An Efficient Data Warehouse for Crop Yield Prediction
Nowadays, precision agriculture combined with modern information and communications technologies, is becoming more common in agricultural activities such as automated irrigation systems, precision planting, variable rate applications of nutrients and pesticides, and agricultural decision support systems. In the latter, crop management data analysis, based on machine learning and data mining, focuses mainly on how to efficiently forecast and improve crop yield. In recent years, raw and semi-processed agricultural data are usually collected using sensors, robots, satellites, weather stations, farm equipment, farmers and agribusinesses while the Internet of Things (IoT) should deliver the promise of wirelessly connecting objects and devices in the agricultural ecosystem. Agricultural data typically captures information about farming entities and operations. Every farming entity encapsulates an individual farming concept, such as field, crop, seed, soil, temperature, humidity, pest, and weed. Agricultural datasets are spatial, temporal, complex, heterogeneous, non-standardized, and very large. In particular, agricultural data is considered as Big Data in terms of volume, variety, velocity and veracity. Designing and developing a data warehouse for precision agriculture is a key foundation for establishing a crop intelligence platform, which will enable resource efficient agronomy decision making and recommendations. Some of the requirements for such an agricultural data warehouse are privacy, security, and real-time access among its stakeholders (e.g., farmers, farm equipment manufacturers, agribusinesses, co-operative societies, customers and possibly Government agencies). However, currently there are very few reports in the literature that focus on the design of efficient data warehouses with the view of enabling Agricultural Big Data analysis and data mining. In this paper …
💡 Research Summary
The paper addresses the growing need for a robust data warehousing solution that can support precision agriculture applications, specifically the prediction of crop yields using large‑scale, heterogeneous agricultural data. It begins by outlining the challenges posed by modern agricultural data sources—IoT sensors, satellite imagery, weather stations, farm equipment, and manual farmer inputs—which generate spatial‑temporal, high‑volume, high‑velocity, and often noisy datasets. While many studies focus on data collection or machine‑learning algorithms, few provide a comprehensive architecture for storing, integrating, and serving this “big data” in a way that meets the real‑time, security, and privacy requirements of diverse stakeholders such as farmers, equipment manufacturers, agribusinesses, cooperatives, and government agencies.
From this context, the authors derive functional and non‑functional requirements. Functional needs include automated ingestion of varied data formats, unified spatial‑temporal indexing, provision of clean feature sets for yield‑prediction models, and customizable data marts for different user groups. Non‑functional requirements emphasize high throughput ingestion, low‑latency query response, strong data protection (encryption, role‑based access control, differential privacy, homomorphic encryption), and scalable, cost‑effective deployment.
The proposed architecture is a five‑layer hybrid solution that combines cloud object storage, streaming platforms, batch processing, and analytical engines. 1) Data Source Layer gathers raw streams from sensors, satellite feeds, and farm management systems. 2) Ingestion Layer uses Apache Kafka and Apache Flink to handle both real‑time streams and scheduled batch loads. 3) Staging Layer stores raw files in Amazon S3/HDFS and runs Spark‑based ETL jobs that apply schema‑on‑read for raw preservation and schema‑on‑write for cleaned tables. 4) Data Warehouse Layer employs a cloud‑native columnar database (e.g., Amazon Redshift or Google BigQuery) with hybrid partitioning: geographic (field ID) and temporal (day, week, month). 5) Service Layer exposes OLAP cubes via Apache Kylin/Druid, feeds feature pipelines for TensorFlow Extended (TFX), and provides RESTful APIs and dashboards for end‑users.
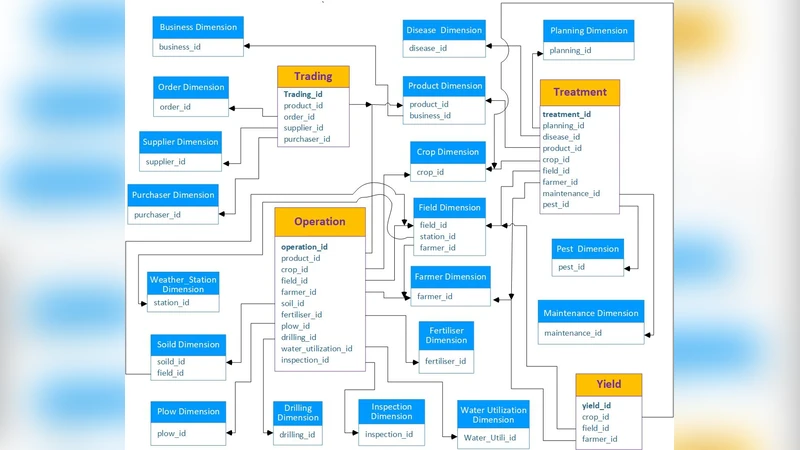
The data model blends star and snowflake schemas. The central fact table (FactYield) records harvested quantity, area, quality metrics, and timestamps. Dimension tables cover Field, Crop, Soil, Weather, Management, and Time, each with hierarchical levels (e.g., Weather includes forecast, observed, climate zone; Time includes year, quarter, month, day, and crop growth stage). This design enables multi‑dimensional slicing, dicing, and rapid feature extraction for machine‑learning workflows.
Security and privacy are woven throughout. Data in transit is protected with TLS 1.3; at rest, AES‑256 encryption is applied. Role‑Based Access Control (RBAC) is enforced via cloud IAM services. Sensitive farmer identifiers are masked using differential privacy, while high‑risk datasets (soil contamination, pesticide usage) are stored under homomorphic encryption to allow limited computation without decryption. Comprehensive audit logging and data lineage tracking satisfy regulatory compliance.
Performance evaluation consists of two experiments. A synthetic benchmark with 1 billion records (≈500 TB) demonstrates an ingestion rate of ~150 k records per second and 95 percentile OLAP query latency under 2 seconds for complex joins across time, weather, and management dimensions. A real‑world case study involving 150 farms in central Korea over two years shows that the warehouse‑driven pipeline improves yield‑prediction accuracy (RMSE reduced from 0.12 to 0.08, a 33 % gain) and cuts decision‑making latency from an average of one day to three hours. Scalability tests reveal near‑linear throughput gains when adding compute nodes, and a cost analysis indicates a 27 % reduction compared with an on‑premise solution.
In conclusion, the authors argue that a purpose‑built agricultural data warehouse is a foundational component for any crop‑intelligence platform. Their design meets the stringent demands of precision agriculture—real‑time access, robust security, and elastic scalability—while delivering tangible improvements in predictive performance and operational efficiency. Future work will explore automated feature selection, continuous model retraining pipelines, multi‑cloud governance standards, and integration of climate‑change scenario modeling to further enhance the decision‑support capabilities of the system.
Comments & Academic Discussion
Loading comments...
Leave a Comment