Framework for the hybrid parallelisation of simulation codes
Writing efficient hybrid parallel code is tedious, error-prone, and requires good knowledge of both parallel programming and multithreading such as MPI and OpenMP, resp. Therefore, we present a framework which is based on a job model that allows the user to incorporate his sequential code with manageable effort and code modifications in order to be executed in parallel on clusters or supercomputers built from modern multi-core CPUs. The primary application domain of this framework are simulation codes from engineering disciplines as those are in many cases still sequential and due to their memory and runtime demands prominent candidates for parallelisation.
💡 Research Summary
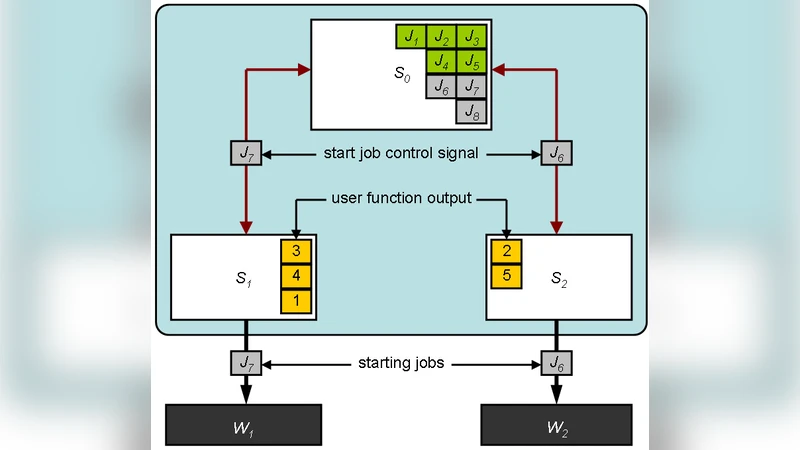
The paper addresses the difficulty of converting existing sequential engineering simulation codes into efficient hybrid MPI/OpenMP parallel programs. To lower the barrier, the authors propose a job‑based framework that abstracts away communication, synchronization, data distribution, and load balancing. A “job” can be as small as a single instruction or as large as an entire program; it receives its input as a set of data chunks and produces output in the same form. Users describe jobs in a plain‑text file, specifying four integer parameters for each job: (1) the identifier of the user‑provided function, (2) the number of threads required (0 means “use all available cores”), (3) the number of data chunks to process or a reference to results of previous jobs, and (4) an optional flag indicating whether the job should return results. By chaining jobs through these references, the user encodes the full dependency graph of the algorithm without writing any MPI or OpenMP code.
The runtime architecture follows a master‑slave model. The master scheduler (MPI rank 0) holds the complete algorithm description. Sub‑schedulers (other ranks) receive subsets of jobs, store intermediate results, and manage a pool of dynamically spawned worker processes. Workers are “memoryless” in the sense that they only hold the data required for their current job; after completion they notify their scheduler, which can then release the memory. This design minimizes communication overhead but introduces a recovery cost: if a worker crashes, its results are lost and must be recomputed.
Currently the framework uses “fat workers”: all user functions are linked into a single worker binary. The authors plan to support “slim workers” that load functions at runtime, enabling specialization for GPUs, the Cell Broadband Engine, or other accelerators. Data chunks are described using MPI data types; the framework copies only the pointer to the actual data, so the user must not free the memory until the framework does so.
A key feature is the ability of a job to generate new jobs during execution, which is essential for iterative algorithms. The paper demonstrates this capability with a parallel Jacobi solver for linear systems A · x = b. The sequential algorithm consists of three logical steps: compute the update vector y (job J1), apply updates and compute the residual (job J2), and check convergence (job J3). Because the outer convergence loop requires repeated execution of J1 and J2, J3 creates new instances of these jobs and re‑submits them to the master scheduler. Although this dynamic job creation may seem inefficient, performance measurements show that the framework’s runtime is only about 10 % slower than a hand‑tuned MPI implementation for problem sizes of 2709×2709, 4209×4209, and 7209×7209 over 500 iterations. The modest overhead stems from extra data copying and scheduling, but the benefit is a dramatically reduced development effort: the original sequential code required almost no modification.
The authors conclude that their framework offers a practical pathway for engineers to parallelize legacy simulation codes with minimal code changes. By hiding the complexities of hybrid parallel programming, it enables rapid prototyping and portability across heterogeneous clusters. Future work includes implementing dynamic function loading, extending support to GPU and other accelerators, and adding fault‑tolerance mechanisms to mitigate the loss of worker results.
Comments & Academic Discussion
Loading comments...
Leave a Comment