Improving Decision Analytics with Deep Learning: The Case of Financial Disclosures
Decision analytics commonly focuses on the text mining of financial news sources in order to provide managerial decision support and to predict stock market movements. Existing predictive frameworks almost exclusively apply traditional machine learni…
Authors: Stefan Feuerriegel, Ralph Fehrer
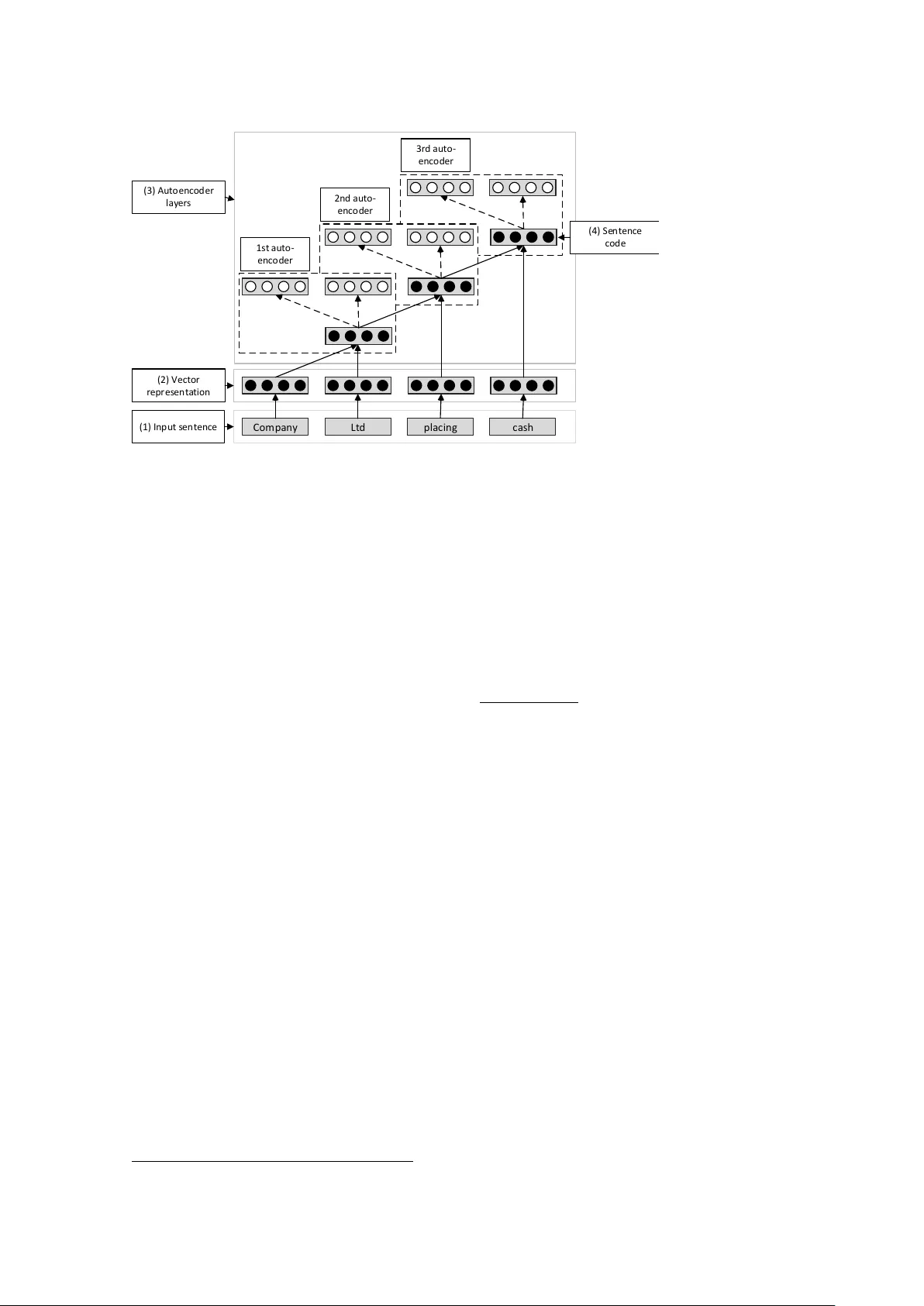
I M P RO V I N G D E C I S I O N A NA L Y T I C S W I T H D E E P L E A R N I N G : T H E CA S E O F F I NA N C I A L D I S C L O S U R E S Resear ch in Pr ogr ess Feuerriegel, Stefan, Uni versity of Freibur g, Freibur g, Germany , stefan.feuerrie gel@is.uni-freibur g.de Fehrer , Ralph, Uni versity of Freibur g, Freibur g, Germany , ralphfehrer@gmail.com Abstract Decision analytics commonly focuses on the text mining of financial ne ws sour ces in or der to pr ovide managerial decision support and to pr edict stock market movements. Existing pr edictive frameworks almost e xclusively apply traditional machine learning methods, wher eas r ecent resear ch indicates that these methods ar e not suf ficiently capable of e xtracting suitable featur es and capturing the non-linear natur e of complex tasks. As a r emedy , novel deep learning models aim to over come this issue by extending classical neural networks with additional hidden layer s. Indeed, deep learning often pr ovides a viable appr oach to achie ve a high predictive performance. In this paper , we adapt the novel deep learning technique to financial decision support, wher e we aim to pr edict the dir ection of stock movements following financial disclosures. As a result, our paper shows how deep learning can outperform the accuracy of benc hmarks for machine learning by 5.66 %. K eywor ds: Decision Analytics, IS Resear ch Methodologies, F inancial Pr ediction, Data Mining, Business Intelligence (BI), T e xt Mining, Information Pr ocessing. 1 Intr oduction Org anizations are constantly looking for ways to impro ve their decision-making processes in core areas, such as marketing, firm communication, production and procurement (T urban, 2011). While the classical approach relies on having humans devise simple decision-making rules, modern decision support can also exploit statistical e vidence that originates from analyzing data (Apte, Liu, Pednault, and Smyth, 2002; Arnott and Pervan, 2005; Asadi Someh and Shanks, 2015; Boylan and Syntetos, 2012; Da venport, 2006; V izecky, 2011). This data-driv en decision support is no wadays also fueled by the Big Data era (Boyd and Crawford, 2012; Chen, Chiang, and Storey, 2012; Halper, 2011; Po wer, 2014). The term Big Data usually refers to data that is massi ve in size. In addition, such data comes often in dif ferent formats (e. g. video, text), changes quickly and is subject to uncertainty (IBM, 2013). Crucial aspects of data-driv en decision support systems entail the prediction of future events, such as consumer beha vior or stock market reactions to press releases, based on an analysis of historical data (Apte, Liu, Pednault, and Smyth, 2002; V izecky, 2011). Decision analytics thus frequently utilizes modeling, machine learning and data mining techniques from the area of pr edictive analytics . In fact, predicti ve analytics can be instrumented for “generating new theory , de veloping new measur es, comparing competing theories, impr oving existing theories, assessing the r elevance of theories, and assessing the pr edictability of empirical phenomena” (Shmueli and K oppius, 2011). Predicti ve analytics frequently contributes to managerial decision support, as is the case when predicting in vestor reaction to press releases and financial disclosures (Nassirtoussi, Aghabozor gi, W ah, and Ngo, 2014). In this instance, predictiv e analytics is typically confronted with massive datasets of heterogeneous and mostly te xtual content, while outcomes are simultaneously of high impact for any business. Until T wenty-F ourth European Confer ence on Information Systems, Istanbul, T urkey , 2016 1 F euerrieg el and F ehr er / Deep Learning for F inancial Disclosures no w , decision support for financial news still predominantly relies on traditional machine learning techniques, such as support v ector machines or decision trees (Minev, Schommer, and Grammatikos, 2012; Nassirtoussi, Aghabozorgi, W ah, and Ngo, 2014; Pang and Lee, 2008). The performance of traditional machine learning algorithms lar gely depends on the features extracted from underlying data sources, which has consequently elicited the dev elopment and ev aluation of feature engineering techniques (Arel, Rose, and Karno wski, 2010). Research ef forts to automate and optimize the feature engineering process, along with a growing aw areness of current neurological research, has led to the emer gence of a new sub-field of machine learning research called deep learning (Hinton and Salakhutdinov, 2006). Deep learning tak es into account recent knowledge on the w ay the human brain processes data and thus enhances traditional neural networks by a series of hidden layers. This series of hidden layers allo ws for deeper knowledge representation, possibly resulting in impro ved predicti ve performance. Deep learning methods ha ve been applied to well-kno wn challenges in the machine learning discipline, such as pattern recognition and natural language processing. The corresponding results indicate that deep learning can outperform classical machine learning methods (which embody only a shallow kno wledge layer) in terms of accuracy (c. f. Hinton and Salakhutdinov, 2006; Socher, Pennington, Huang, Ng, and Manning, 2011). In this paper , we w ant to unleash the predicti ve power of deep learning to provide decision-support in the financial domain. As a common challenge, we choose the task of predicting stock market movements that follo w the release of a financial disclosure. W e expect that deep learning can learn appropriate features from the underlying textual corpus ef ficiently and thus surpass other state-of-the-art classifiers. Howe ver , the successful application of deep learning techniques is not an easy task; deep learning implicitly performs feature extraction through the interplay of dif ferent hidden layers, the representation of the textual input and the interactions between layers. In order to master this challenge, we apply the recursi ve autoencoder model introduced by Socher, Pennington, Huang, Ng, and Manning (2011) and tailor it to the prediction of stock price directions based on the content of financial materials. The remainder of this paper is structured as follows. Section 2 pro vides a short overvie w of related work in which we discuss similar te xt mining approaches and giv e an overvie w of relev ant deep learning publications. W e then explain our methodology and highlight the differences between classical and deep learning approaches (Section 3). Finally , Section 4 ev aluates both approaches using financial ne ws disclosures and discuss the managerial implications. 2 Related W ork This Information Systems research is positioned at the intersection between finance, Big Data, decision support and predicti ve analytics. The first part of this section discusses traditional approaches of providing decision support based on financial ne ws. In the second part, we discuss pre vious work that focuses on the nov el deep learning approach. 2.1 Decision analytics f or financial news T ext mining of financial disclosures represents one of the fundamental approaches for decision analytics in the finance domain. The av ailable work can be categorized by the necessary pr epr ocessing steps, the text mining algorithms , the underlying text sour ce (e. g. press releases, financial ne ws, tweets) and its focus on facts or opinions (e. g. quarterly reports, analyst recommendations). While Pang and Lee (2008) provide a comprehensi ve domain-independent surve y , other ov erviews concentrate solely on the financial domain (Mine v, Schommer, and Grammatikos, 2012; Mittermayer and Knolmayer, 2006). In a very recent surv ey , Nassirtoussi, Aghabozor gi, W ah, and Ngo (2014) focus specifically on studies aimed at stock market prediction. W e structure the discussion of the related research according to the above cate gories. Among the most popular text mining algorithms are classical machine learning algorithms, such as support vector machines, re gression algorithms, decision trees and Naïve Bayes. In addition, neural T wenty-F ourth European Confer ence on Information Systems, Istanbul, T urkey , 2016 2 F euerrieg el and F ehr er / Deep Learning for F inancial Disclosures network models ha ve been used more rarely , but are slo wly gaining traction, just as in other application domains (Nassirtoussi, Aghabozorgi, W ah, and Ngo, 2014). Furthermore, Bayesian learning can provide explanatory insights by generating domain-dependent dictionaries (Pröllochs, Feuerriegel, and Neumann, 2015). As part of pr epr ocessing , the first step in most text mining approaches is the generation of a set of v alues that represent rele vant textual features, which can be used as inputs for the subsequent mining algorithms. This usually in volv es the selection of features based on the ra w text sources, some kind of dimensionality reduction and the generation of a good feature representation, such as binary v ectors. A comprehensiv e discussion of the various techniques used for feature engineering can be found in Nassirtoussi, Aghabozorgi, W ah, and Ngo (2014) and Pang and Lee (2008). The text sour ces used for text mining include financial news (e. g. Alfano, Feuerriegel, and Neumann, 2015; Feuerriegel, W olf f, and Neumann, 2015, 2016; Feuerriegel and Neumann, 2013) and compan y-specific disclosures, and range from the less formal, such as tweets (e. g. Bollen, Mao, and Zeng, 2011), to more formal texts, such as corporate filings (e. g. Feuerriegel, Ratku, and Neumann, 2016; Muntermann and Guettler, 2007; Pröllochs, Feuerriegel, and Neumann, 2015). Some researchers hav e focused exclusiv ely on the headlines of news sources to e xclude the noise usually contained in longer texts (Peramunetilleke and W ong, 2002). Ne ws disclosures with a fact-based focus are especially rele vant for in vestors. As such, German ad hoc announcements in English contain strictly regulated content and a tight logical connection to the stock price, making them an intriguing application in research. The measurable ef fect of ad hoc news on abnormal returns on the day of an announcement ha ve been established by se veral authors (c. f. Groth and Muntermann, 2011; Hagenau, Liebmann, and Neumann, 2013; Muntermann and Guettler, 2007; Pröllochs, Feuerriegel, and Neumann, 2015). Consequently , we utilize the same corpus in our follo wing e valuation. 2.2 Deep learning as an emerging trend Deep learning 1 originally focused on comple x tasks, in which datasets are usually high-dimensional (Arel, Rose, and Karno wski, 2010; Bengio, 2009). As such, one of the first successful deep learning architectures consisted of a so-called autoencoder in combination with a Boltzmann machine, where the autoencoder carries out unsupervised pre-training of the network weights (Hinton and Salakhutdinov, 2006). This model performs well on sev eral benchmarks from the machine learning literature, such as image recognition. Moreover , its architecture can be adapted to enhance momentum stock trading (T akeuchi and Y u Y ing, 2013) as one of the fe w successful applications of deep learning to financial decision support. Ho wever , this publication relies only on past stock returns and ne glects the predictive po wer of exogenous input, such as financial disclosures. The natural language processing community has only recently started to adapt deep learning principles to the specific requirements of language recognition tasks. F or example, Socher, Pennington, Huang, Ng, and Manning (2011) utilize a recursi ve autoencoder to predict sentiment labels based on indi vidual movie re view sentences. Further research improv ed the results on the same dataset by combining a recursive neural tensor network with a sentiment treebank (Socher et al., 2013). 3 Methodologies f or Financial Decision Suppor t This section introduces our research frame work to provide financial decision support based on ne ws disclosures. In bre vity , we introduce a benchmark classifier and our deep learning architecture to predict stock movements. Altogether , Figure 1 illustrates how we compare both prediction algorithms. The random forest and the recursi ve autoencoder are both trained to predict stock market directions based 1 For details, see reading list “Deep Learning” . Retriev ed April 21, 2015 from http://deeplearning.net/reading- list/ . T wenty-F ourth European Confer ence on Information Systems, Istanbul, T urkey , 2016 3 F euerrieg el and F ehr er / Deep Learning for F inancial Disclosures F e a tu r e s el ec ti o n N e w s c o r p u s W o r d t o ke n s ( n u m b e r s a n d p u n c t u a t i o n r e m o ve d ) S t o c k m a r ke t d a t a D a t a s e t T e r m - d o c u m e n t m a t r i x ( tf - i d f ) R e p r e s e n ta ti o n S p a r s e e n t r i e s r e m o va l D i m . r ed u c ti o n C l a s s i f i c a ti o n C o m p a r i s o n A c c u r a c y Re c a l l P r e c i s i o n F 1 - S c o r e R a n d o m f o r e s t ( b e n c h m a r k ) N - g r a m s ( i m p l i c i t e l y o p t i m i z e d ) N u m e r i c a l ve c t o r s A u t o e n c o d e r ( i m p l i c i t e l y o p t i m i z e d ) L o g i s t i c r e g r e s s i o n F e a tu r e s e l e c ti o n D a ta R e c u r s i v e a u t o e n c o d e r h e a d l i n e s A b n o r m a l r e t u r n s F igur e 1. Resear ch frame work comparing classical machine learning and deep learning. on the ad hoc announcements and the according abnormal returns. T o compare the performance of the recursi ve autoencoder to the benchmark, we apply the same test set to each of the trained algorithms and measure the predictiv e performance in terms of accuracy , precision and recall based on the confusion matrix. Follo wing Nassirtoussi, Aghabozorgi, W ah, and Ngo (2014), we di vide the ov erall procedure into steps for data generation, feature selection, feature reduction and feature representation. Both approaches, the benchmark algorithm and the recursi ve autoencoder , differ fundamentally in their preprocessing. The application of a random forest or support vector machine requires traditional feature engineering, whereas the recursi ve autoencoder , as a remedy , automatically generates a feature representation as part of its optimization algorithm. This is indicated in Figure 1 by the e xtension of the recursiv e autoencoder box ov er all preprocessing steps. 3.1 Benchmark: predicting stoc k movements with random f orests In a first step, one transforms the running te xt into a matrix representation, which subsequently works as the input to the actual random forest algorithm. First of all, we remov e numbers, punctuations and stop words from the running te xt and then split it into tok ens (Manning and Schütze, 1999). Afterwards, we count the frequencies of ho w often terms occur in each news disclosure, remov e sparse entries to reduce the dimensionality and store these values in a document-term matrix. The document-term matrix then represents the features. The actual v alues are weighted (Salton, Fox, and W u, 1983) by the term fr equency-in verse document fr equency (tf-idf). This is a common approach in information retriev al to adjust the word frequencies by their importance. In the following e valuation, we utilize random forests as a benchmark classifier . Random forests represent one of the most popular machine learning algorithms due to their fa vorable predicti ve accuracy , relativ ely lo w computational requirements and rob ustness (Breiman, 2001; Hastie, T ibshirani, and Friedman, 2009; Kuhn and Johnson, 2013). Random forests are an ensemble learning method for classification and regression, which is based on the construction and combination of man y de-correlated decision trees. Gi ven a training set X = { x x x 1 , . . . , x x x N } with associated responses Y = { y 1 , . . . , y N } , the algorithm repeats the follo wing steps B times (we choose B = 500 ): (1) sample with replacement from X and Y to generate ne w subsets X 0 and Y 0 . (2) T rain a decision tree t b using X 0 and Y 0 . The indi vidual decision trees t b , b = 1 , . . . , B can be combined to predict a response ˆ y for unseen values x x x as follo ws. One calculates indi vidual predictions t b ( x x x ) for b = 1 , . . . , B from each tree and then aggregates these predictions by simply using the majority vote to get the final response. T wenty-F ourth European Confer ence on Information Systems, Istanbul, T urkey , 2016 4 F euerrieg el and F ehr er / Deep Learning for F inancial Disclosures x y z f f R e c o n s t r u c t i o n l a y er I n p u t l a y er C o d e l a y er F igur e 2. An autoencoder sear ches a mapping between input x x x and a lower-dimensional r epr esentation y y y such that the r econstructed value z z z is similar to the input x x x. 3.2 Deep learning arc hitecture: recursive autoencoders This section describes the underlying architecture of our deep learning approach for financial disclosures based on so-called autoencoders . The architecture of an autoencoder is illustrated in Figure 2. An autoencoder is basically an artificial neural network, which finds a lo wer-dimensional representation of input v alues. Let x x x ∈ [ 0 , 1 ] N denote our input v ector , for which we seek a lo wer-dimensional representation y y y ∈ [ 0 , 1 ] M with M < N . The mapping f between x x x and y y y is named encoding function and can be, generally speaking, any non-linear function, although a common choice is the sigmoid function f ( x x x ) = σ ( W x x x + b b b ) = 1 1 + e xp ( W x x x + b b b ) = y y y with parameters W and b b b . (1) The ke y idea of an autoencoder is to find a second mapping from y y y to z z z ∈ [ 0 , 1 ] N gi ven by f 0 ( y y y ) = σ ( W 0 y y y + b b b 0 0 0 ) , such that z z z is almost equal to the input x x x . Mathematically speaking, we choose the free parameters in f and f 0 by minimizing the difference between the original input vector x x x and the reconstructed vector z z z . This can be ef fectiv ely achie ved using numerical optimization, such as gradient descent, in order to determine the weights W and W 0 . Altogether , the representation y y y (often called code ) is a lo wer- dimensional representation of the input data; it is frequently used as input features for subsequent learning because it only contains the most rele vant or most discriminating features of the input space. The classical autoencoder works merely with a simple vector as input. In order to incorporate contextual information, we extend the classical autoencoder , resulting in a so-called r ecursive autoencoder . Here, one trains a sequence of autoencoders, where each not only takes a v ector x x x as input but also recursi vely the lo wer-dimensional code of the pre vious autoencoder in the sequence. Let us demonstrate this approach with an example as illustrated in Figure 3. W e process input in the form of a sequence of words. Each word is e. g. gi ven by a binary vector with zeros e xcept for a single entry with 1 representing the current word. Then, we train the first autoencoder with the input from the first two words Company and Ltd . Its lo wer-dimensional code is then input to the second autoencoder together with the vector representation of the word placing . This recursion proceeds up to the final autoencoder , which produces as output the code representation for the complete sentence. Hence, this recursi ve approach aims to generate a compact code representation of a complete sentence while incorporating contextual information in the code layer . More precisely , this approach can learn from an ordered sequence of words and not only the pure frequencies. In addition, the recursiv e autoencoder entails an intriguing advantage: it can compress large input v ectors in an unsupervised fashion without the need for class labels. The basic steps for the recursiv e autoencoder are as follows: in a first step, the individual words of an input sentence (1) are mapped onto vectors of equal length l (2). W e initialize the values of the weights by sampling from a Gaussian distribution and later continuously updated through backpropagation. Through a recursi ve application of the autoencoder algorithm (3), the complete input sentence is then compressed bit by bit into a single code representation of length l (4). For this purpose, the first autoencoder generates a code representation of length l from the v ectors representing the first two w ords in the sentence. The T wenty-F ourth European Confer ence on Information Systems, Istanbul, T urkey , 2016 5 F euerrieg el and F ehr er / Deep Learning for F inancial Disclosures C o m p a n y L t d p la c in g c a s h ( 1 ) In p u t s en ten c e ( 2 ) V e c to r r e p r e s e n ta ti o n ( 4 ) S e n ten c e c o d e 1 s t a u to - en c o d er 2 n d a u to - e n c o d e r 3 r d a u to - en c o d er ( 3 ) A u to e n c o d e r l a y er s F igur e 3. A r ecursive autoencoder is a sequence of autoencoder s, where eac h not only takes a vector as input but also the lower -dimensional code of the pr evious autoencoder in the sequence. second autoencoder takes this code representation and the third word v ector as inputs, and calculates the code representation of the next le vel. In order to extract and predict sentiment v alues, we use an extended variant of the recursi ve autoencoder model (Socher, Pennington, Huang, Ng, and Manning, 2011), which includes an additional softmax layer (sometimes also referred to as multinomial logit) in each autoencoder . This softmax function estimates the probability that an input vector x x x belongs to a certain class j ∈ K via P ( y = j | x x x ) = exp x x x T W j K ∑ k = 1 exp ( x x x T W k ) . (2) In order to train this model, we optimize the weights W k of both the autoencoders and the softmax layers simultaneously with a combined target function. W e then utilize the trained weights to classify unkno wn sentences by first computing the code representation inside the recursi ve autoencoder and, second, calculating the probabilities for each class from the softmax function. Interestingly , the backward mapping f 0 is needed for training but is no longer needed for the prediction (that is why black circles indicate the vectors only necessary for prediction in Figure 2 and Figure 3). 4 Ev aluation: Predicting Stock Market Direction fr om Financial News In this section, we discuss and e valuate our experimental setting for predicting the direction of stock market mo vements following financial disclosures. W e start with describing the steps in volv ed in the generation of the underlying dataset and then compare classical machine learning with our deep learning architecture. 4.1 Dataset Our news corpus originates from regulated ad hoc announcements 2 between January 2004 and the end of June 2011 in English. These announcements conform to German regulations that require each 2 Kindly provided by Deutsche Gesellschaft für Ad-Hoc-Publizität (DGAP). T wenty-F ourth European Confer ence on Information Systems, Istanbul, T urkey , 2016 6 F euerrieg el and F ehr er / Deep Learning for F inancial Disclosures listed company in German y to immediately publish any information with a potentially significant effect on the stock price. W ith their direct relation to a particular stock, the tightly controlled content and the measurable effect on the stock price on the day of the announcement, ad hoc announcements are particularly well-suited for the de velopment and ev aluation of techniques for predictiv e analytics. Since recursi ve autoencoders work on sentence tok ens, we exclusi vely use the headlines of English ad hoc announcements for the prediction and discard the message body . As pre vious work (e. g. Peramunetilleke and W ong, 2002) has sho wn, this is not a major disadv antage and can e ven help in reducing noise, as long as the titles concisely represent the content of the text. W e gather the financial data of the releasing companies from Thomson Reuters Datastream. W e retrie ve the firm performance with the help of the International Securities Identification Numbers (ISIN) that appear first in each of the ad hoc announcements. The stock price data before and on the day of the announcement are extracted using the corresponding trading day . These are then used to calculate abnormal returns (K onchitchki and O’Leary, 2011; MacKinlay, 1997; Pröllochs, Feuerrie gel, and Neumann, 2015); abnormal returns can be regarded as some kind of e xcess return caused by the news release. In addition, we remo ve penn y stocks with stock prices belo w $5 for noise reduction. W e then label each announcement title with one of three return direction classes ( up , down or steady ), according to the abnormal return of the corresponding stock on the announcement day and discard the steady samples for noise reduction. The resulting dataset consists of 8359 headlines from ad hoc announcements with corresponding class labels up or down . Of this complete dataset, we use the samples co vering the first 80 % of the timeline as training samples and the remaining 20 % as test samples. 3 4.2 Preliminary results W e can now apply the abov e methods for predictiv e analytics to provide decision support regarding ho w in vestors react upon te xtual news disclosures. By comparing random forests and recursi ve autoencoders, we can e valuate our hypothesis that deep learning outperforms our benchmark in the current setting. The detailed results are listed in T able 1. W e compare the predictiv e performance on the out-of-sample test set in terms of accuracy , precision, recall and the F1-score. The random forest as our benchmark achieves an in-sample accuracy of 0.63 and an out-of-sample accurac y of 0.53 at best. In comparison, the recursi ve autoencoder 4 as our deep learning architecture results in an accuracy of 0.56. This accounts for a relativ e improv ement of 5.66 %. Similarly , the F1-score increases from 0.52 to 0.56 – a substantial rise of 7.69 %. The higher accuracy , as well as the impro ved F1-score, of the recursive autoencoder underlines our initial assumption that deep learning algorithms can outperform our benchmark from classical machine learning. When comparing the necessary computational resources, we see that recursi ve autoencoders ( ≈ 23 min ) require less computation time than decision trees (more than 200 min ). 5 Moreov er , recursiv e autoencoders hav e an additional advantage: one can simply inject the complete set of ne ws headlines as input without the manual ef fort of feature engineering. The reason for this is that the calculation and optimization of a feature representation is integrated into the optimization routines of deep learning algorithms. The abo ve results comply with the reported figures of around 60 % with the full message body from related work (Groth and Muntermann, 2008; Hagenau, Liebmann, and Neumann, 2013). In direct comparison to the benchmarks, our e valuation provides evidence that deep learning is a compelling approach for the prediction of stock price mov ements. 3 W e av oid the use of k -fold cross-v alidation as this would neglect the timing of disclosures. For instance, we w ould e valuate our models with disclosures during the financial crisis, while the same models were previously trained with later kno wledge of how news were percei ved after the happening of the financial crisis. 4 W e systematically tried sev eral combinations for the two adjustable parameters embedding size (the length l of the mapped feature vectors) and number -of-iterations (i. e. number of gradient descent iterations). The best result accounts for an accuracy of 0.56 on the test-set, with a v ector embedding size of 40 and 70 iterations. As e xpected, increasing the number of iterations usually results in better accuracy on the training set and lo wer accuracy on the test set – a typical indication of ov er-fitting. 5 T imings measured on an Intel Core i7-4700MQ CPU running at 2.4 GHz with 8 GB RAM and 64-bit W indows 8.1. Please note that programming languages and matrix algebra libraries vary which mak es a fair comparison difficult. T wenty-F ourth European Confer ence on Information Systems, Istanbul, T urkey , 2016 7 F euerrieg el and F ehr er / Deep Learning for F inancial Disclosures Predicti ve Analytics Method Accuracy Precision Recall F1-Score Random Forest 0 . 53 0 . 53 0 . 51 0 . 52 Recursi ve Autoencoder 0 . 56 0 . 56 0 . 56 0 . 56 Relative Impr ovement 5 . 66 % 5 . 66 % 9 . 80 % 7 . 69 % T able 1. Pr eliminary r esults evaluating impr ovements by utilizing deep learning to pr edict the direction of stock price mo vements following financial disclosures. 4.3 Discussion and implications for practitioner s T raditional machine learning techniques still represent the def ault method of choice in predicti ve analytics. Ho wever , recent research indicates that these methods insuf ficiently capture the properties of comple x, non-linear problems. Accordingly , the experiments in this paper sho w that a deep learning algorithm is capable of implicitly generating a fa vorable kno wledge representation. As a recommendation to practitioners, better results are achiev able with deep learning than with classical methods that rely on explicitly generated features. Nev ertheless, practitioners must be aware of the complex architecture of deep learning models. This requires both a thorough understanding and solid experience in order to use such models ef ficiently . The economic impact of our improvement is manifold. A higher predictiv e performance enables business opportunities for automated traders. In addition, corporates can utilize this approach to assess the expected market response subsequent to disclosures. This w orks as a safety mechanism to check if the subjectiv e perception of in vestors matches the content of a release. 5 Conc lusion and Research Outlook In the present paper , we show ho w a novel deep learning algorithm can be applied to provide decision support for the financial domain. Thereby , we contrib ute to Information Systems research by shedding light on ho w to exploit deep learning as a recent trend for managerial decision support. W e demonstrate that a recursi ve autoencoder outperforms our benchmark from traditional machine learning in the prediction of stock market mo vements follo wing financial ne ws disclosures. The recursiv e autoencoder benefits from being able to automatically generate a deep kno wledge representation. In future research, we intend to broaden the preliminary results of this Research-in-Progress paper . First, our analysis could benefit substantially from incorporating and comparing further algorithms from predicti ve analytics. Second, we want to generalize our results by including further ne ws sources. References Alfano, S. J., S. Feuerriegel, and D. Neumann (2015). “Is News Sentiment More than Just Noise?” In: 23r d Eur opean Confer ence on Information Systems (ECIS 2015) . Apte, C., B. Liu, E. P . D. Pednault, and P . Smyth (2002). “Business Applications of Data Mining. ” Communications of the A CM 45 (8), 49–53. Arel, I., D. C. Rose, and T . P . Karno wski (2010). “Deep Machine Learning: A New Frontier in Artificial Intelligence Research. ” IEEE Computational Intelligence Magazine 5 (4), 13–18. U R L : http://web. eecs.utk.edu/~itamar/Papers/DML_Arel_2010.pdf (visited on 04/19/2015). Arnott, D. and G. Pervan (2005). “A Critical Analysis of Decision Support Systems Research. ” J ournal of Information T echnology 20 (2), 67–87. Asadi Someh, I. and G. Shanks (2015). “Ho w Business Analytics Systems Provide Benefits and Contribute to Firm Performance?” In: 23r d Eur opean Confer ence on Information Systems (ECIS 2015) . T wenty-F ourth European Confer ence on Information Systems, Istanbul, T urkey , 2016 8 F euerrieg el and F ehr er / Deep Learning for F inancial Disclosures Bengio, Y . (2009). Learning Deep Ar chitectur es for AI . U R L : http://www.iro.umontreal.ca/~lisa/ pointeurs/TR1312.pdf (visited on 08/10/2014). Bollen, J., H. Mao, and X. Zeng (2011). “T witter Mood Predicts the Stock Market. ” Journal of Computa- tional Science 2 (1), 1–8. Boyd, D. and K. Crawford (2012). “Criticial Questions for Big Data. ” Information, Communication & Society 15 (5), 662–679. Boylan, J. E. and A. A. Syntetos (2012). “F orecasting in Management Science. ” Ome ga 40 (6), 681. Breiman, L. (2001). “Random Forests. ” Machine Learning 45 (1), 5–32. Chen, H., R. H. L. Chiang, and V . C. Storey (2012). “Business Intelligence and Analytics: From Big Data to Big Impact. ” MIS Quarterly 36 (4), 1165–1188. Dav enport, T . H. (2006). “Competing on Analytics. ” Harvar d Business Review 134 (1), 98–107. Feuerriegel, S, A Ratku, and D Neumann (2016). “Analysis of How Underlying T opics in Financial Ne ws Affect Stock Prices Using Latent Dirichlet Allocation. ” In: Pr oceedings of the 49th Hawaii International Confer ence on System Sciences (HICSS 2016) . IEEE Computer Society. Feuerriegel, S, G W olff, and D Neumann (2015). “Information Processing of F oreign Exchange News: Extending the Overshooting Model to Include Qualitative Information from News Sentiment. ” In: Pr oceedings of the International Conference on Information Systems (ICIS 2015) . Association for Information Systems. — (2016). “Ne ws Sentiment and Overshooting of Exchange Rates. ” Applied Economics (forthcoming). Feuerriegel, S. and D. Neumann (2013). “News or Noise? How News Drives Commodity Prices. ” In: Pr oceedings of the International Conference on Information Systems (ICIS 2013) . Association for Information Systems. Groth, S. and J. Muntermann (2008). “A T ext Mining Approach to Support Intraday Financial Decision- Making. ” In: Americas Confer ence on Information Systems (AMCIS 2008) . Groth, S. S. and J. Muntermann (2011). “An Intraday Market Risk Management Approach Based on T extual Analysis. ” Decision Support Systems 50 (4), 680–691. Hagenau, M., M. Liebmann, and D. Neumann (2013). “Automated News Reading: Stock Price Prediction based on Financial News Using Conte xt-Capturing Features. ” Decision Support Systems 55 (3), 685– 697. Halper , F . (2011). The T op 5 T rends in Pr edictive Analytics . U R L : http : / / www . information - management.com/issues / 21_6/the- top - 5- trends- in- redictive - an- alytics- 10021460- 1.html (visited on 08/20/2014). Hastie, T ., R. T ibshirani, and J. H. Friedman (2009). The Elements of Statistical Learning: Data Mining, Infer ence, and Pr ediction . 2nd ed. Springer Series in Statistics. New Y ork: Springer. Hinton, G. E. and R. R. Salakhutdinov (2006). “Reducing the Dimensionality of Data with Neural Networks. ” Science 313 (5786), 504–507. IBM (2013). The F our V’ s of Big Data . U R L : http://www.ibmbigdatahub.com/infographic/four- vs- big- data (visited on 04/21/2014). K onchitchki, Y . and D. E. O’Leary (2011). “Event Study Methodologies in Information Systems Research. ” International J ournal of Accounting Information Systems 12 (2), 99–115. Kuhn, M. and K. Johnson (2013). Applied Pr edictive Modeling . New Y ork, NY: Springer. MacKinlay , A. C. (1997). “Event Studies in Economics and Finance. ” Journal of Economic Liter atur e 35 (1), 13–39. Manning, C. D. and H. Schütze (1999). F oundations of Statistical Natural Language Pr ocessing . 6th Edi- tion. Cambridge, MA: MIT Press. Mine v , M., C. Schommer, and T . Grammatikos (2012). “Ne ws and Stock Markets: A Surv ey on Abnormal Returns and Prediction Models. ” U R L : http://orbilu.uni.lu/bitstream/10993/14176/1/TR. Survey.News.Analytics.pdf (visited on 04/19/2015). Mittermayer , M.-A. and G. F . Knolmayer (2006). “T ext Mining Systems for Market Response to News: A Surve y: W orking Paper. ” SSRN Electr onic Journal . T wenty-F ourth European Confer ence on Information Systems, Istanbul, T urkey , 2016 9 F euerrieg el and F ehr er / Deep Learning for F inancial Disclosures Muntermann, J. and A. Guettler (2007). “Intraday Stock Price Ef fects of Ad Hoc Disclosures: The German Case. ” Journal of International F inancial Markets, Institutions and Mone y 17 (1), 1–24. Nassirtoussi, A. K., S. Aghabozor gi, T . Y . W ah, and D. C. L. Ngo (2014). “T ext Mining for Market Prediction: A Systematic Re view. ” Expert Systems with Applications 41 (16), 7653–7670. Pang, B. and L. Lee (2008). “Opininion Mining and Sentiment Analysis. ” F oundations and T rends in Information Retrieval (2), 1–135. (V isited on 04/19/2015). Peramunetilleke, D. and R. W ong (2002). “Currency Exchange Rate Forecasting from Ne ws Headlines. ” Austr alian Computer Science Communications 24 (2), 131–139. Po wer, D. J. (2014). “Using ‘Big Data’ for Analytics and Decision Support. ” Journal of Decision Systems 23 (2), 222–228. Pröllochs, N., S. Feuerriegel, and D. Neumann (2015). “Generating Domain-Specific Dictionaries Using Bayesian Learning. ” In: 23r d Eur opean Confer ence on Information Systems (ECIS 2015) . Salton, G., E. A. Fox, and H. W u (1983). “Extended Boolean Information Retriev al. ” Communications of the A CM 26 (11), 1022–1036. Shmueli, G. and O. K oppius (2011). “Predicti ve Analytics in Information Systems Research. ” MIS Quarterly 35 (3), 553–572. Socher , R., J. Pennington, E. Huang, A. Ng, and C. Manning (2011). “Semisupervised Recursiv e Autoen- coder . ” In: Pr oceedings of the Confer ence on Empirical Methods in Natural Language Pr ocessing (EMNLP 2011) , pp. 151–161. Socher , R. et al. (2013). “Recursi ve Deep Models for Semantic Compositionality Over a Sentiment T reebank. ” In: Pr oceedings of the Conference on Empirical Methods in Natural Langua ge Pr ocessing (EMNLP 2013) . V ol. 1631. T akeuchi, L. and L. Y u Y ing (2013). Applying Deep Learning to Enhance Momentum Learning T rading Strate gies in Stocks . U R L : http://cs229.stanford.edu/proj2013/TakeuchiLee- ApplyingDeepLearningT oEnhanceMomentum TradingStrategiesInSto cks. pdf (visited on 05/03/2015). T urban, E. (2011). Business Intellig ence: A Managerial Appr oach . 2nd Edition. Boston, MA: Prentice Hall. V izecky , K. (2011). “Data Mining meets Decision Making: A Case Study Perspectiv e. ” In: Americas Confer ence on Information Systems (AMCIS 2011) , Paper 453. T wenty-F ourth European Confer ence on Information Systems, Istanbul, T urkey , 2016 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment