unique IPA symbols found in the GMU set onto the 39 phonemes used by the CMU Pronouncing Dictionary. This reduction inevitably discards some fine‑grained phonetic detail but enables large‑scale statistical analysis.
Statistical model for phonological generalizations
For each of 69 representative words (the “Please call Stella” sentence), the authors compare the accented transcription with the corresponding GAE transcription. They record insertions, deletions, and substitutions at the phoneme level, building four dictionaries per phoneme: (1) total occurrences, (2) substitution counts, (3) insertion‑before/after counts, and (4) deletion counts. From these counts they compute probabilities such as “p → b @” or “e → I”. The model therefore captures the likelihood that a given sound will be altered in a particular way across the corpus. The authors demonstrate that the statistical model can recover 13 out of 20 manually curated phonological rules when operating on the simplified 39‑phoneme representation, and all 20 rules when using the full IPA set.
Synthetic accent generation
Using the learned probabilities, the authors generate new accented versions of every entry in the CMU dictionary. For each of the ~100,000 words they produce multiple variants, ultimately creating roughly one million (accented, standard) pairs. The generated data is heavily biased toward a Russian‑accent pattern because the original GMU subset used for training the statistical model is dominated by Russian speakers, but the methodology is agnostic to language and could be applied to any accent for which a small seed corpus exists.
Seq2seq RNN for accent modification
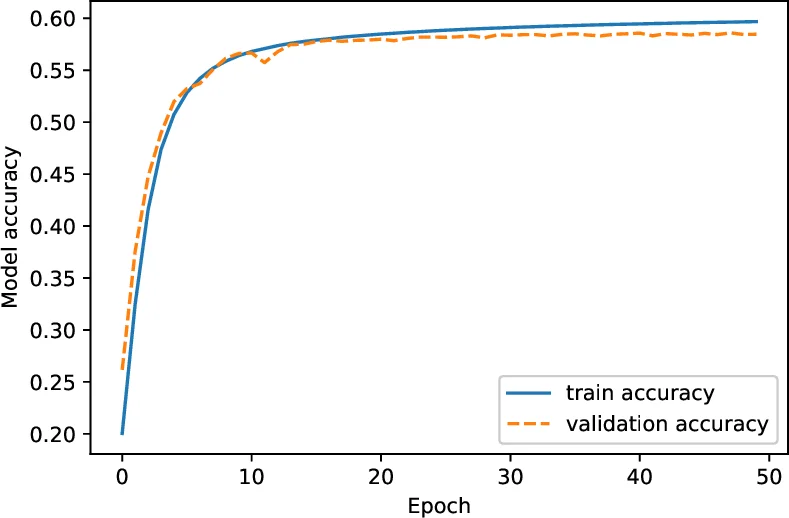
The generated dataset serves as training material for a character‑level seq2seq model (encoder‑decoder) built from two LSTM layers of 256 units each. The encoder consumes the accented phoneme sequence; the decoder is trained to emit the corresponding GAE phoneme sequence. Training uses RMSProp, a batch size of 4096, and runs for 100 epochs. The dataset is split 80/10/10 into train/validation/test sets. Training accuracy climbs to ~85 % but plateaus after epoch 25, while validation accuracy stops improving, indicating over‑fitting. On the held‑out test set the model reaches 0.593 (59 %) word‑level accuracy.
Analysis of results and limitations
The authors attribute the modest performance to several factors: (a) the synthetic accented data contain many variations that do not correspond to natural speech, effectively acting as noise; (b) the reduction to 39 phonemes loses subtle accent cues; (c) the training data are heavily skewed toward a single accent (Russian), limiting generalization to other dialects. Moreover, the LSTM‑based seq2seq architecture, while effective for spelling‑correction tasks, struggles to capture the probabilistic diversity of accent transformations without over‑fitting.
Future directions
The paper outlines several avenues for improvement: (1) collect larger, more diverse native‑accent corpora to reduce bias; (2) adopt a richer phoneme inventory (e.g., extended ARPAbet or full IPA) to preserve fine‑grained phonetic information; (3) replace the LSTM seq2seq model with more powerful architectures such as Transformers or Conformers, possibly leveraging pre‑training on massive speech corpora; (4) integrate the accent‑modification module directly into an end‑to‑end ASR pipeline so that acoustic and language models can jointly benefit from accent normalization.
In summary, the work demonstrates that phonological generalizations can be automatically learned from a small accented dataset and used to synthesize large‑scale training material, enabling a neural model to perform accent‑to‑standard conversion. While the achieved 59 % accuracy shows that the approach is viable, substantial enhancements in data diversity, phonetic granularity, and model architecture are required before the technique can be deployed in real‑world ASR systems to reliably handle rare or under‑represented English accents.
Comments & Academic Discussion
Loading comments...
Leave a Comment