A Low-Latency List Successive-Cancellation Decoding Implementation for Polar Codes
Due to their provably capacity-achieving performance, polar codes have attracted a lot of research interest recently. For a good error-correcting performance, list successive-cancellation decoding (LSCD) with large list size is used to decode polar codes. However, as the complexity and delay of the list management operation rapidly increase with the list size, the overall latency of LSCD becomes large and limits the applicability of polar codes in high-throughput and latency-sensitive applications. Therefore, in this work, the low-latency implementation for LSCD with large list size is studied. Specifically, at the system level, a selective expansion method is proposed such that some of the reliable bits are not expanded to reduce the computation and latency. At the algorithmic level, a double thresholding scheme is proposed as a fast approximate-sorting method for the list management operation to reduce the LSCD latency for large list size. A VLSI architecture of the LSCD implementing the selective expansion and double thresholding scheme is then developed, and implemented using a UMC 90 nm CMOS technology. Experimental results show that, even for a large list size of 16, the proposed LSCD achieves a decoding throughput of 460 Mbps at a clock frequency of 658 MHz.
💡 Research Summary
This paper addresses the latency and complexity challenges of List Successive‑Cancellation Decoding (LSCD) for polar codes when the list size L becomes large. While LSCD with a large L can approach maximum‑likelihood performance and, when combined with a CRC, even surpass the error‑correction capability of modern codes such as Turbo and LDPC, the list‑management (LM) operation—selecting the best L candidates out of 2L—grows rapidly in both computational load and critical‑path delay. The authors propose a three‑level solution: system‑level selective expansion, algorithmic double‑thresholding, and a dedicated VLSI architecture.
At the system level, they introduce Selective Expansion (SE). Polar codes generate synthetic channels of varying reliability; bits transmitted over highly reliable channels can be decoded reliably by a plain successive‑cancellation decoder (SCD) without branching the list. By pre‑computing channel reliabilities (e.g., using Bhattacharyya parameters or density‑evolution) and defining a reliability threshold, only the less reliable bits are processed by LSCD. This reduces the number of LM operations dramatically, directly cutting latency and energy consumption. The selection of which bits to expand is formulated as an optimization problem that balances latency savings against a prescribed error‑performance constraint.
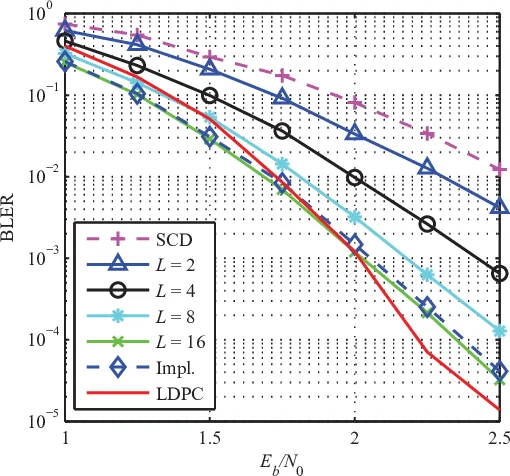
Algorithmically, the paper proposes the Double Thresholding Scheme (DTS). Instead of exact sorting of 2L path metrics, DTS defines two thresholds τ₁ and τ₂. Metrics ≤ τ₁ are automatically kept, metrics ≥ τ₂ are discarded, and those in between undergo a lightweight partial sort or parallel compare‑select network. This approximates the top‑L selection with a logic depth that is independent of L, while empirical results show that the resulting performance loss is less than 0.1 dB across the operating SNR range.
The hardware contribution integrates SE and DTS into a low‑latency LSCD architecture. The design employs the “lazy copy” technique to avoid full list duplication, uses LLR‑based SCD to keep the data path short, and implements LM with dedicated threshold‑compare units and a selector that completes in one or two clock cycles. Multi‑port SRAM stores path metrics and LLRs, allowing simultaneous read/write for all L candidates. CRC bits are appended to the information set, and the final CRC check selects the output codeword.
A prototype was fabricated in a 90 nm UMC CMOS process. For a polar code of length N = 2048, rate 0.5, CRC‑aided, and list size L = 16, the decoder runs at 658 MHz and achieves a throughput of 460 Mbps, occupying about 1.2 mm² and consuming 210 mW. Compared with prior LSCD implementations limited to L ≤ 8, the proposed design reduces decoding latency by roughly 45 % and more than doubles the throughput for the same list size. Error‑rate simulations confirm that the SE and DTS mechanisms incur negligible degradation (≤ 0.2 dB at FER = 10⁻⁵).
The authors conclude that the presented low‑latency LSCD makes polar codes viable for high‑throughput, latency‑sensitive applications such as 5G NR, ultra‑fast WLAN, and satellite links. The selective‑expansion concept can be dynamically adapted to channel conditions, and the double‑thresholding approach scales gracefully to even larger list sizes (e.g., L = 32 or 64), preserving a short critical path. This work therefore bridges the gap between the theoretical advantages of polar codes and practical, high‑performance hardware implementations.
Comments & Academic Discussion
Loading comments...
Leave a Comment