Singing Style Transfer Using Cycle-Consistent Boundary Equilibrium Generative Adversarial Networks
Can we make a famous rap singer like Eminem sing whatever our favorite song? Singing style transfer attempts to make this possible, by replacing the vocal of a song from the source singer to the target singer. This paper presents a method that learns…
Authors: Cheng-Wei Wu, Jen-Yu Liu, Yi-Hsuan Yang
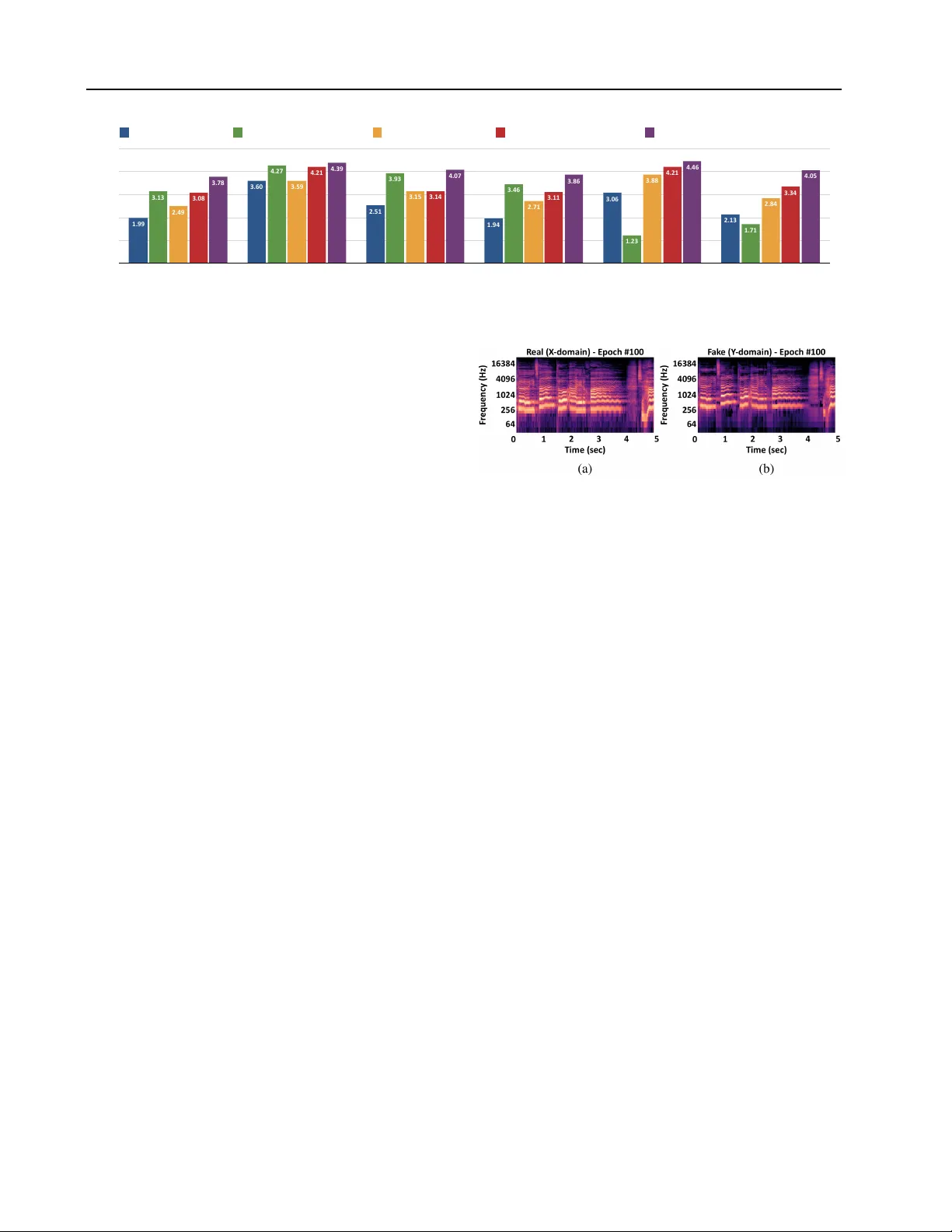
Singing Style T ransfer Using Cycle-Consistent Boundary Equilibrium Generativ e Adversarial Netw orks Cheng-W ei W u 1 2 Jen-Y u Liu 1 2 Y i-Hsuan Y ang 2 Jyh-Shing R. Jang 1 Abstract Can we make a famous rap singer like Eminem sing whatever our fav orite song? Singing style transfer attempts to make this possible, by replac- ing the v ocal of a song from the source singer to the target singer . This paper presents a method that learns from unpaired data for singing style transfer using generativ e adversarial networks. 1. Introduction Figure 1 sho ws a two-stage frame work combining singing voice separation with singing style transfer . The audio from a sour ce singer is separated into accompaniment and vocal first, and then the singing style of the separated vocal is changed to that of a target singer . Finally , the separated accompaniment is integrated with the style-transferred v ocal. Our focus here is on the singing style transfer model. W e assume that the input to this model is clean, meaning that it has been perfectly separated from the source audio. W e e valuate the proposed model through a listening test under the inside test scenario, meaning that the training and test sets ha ve o verlaps. W e show audio result for both inside and outside tests on our project website: http:// mirlab.org/users/haley.wu/cybegan/ . 2. Methodology The method proposed by Gatys et al. ( 2016 ) leads to the earliest successful examples of image style transfer . The method has been e xtended to perform audio style transfer , either to transfer sound texture ( Ulyanov & Lebede v , 2016 ) or to stylize an acapella cov er to match the original vocal ( Bohan , 2017 ). Howe ver , the method requires the av ailabil- ity of paired data for training (i.e., the source and target singers need to have sung the same songs), which is not readily av ailable for arbitrary target singers. 1 National T aiwan Uni versity; 2 Academia Sinica, T aiwan;. Cor- respondence to: Cheng-W ei W u < haley .wu@mirlab .org > . Pr oceedings of the 35 th International Confer ence on Machine Learning , Stockholm, Sweden, PMLR 80, 2018. Cop yright 2018 by the author(s). Figure 1. System framework for singing style transfer . In this paper, we propose to use a CycleGAN-CNN ( Zhu et al. , 2017 ) based model due to its success in image style transfer without using paired data. W e use log-magnitude spectrogram as the model input, with 1,024-sample, 1/4 ov erlapping windows for the STFT for songs sampled at 44.1kHz. T o capture information in the spectra, we vie w a T × F 2D spectrogram as a T × 1 image with F channels, and use 1D con volution ( Liu & Y ang , 2018 ) for all the layers in our model. Since a song may ha ve variable length, we adopt a fully-con volutional design ( Long et al. , 2015 ; Liu & Y ang , 2016 ) and use no pooling layers. T o get the time- domain audio signal from the modified spectrogram, we use the classic Griffin-Lim algorithm ( 1984 ). W e experiment with a few extensions of this basic model. First, we use a U-Net architecture ( Ronneber ger et al. , 2015 ) and add symmetric skip connections between the encod- ing and decoding layers to preserve the details of the gi ven source audio and to increase the sharpness of the vocal. Second, we use BEGAN ( Berthelot et al. , 2017 ) instead of GAN in an attempt to stabilize the training process. More- ov er , in this CycleBEGAN design, we replace the original PatchGAN-based discriminator ( Li & W and , 2016 ; Ledig et al. , 2017 ; Isola et al. , 2017 ) with an auto-encoder hav- ing identical architecture with the generator . Finally , being inspired by ( Liu & Y ang , 2018 ), we add a r ecurrent layer (using GR U ( Cho et al. , 2014 )) before the output con volu- tion layer to account for the temporal dependency in music. 3. Experiments W e train our model on the iKala dataset ( Chan et al. , 2015 ), which comes with 252 30-second excerpts of clean vocal recordings. W e cut the excerpts into 5-second clips, with 4- second ov erlaps. W e randomly select 2,800 segments from each gender as the training set, and 100 segments from each gender as the test set. As part of each test clip may hav e been observed in the training set, this is an inside test. Singing Style T ransfer Using Cycle-Consistent Boundary Equilibrium Generative Adv ersarial Networks Mean%Opinion%Score%(MOS) 0 1 2 3 4 5 Sharpness Ly r i c s Pitch Naturalness Gender Overall 4.05 4.46 3.86 4.07 4.39 3.78 3.34 4.21 3.11 3.14 4.21 3.08 2.84 3.88 2.71 3.15 3.59 2.49 1.71 1.23 3.46 3.93 4.27 3.13 2.13 3.06 1.94 2.51 3.60 1.99 CycleGAN%-%CNN%(m1) CycleGAN%-%CNN%+%skip%(m2) CycleBEGAN%-%CNN%(m3) CycleBEGAN%-%CNN%+%skip%(m4) CycleBEGAN%-%CNN%+%skip%+%recurr ent%(m5) Figure 2. Results of subjective listening test: mean opinion scores (MOS) in six performance metrics. T o simplify the problem, we train our model to perform “gender transfer”, i.e., either male-to-female or female-to- male. W e implement and compare in total fi ve differ - ent models (denoted as m1–m5 in Figure 2 ), including the basic ‘CycleGAN-CNN’ and the most sophisticated ‘CycleBEGAN-CNN+skip+recurrent. ’ W e conduct a subjecti ve listening test to e valuate the perfor - mance of style transfer . The subjects are asked to listen to the source and transferred audio for six 15-second clips, in- cluding 3 clips for male-to-female and 3 clips for female-to- male. A subject has to compare the result of two randomly chosen models for each set, and e valuate the results in terms of the follo wing six metrics, using a fiv e-point Likert scale: • The sharpness of the transferred singing voice. • Whether the lyrics (main content of the song) is intelligible and is consistent with that in the source. • The percei ved pitch accuracy (relati ve pitch) of the transferred singing voice. • Naturalness : whether the transferred singing voice is generated by human not by machine. • Whether the gender of the singer has been changed. • Overall : whether the transferred v oice achie ve the goal of style transfer and its overall perceptual quality . Figure 2 shows the mean opinion scores (MOS) in these six metrics from 69 adults (19 females). The follo wing observations are made. First, in terms of sharpness and lyrics , all the models with symmetric skip connections (m2, m4, m5) outperform those without them (m1, m3). This shows that the audio details propagated via the skip connections from the encoder to the decoder help gener- ate high-resolution audio. Second, in terms of pitch , the CycleBEGANs (m3, m4, m5) outperform the simple Cy- cleGAN model (m1), but not the CycleGAN with skip con- nections (m2). By listening to the result, we found that m2 works like a normal auto-encoder which only reconstructs the input without transferring the style. Therefore, it pre- serves the pitch well but performs very poorly in gender . Figure 3. The spectrograms of the (a) source audio sung by a male singer and the (b) style transferred audio (male-to-female) of an example song, using CycleBEGAN-CNN+skip+recurrent (m5). W e can see that the pitches in (b) are higher than those in (a). Next, in terms of naturalness , the outputs of the mod- els with skip connections (m2, m4, m5) score higher than the others (m1, m3) as expected. Similar to pitch , the outputs of m2 sound more natural than the outputs from the other models, except for m5. Finally , the scores in gender is consistent with the result of the overall performance. This is expected, because the goal is to transfer the singing style male → female or female → male. CycleBEGAN mod- els (m3, m4, m5) again outperform the CycleGAN ones (m1, m2), which verifies that the the inte gration of CycleGAN with BEGAN ef fecti vely impro ves the result of style trans- fer . The most sophisticated model m5 outperforms the other models in all the metrics, reaching scores that are close to or over 4 on the fi ve-point Lik ert scale. Figure 3 shows an example of the transfered spectrograms by m5. 4. Conclusion and Future W ork W e ha ve proposed a ne w approach for singing style transfer without paired data by combining CycleGAN with the train- ing strate gy of BEGAN. W e ha ve sho wn that symmetric skip connections increase the sharpness of the result, and that BEGAN plays an important role in transferring the singer properties. Future work will be done to transfer singer iden- tities instead of only gender , and to include a singing voice separation model ( Jansson et al. , 2017 ; Liu & Y ang , 2018 ) to deal with real songs instead of clean vocals. Singing Style T ransfer Using Cycle-Consistent Boundary Equilibrium Generative Adv ersarial Networks References Berthelot, David, Schumm, T om, and Metz, Luke. BEGAN: Boundary equilibrium generativ e adversarial netw orks. arXiv pr eprint arXiv:1703.10717 , 2017. Bohan, O. B. Singing style transfer , 2017. URL http://madebyoll.in/posts/singing_ style_transfer/ . Chan, T ak-Shing, Y eh, Tzu-Chun, F an, Zhe-Cheng, Chen, Hung-W ei, Su, Li, Y ang, Y i-Hsuan, and Jang, Roger . V ocal acti vity informed singing v oice separation with the ikala dataset. In Pr oc. IEEE. Int. Conf. Acoustics, Speech and Signal Pr ocessing , pp. 718–722, 2015. Cho, K yunghyun, v an Merri ¨ enboer , Bart, G ¨ ul c ¸ ehre, C ¸ alar , Bahdanau, Dzmitry , Bougares, Fethi, Schwenk, Holger , and Bengio, Y oshua. Learning phrase representations using rnn encoder–decoder for statistical machine trans- lation. In Pr oc. Conf. Empirical Methods in Natural Language Pr ocessing , pp. 1724–1734, 2014. Gatys, L. A., Ecker , A. S., and Bethge, M. Image style transfer using con volutional neural networks. In Pr oc. IEEE Conf. Computer V ision and P attern Recognition , pp. 2414–2423, 2016. Griffin, Daniel and Lim, Jae. Signal estimation from modi- fied short-time fourier transform. IEEE T ransactions on Acoustics, Speech, and Signal Pr ocessing , 32(2):236–243, 1984. Isola, Phillip, Zhu, Jun-Y an, Zhou, Tinghui, and Efros, Alex ei A. Image-to-image translation with conditional adversarial networks. In Proc. IEEE Conf. Computer V ision and P attern Recognition , 2017. Jansson, Andreas, Humphrey , Eric J., Montecchio, Nicola, Bittner , Rachel, Kumar , Aparna, and W eyde, T illman. Singing voice separation with deep U-net con volutional networks. In Pr oc. Int. Soc. Music Information Retrieval Conf. , pp. 745–751, 2017. Ledig, Christian, Theis, Lucas, Huszar , Ferenc, Caballero, Jose, Cunningham, Andre w , Acosta, Alejandro, Aitk en, Andrew , T ejani, Alykhan, T otz, Johannes, W ang, Zehan, et al. Photo-realistic single image super-resolution us- ing a generati ve adv ersarial network. In Pr oceedings of the IEEE Conference on Computer V ision and P attern Recognition , pp. 4681–4690, 2017. Li, Chuan and W and, Michael. Precomputed real-time texture synthesis with mark ovian generati ve adversarial networks. In Pr oc. European Conf. Computer V ision , pp. 702–716. Springer , 2016. Liu, Jen-Y u and Y ang, Y i-Hsuan. Ev ent localization in music auto-tagging. In Pr oc. ACM Multimedia , pp. 1048– 1057, 2016. Liu, Jen-Y u and Y ang, Y i-Hsuan. Denoising auto-encoder with recurrent skip connections and residual regres- sion for music source separation. arXiv pr eprint arXiv:1807.01898 , 2018. Long, Jonathan, Shelhamer , Ev an, and Darrell, T re v or . Fully con v olutional networks for semantic segmentation. In Pr oc. IEEE Int. Conf. Computer V ision and P attern Recog- nition , pp. 3431–3440, 2015. Ronneberger , Olaf, Fischer, Philipp, and Brox, Thomas. U-net: Conv olutional networks for biomedical image segmentation. In Pr oc. Int. Conf. Medical Image Com- puting and Computer-assisted Intervention , pp. 234–241. Springer , 2015. Ulyanov , D. and Lebedev , V . Singing style transfer, 2016. URL https://dmitryulyanov.github.io/ audio- texture- synthesis- and- style- transfer/ . Zhu, Jun-Y an, Park, T aesung, Isola, Phillip, and Efros, Alex ei A. Unpaired image-to-image translation using cycle-consistent adversarial networkss. In Pr oc. IEEE Int. Conf. Computer V ision , 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment