StarGAN-VC: Non-parallel many-to-many voice conversion with star generative adversarial networks
This paper proposes a method that allows non-parallel many-to-many voice conversion (VC) by using a variant of a generative adversarial network (GAN) called StarGAN. Our method, which we call StarGAN-VC, is noteworthy in that it (1) requires no paral…
Authors: Hirokazu Kameoka, Takuhiro Kaneko, Kou Tanaka
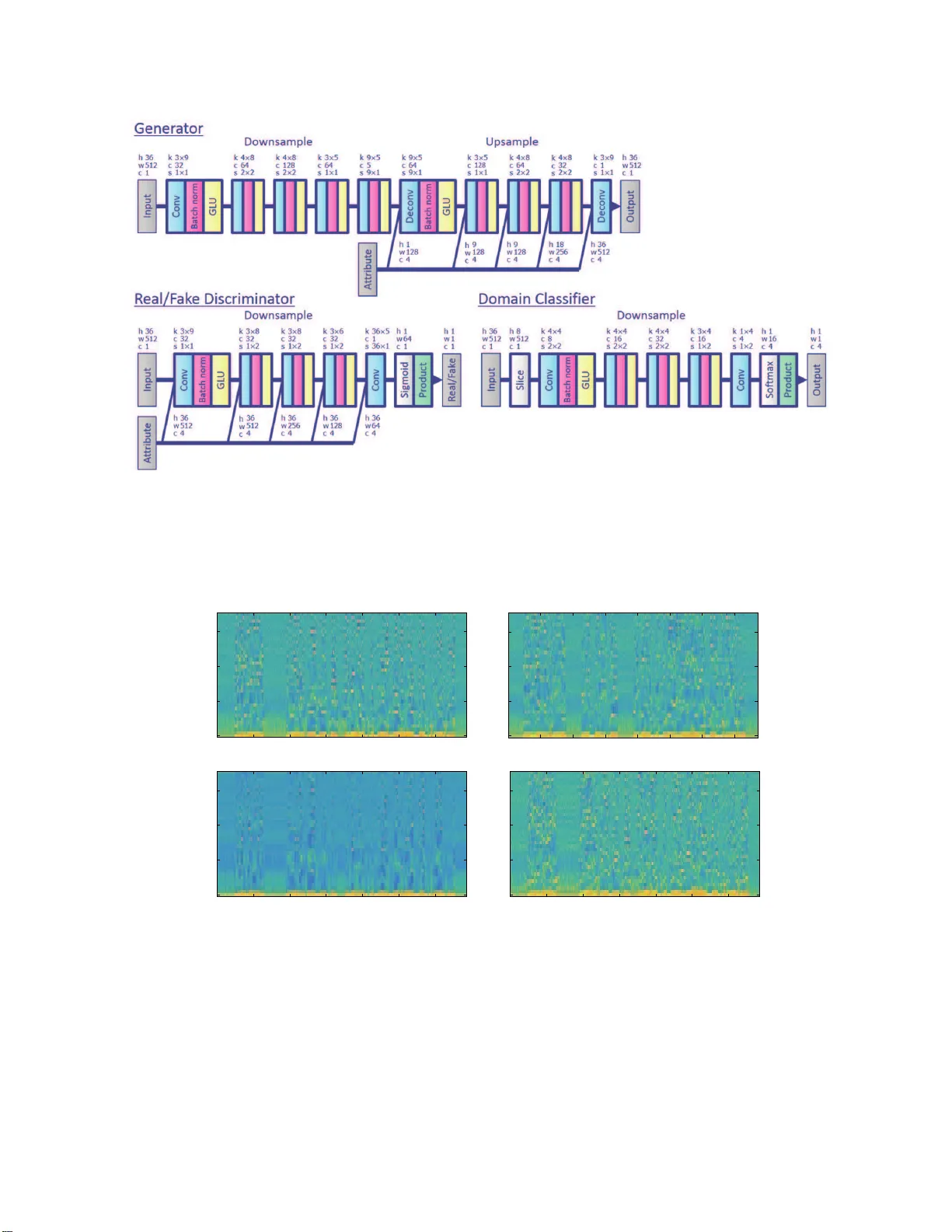
ST ARGAN-VC: NON-P ARALLEL MANY -T O-MANY V OICE CONVERSION WITH ST AR GENERA TIVE ADVE RSARIAL NETWORKS Hir okazu Kameoka, T akuhir o Kaneko, K ou T a n a ka, Nobukatsu Hoj o NTT Commu n ication Science Laboratories, NTT Corporation, Japan ABSTRA CT This paper propo ses a method that allows non-parallel many- to-many voice conversion (VC) by u sin g a variant of a gen - erative adversarial network (GAN) called StarGAN. Our method, which we call StarGAN-VC, is n otew orthy in that it (1) req uires no parallel utteran ces, transcription s, or time alignment proc edures for speech g enerator trainin g, (2 ) si- multaneou sly lear ns m any-to-many map pings acro ss differ- ent attribute d omains using a single gen erator network , (3) is able to gen e r ate converted speech signals quic k ly enoug h to allow real-time im p lementation s and (4) requir es on ly several minutes o f tr a ining examples to genera te re a so nably realistic sounding speech. Subjective ev aluation experiments on a non-p arallel many-to -many spe a ker iden tity conversion task revealed that the pro posed m e thod obtain ed high er soun d quality and speaker similarity than a state-of-the- art meth od based on variational autoencoding GANs. Index T erms — V oice con version (VC), non-p a r allel VC, many-to-ma ny VC, generative adversarial networks (GANs), CycleGAN-VC, StarGAN-VC 1. INTR ODUCTION V oice con version (VC) is a techniq u e for co n verting para/no n- linguistic infor mation contained in a given u tterance while preserving ling uistic info rmation. This tech nique can b e ap- plied to various tasks such as speaker-identity mo dification for text-to-speech (TT S) systems [1], speak ing assistance [2, 3], spee ch enhancemen t [4–6], an d pronun ciation con version [7]. One successful VC fram ew ork inv olves statistical meth- ods based on Gaussian mixtu re models (GM Ms) [8 – 10]. Recently , a neural network (NN)-based framework b a sed on feed-fo rward deep NNs [11 – 1 3], recurrent NNs [1 4], and generative adversarial nets ( GANs) [7], and an exemplar- based fram ework based o n no n-negative matr ix factorization (NMF) [15, 16] have also proved suc c e ssful. Many conven- tional VC metho ds inclu d ing those mentione d a b ove r equire accurately aligned p arallel source and target speec h data. Howe ver , in many scenarios, it is no t always possible to col- lect parallel utterances. Even if we could collect such data, we typically need to per form time alignment pr ocedure s, which becomes relati vely d ifficult when there is a large ac o ustic gap between the sou rce and target speech. Since many frame - works are weak as regards the misalignmen t found with parallel da ta, careful pr e-screening and manual correction may be r equired to make these fr amew orks work reliably . T o bypass these restriction s, this p aper is conce r ned with devel- oping a non -parallel VC metho d, which requ ires n o para llel utterances, transcriptio n s, o r time alignm ent p rocedu res. In gen eral, the quality and c on version effect ob ta in ed with non -parallel methods are u sually limited co m pared with methods u sing parallel d ata d ue to the d isadvantage r e lated to the training cond ition. Thus, developing non -parallel methods with as high an audio qu ality and co n version ef- fect as para llel methods can b e very ch allenging. Recently , some attempts have bee n made to develop non -parallel meth- ods [17 – 29]. For example, a meth o d using auto matic speech recogn itio n (ASR) was pro posed in [2 4]. The idea is to conv ert input speech un der the r estriction that the p osterior state pr o bability of the acou stic model of an ASR system is preserved so that the tran scription of the converted speech becomes consistent with that o f th e input speech. Since th e perfor mance of this method dep ends hea vily on the quality of the a c oustic mod el of ASR, it can fail to work if ASR does not f u nction re liab ly . A method using i-vectors [3 0], k n own as a featur e fo r speaker verificatio n, was rec ently propo sed in [25]. Con ceptually , the idea is to shift the a coustic features of in p ut speech towards target speech in the i-vector space so that the co n verted speech is likely to be reco gnized as the target speaker by a speaker recogn izer . While th is metho d is also free from parallel data, one limitation is tha t it is applicable only to speaker identity conversion tasks. Recently , a fr amew ork b ased on con ditional variational autoenco ders (CV AEs) [31, 32] was propo sed in [22, 29]. A s the n ame implies, variational autoenco ders (V AEs) are a prob- abilistic coun terpart of auto encoder s (AEs), consisting of en- coder and decod er n etworks. CV AEs [32] ar e an extended version of V AEs wh ere the encod er an d deco der networks can take an au xiliary variable c as an additional inpu t. By using acoustic features as the training examples and the asso- ciated attribute labels as c , the network s learn how to co n vert an attribute of so u rce speech to a target attribute acco rding to the attribute label f ed into the deco der . This CV AE-based VC appro ach is notable in that it is co mpletely free from par- allel data and works even with un aligned corpo ra. However , one well-known pr oblem a s re gards V AEs is th a t outputs from the d ecoder tend to be oversmoothed. For VC applicatio ns, this can be problematic si nce it usually results in poor quality buzzy-soundin g speech. One p owerful framework th at can potentially overcome the wea kness of V AEs inv olves GANs [33]. GANs offer a general fram ew ork f o r trainin g a gene rator network in such a way that it can deceive a r eal/fake discrimin a tor network. While th ey h ave b e en fo und to be effecti ve for use with im- age genera tio n, in recent years they have a lso been employed with notab le su ccess for various speech processing tasks [7, 34–38]. W e previously rep o rted a non-p arallel VC me thod using a GAN variant called cycle-con sistent GAN ( Cy c le- GAN) [ 26], wh ich was or iginally p roposed as a metho d for translating images using unpaired training e xamp les [39 – 41]. This m e thod, which we call CycleGAN - VC, is design e d to learn the map ping G of acou stic features from one attribute X to an other a ttr ibute Y , its inverse m apping F , and a d is- criminator D , whose r o le is to d istinguish the acou stic fea- tures of converted speech fr o m those of r eal speech, throug h a training loss combining an adversarial loss an d a cycle con- sistency loss. Although this meth od was shown to work r ea- sonably well, one major lim itation is th a t it only learns one- to-one mappings. With a lot of VC application scenarios, it is desirable to obtain m any-to-many mappin gs. One naive way of app lying CycleGAN to many-to - many VC tasks would be to train different G and F pa irs for a ll pair s of attribute do- mains. Howe ver , this may b e ineffectiv e sinc e all attribute d o- mains are common in the sense that th ey represent speech an d so the re m ust be commo n latent featur es that can be shared across different dom ains. In pra c tice, the n umber of param- eters will in crease quadr atically with the nu mber of attribute domains, makin g p arameter training cha llen ging particularly when there are a limited number of tr aining examples in e ach domain. A commo n limitation of CV AE-VC and CycleGAN-VC is that at test time the attribute of the in put speech m ust be known. As for CV AE-VC, the sou rce attribute label c must b e fed into the enco der of the trained CV AE and with CycleGAN-VC, the source attribute domains at training and test times must be the same. T o overcome the shortcomin g s and limitations o f CV AE- VC [22] an d CycleGAN-VC [26], this p a per prop oses a non- parallel many-to-many VC me th od using a recently proposed novel GAN variant called StarGAN [4 2], wh ich offers the advantages of CV AE-VC and CycleGAN-VC co ncurren tly . Unlike CycleGAN-VC and as with CV AE-VC, our m ethod, which we call StarGAN-VC, is capable o f simultane o usly learning many-to -many mappings using a single encoder- decoder ty pe generator network G where th e attributes of the g enerator o utputs are controlled b y an au xiliary in put c . Unlike CV AE-VC and as w ith Cyc leGAN-VC, StarGAN-VC uses an adversarial loss for genera to r training to en courag e the g enerator outpu ts to beco me indisting uishable from re al speech a n d ensure that the map pings between each pair of attribute doma in s will p reserve lingu istic inf ormation . It is also no tew orthy that u nlike CV AE-VC an d CycleGAN-VC, StarGAN-VC does n ot requ ir e any info rmation about the attribute of the input speech at test time. The V AE-GAN fram ew ork [43] is per haps anoth er natu - ral way of overcoming the weakness o f V AEs. A non-parallel VC metho d based on this fram ew ork h as alread y been pro- posed in [23]. W ith this appro ach, an ad versarial loss deriv ed using a GAN discriminator is inco rporate d in to the tra in ing loss to enc ourage the d ecoder outpu ts of a CV AE to be indis- tinguishable from r eal speech fea tures. Although the concept is similar to our StarGAN-VC ap proach , we will show in Sec- tion 4 th at o u r approach o utperfo rms this method in ter ms o f both the audio qu ality and con version effect. Another related technique worth noting is the vector quan - tized V AE (VQ - V AE) a pproach [2 7], wh ich h a s perfo rmed impressively in non- parallel VC tasks. T h is appr oach is par- ticularly notab le in that it o ffers a novel way of overcoming the we akness o f V AEs by using the W av eNet mod el [44], a sample-by - sample neura l signal genera to r , to devise both the encoder and dec oder of a discrete cou nterpar t of CV AEs. The original W a veNet mo d el is a r ecursive m o del that makes it possible to predict the d istribution of a sample con ditioned on the samp les th e g enerator has prod uced. While a faster version [45] h as rece ntly been propo sed , it typically requ ires huge computa tio nal cost to gene rate a stream of samples, which can cause difficulties when imp lem enting real-tim e systems. The model is also k nown to requir e a huge num b er of tra in ing exam p les to be able to gen erate n atural-soun ding speech. By contrast, our m ethod is no tew orthy in that it is able to gener a te signals quick ly enoug h to allow r eal-time implementatio n and requ ires only several minutes of training examples to generate reasonably realistic-soun d ing spee c h . The remaind er of this pa per is organized as fo llows. W e briefly revie w th e fo rmulation o f CycleGAN-VC in Sectio n 2, pr esent the id ea of Star GAN-VC in Section 3 and show experimental results in Section 4. 2. CYCLEGAN V OICE CONVERSION Since the pr esent method is an extension of CycleGAN- VC, which we pro posed previously [26], we start by briefly re- viewing its formulation . Let x ∈ R Q × N and y ∈ R Q × M be acou stic fe a ture se- quences of speech belon ging to attribute do mains X an d Y , respectively , wh ere Q is th e feature dime nsion and N and M are the length s of the sequ ences. T h e a im of CycleGAN-VC is to learn a m a pping G that conv erts the a ttribute o f x into Y and a mapping F that d oes th e oppo site. Now , we intro- duce discriminators D X and D Y , whose roles are to pred ict whether o r not their inpu ts are the acou stic featur es of r eal speech belongin g to X an d Y , and define L D Y adv ( D Y ) = − E y ∼ p Y ( y ) [log D Y ( y )] − E x ∼ p X ( x ) [log(1 − D Y ( G ( x )))] , (1) L G adv ( G ) = E x ∼ p X ( x ) [log(1 − D Y ( G ( x )))] , (2) L D X adv ( D X ) = − E x ∼ p X ( x ) [log D X ( x )] − E y ∼ p Y ( y ) [log(1 − D X ( F ( y )))] , (3) L F adv ( F ) = E y ∼ p Y ( y ) [log(1 − D X ( F ( y )))] , (4) as the adversarial losses fo r D Y , G , D X and F , respectively . L D Y adv ( D Y ) and L D X adv ( D X ) measure how ind istinguishable G ( x ) and F ( y ) are from acoustic fe atures of re al spee ch belongin g to Y and X . Since the goal of D X and D Y is to correctly disting uish the converted feature sequence s obtained via G and F fr om real speech feature seq uences, D X and D Y attempt to minimize these losses to av oid bein g fooled by G and F . Conversely , since one of the go als of G an d F is to generate rea listic-so u nding spe ech that is indistinguishable from real speech, G and F attempt to maximize these losses or min im ize L G adv ( G ) an d L F adv ( F ) to foo l D Y and D X . It can be sho wn that the output distrib utions of G and F trained in this way will match the em pirical distributions p Y ( y ) and p X ( x ) . Note that since L G adv ( G ) and L F adv ( F ) are minimized when D Y ( G ( x )) ≃ 1 and D X ( F ( y )) ≃ 1 , we can also u se − E x ∼ p X ( x ) [log D Y ( G ( x ))] and − E x ∼ p X ( x ) [log D Y ( G ( x ))] as the adversarial losses for G and F . As me ntioned in Section 1, training G and F using on ly the adversarial losses does n ot guar antee that G or F will pre- serve the linguistic infor mation o f the input speech since ther e are infinitely many mapping s that will induce the same outp u t distributions. T o further regular iz e these m appings, we intro- duce a cycle consistency loss L cyc ( G, F ) = E x ∼ p X ( x ) [ k F ( G ( x )) − x k 1 ] + E y ∼ p Y ( y ) [ k G ( F ( y )) − y k 1 ] , (5) to en courag e F ( G ( x )) ≃ x and G ( F ( y )) ≃ y . W ith the same motiv ation, we also consider an identity mapp ing loss L id ( G, F ) = E x ∼ p X ( x ) [ k F ( x ) − x k 1 ] + E y ∼ p Y ( y ) [ k G ( y ) − y k 1 ] , (6) to en sure that inputs to G an d F ar e kept uncha nged wh en the inputs a lready b elong to Y a nd X . The full objectives of CycleGAN-VC to be minim ized with re spect to G , F , D X and D Y are thus given as I G,F ( G, F ) = L G adv ( G ) + L F adv ( F ) + λ cyc L cyc ( G, F ) + λ id L id ( G, F ) , (7) I D ( D X , D Y ) = L D X adv ( D X ) + L D Y adv ( D Y ) , (8) where λ cyc ≥ 0 and λ id ≥ 0 are regularization p arameters, which weig h th e importance of the c ycle consistency loss an d the identity mapping loss relative to th e adversarial losses. 3. ST ARGAN V OICE CO NVERSION While CycleGAN-VC allows the genera tio n o f natural- sounding speech when a suf ficient nu mber of training ex- amples are av ailable, on e limitation is that it only lear ns one-to- one-map pings. Here, we prop ose u sing StarGAN [42] to d ev elop a meth od that allows n on-pa rallel many-to-many VC. W e call the pre sent method StarGAN-VC. 3.1. T raining objectives Let G be a ge n erator that takes an acoustic fe a tu re sequenc e x ∈ R Q × N with an arbitrary attribute and a target attribute la- bel c as the inputs and generates an acoustic fe a ture sequence ˆ y = G ( x , c ) . W e assum e that a spe ech attribute comp rises one or mo re categories, each consisting of mu ltiple c la sses. W e thus represen t c as a con catenation o f one-h ot vectors, each of which is filled with 1 at th e index o f a class in a cer- tain category and with 0 everywhere else. For exam ple, if we c onsider speaker iden tities as the only attribute category , c will b e repre sen ted as a sing le one- hot vector , wher e each element is associated w ith a different speaker . One of the goals of Star GAN-VC is to make ˆ y = G ( x , c ) as realistic as real speech features a n d belo ng to attribute c . T o realize this, we intro duce a real/fake d iscr im inator D as with CycleGAN and a domain classifier C , whose role is to p redict to wh ich classes an inp ut belo ngs. D is designed to p roduce a pr oba- bility D ( y , c ) that an input y is a real speec h featu re whereas C is desig n ed to produce class probab ilities p C ( c | y ) o f y . Adversarial Loss: First, we define L D adv ( D ) = − E c ∼ p ( c ) , y ∼ p ( y | c ) [log D ( y , c )] − E x ∼ p ( x ) ,c ∼ p ( c ) [log(1 − D ( G ( x , c ) , c ))] , (9 ) L G adv ( G ) = − E x ∼ p ( x ) ,c ∼ p ( c ) [log D ( G ( x , c ) , c )] , (10) as ad versarial losses fo r discrim inator D and gener ator G , respectively , where y ∼ p ( y | c ) den otes a training exam- ple of an aco ustic featu re sequ e nce of real speech with at- tribute c and x ∼ p ( x ) d enotes tha t with an ar bitrary at- tribute. L D adv ( D ) takes a small value when D correctly clas- sifies G ( x , c ) and y as fake and real speech featu res wherea s L G adv ( G ) takes a small v alue whe n G successfully deceives D so that G ( x , c ) is misclassified as r eal speech featu res by D . Thus, we would like to minimize L D adv ( D ) with respect to D and minimize L G adv ( G ) with respect to G . Domain Classification Loss: Next, we define L C cls ( C ) = − E c ∼ p ( c ) , y ∼ p ( y | c ) [log p C ( c | y )] , (11) L G cls ( G ) = − E x ∼ p ( x ) ,c ∼ p ( c ) [log p C ( c | G ( x , c ))] , (12) as dom a in classification lo sses for classifier C and generator G . L C cls ( C ) an d L G cls ( G ) take small values when C correctly classifies y ∼ p ( y | c ) an d G ( x , c ) as belong ing to attribute c . Thus, we would like to minim ize L C cls ( C ) with respect to C and L G cls ( G ) with respect to G . Fig. 1 . Concept of CycleGAN trainin g. Fig. 2 . Concept of StarGAN trainin g. Cycle Consistency Loss: Training G , D and C using on ly the losses presented ab ove do es not guarantee that G will pre- serve the ling u istic information of input speech. T o encourage G ( x , c ) to b e a bijectio n , we introd u ce a cycle co nsistency loss to be minimized L cyc ( G ) = E c ′ ∼ p ( c ) , x ∼ p ( x | c ′ ) ,c ∼ p ( c ) [ k G ( G ( x , c ) , c ′ ) − x k ρ ] , (13) where x ∼ p ( x | c ′ ) den otes a tr a ining examp le of an acoustic feature sequence of r eal speech with attribute c ′ and ρ is a positive constant. W e also con sider an identity mappin g lo ss L id ( G ) = E c ′ ∼ p ( c ) , x ∼ p ( x | c ′ ) [ k G ( x , c ′ ) − x k ρ ] , (14) to en sure that an in put into G will re main unchan ged when the input already belong s to the target a ttribute c ′ . T o sum marize, th e fu ll objectives of StarGAN-VC to be minimized with respect to G , D an d C are given as I G ( G ) = L G adv ( G ) + λ cls L G cls ( G ) + λ cyc L cyc ( G ) + λ id L id ( G ) , (15) I D ( D ) = L D adv ( D ) , (16) I C ( C ) = L C cls ( C ) , (17) respectively , where λ cls ≥ 0 , λ cyc ≥ 0 and λ id ≥ 0 are regularization par ameters, wh ic h weigh the im portance of th e domain classification loss, the cycle consistency loss and the identity mapping loss relative to th e adversarial losses. 3.2. Con version pr ocess As an acoustic featur e vector, we use mel- cepstral coefficients computed from a spec tr al e nvelope obtained using WORLD [46]. After tr a in ing G , we can convert the acoustic feature sequence x of an inp ut utterance with ˆ y = G ( x , c ) , (18) where c de n otes the target attrib ute label. A na¨ ıve way of ob- taining a time-domain sign al is simply to use ˆ y to reconstru ct a signal with a vocoder . Instead of directly u sing ˆ y , we ca n also use the recon structed feature sequence ˆ y ′ = G ( x , c ′ ) , (19) to ob tain a time-do m ain signal if the attribute c ′ of th e in- put speech is known. By using ˆ y and ˆ y ′ , we can obtain a sequence of spectral gain functions. Once we obtain th e spec- tral gain function s, we can r econstruct a time-do main signal by multiplyin g the spe c tral env elope of input speech by the spectral gain fun ction frame-by -frame and resynthesizing the signal using a vocoder . 3.3. Network architectures One of the key featur e s of ou r appr oach includ ing [7, 2 6] is that we consider a gen e r ator that takes an acoustic feature se- quence instead of a single-f r ame aco ustic feature as an input and outputs an acou stic fe a tu re sequence of the same len gth. This allows us to o btain co n version ru les that captu r e time depend encies. While RNN-based ar chitectures are a na tu- ral choice fo r m o deling time series d ata, w e use a con volu- tional n eural n etwork (CNN)- based ar chitecture to desig n G as detailed below . The generato r G consists o f en coder and decoder networks whe re only the decoder ne twork takes an auxiliary inp ut c . W e also design D an d C to take acou stic feature sequences as inp uts and gener ate sequences of pr oba- bilities. Generator : Her e, we treat an acoustic feature seq u ence x a s an im age of size Q × N with 1 ch annel and use 2 D CNNs to con stru ct G , as they are suitab le for p arallel compu ta tio ns. Specifically , we use a g ated CNN [ 47], which was origina lly introdu c ed to model word sequences for languag e m odel- ing an d was shown to outp e rform long short-term m emory (LSTM) lang u age mod els trained in a similar setting. W e previously app lied gated CNN a r chitectures fo r voice con - version [7, 26] and aud io source separation [ 48], and their effecti veness has already been confirmed. In the en c oder part, the output o f the l -th hidden layer is described as a linear projection modu lated by an output gate h l = ( W l ∗ h l − 1 + b l ) ⊙ σ ( V l ∗ h l − 1 + d l ) , (20) where W l ∈ R D l × D l − 1 × Q l × N l , b l ∈ R D l , V l ∈ R D l × D l − 1 × Q l × N l and d l ∈ R D l are the gene rator network param eters to be trained, and σ deno tes the elemen twise sigmoid fun ction. Similar to LSTMs, the output g ate multiplies e ach element of W l ∗ h l − 1 + b l and contro l wh a t information should be propa- gated thr ough the hierar c hy of layers. This gating me c hanism is called Gated Linear U n its (G L U). In the deco d er part, the output of the l -th hidden layer is g iv en by h ′ l − 1 = [ h l − 1 ; c l − 1 ] , (21) h l = ( W l ∗ h ′ l − 1 + b l ) ⊙ σ ( V l ∗ h ′ l − 1 + d l ) , (22) where [ h l ; c l ] means the concaten ation of h l and c l along the channel dimension , and c l is a 3 D array con sisting of a Q l - by- N l tiling of copies o f c in the feature an d time dimension s. The inp ut into the 1 st laye r of G is h 0 = x and the output o f the final layer is given a s a regular linear projection h ′ L − 1 = [ h L − 1 ; c L − 1 ] , (23) ˆ y = W L ∗ h ′ L − 1 + b L . (24) It sho uld be noted th at the entire architecture is fully co n volu- tional with no f ully-con nected layers, which allo ws us to take an e n tire seq uence with an arbitrary length as an inpu t and conv ert the entire sequence. Real/Fake Discriminato r: W e leverage the idea of Patch- GANs [49] to devise a real/fake discriminator D , which clas- sifies wh ether loc a l se gments o f an inpu t feature sequence ar e real o r fake. More specifically , we devise D using a g ated CNN, which takes an acoustic featur e seq uence y and an at- tribute label c as inp u ts and pr o duces a sequenc e of probabil- ities that measures how likely each segment of y is to be real speech featur es of attribute c . The o utput of th e l -th layer o f D is given in the same way as (21) and (22) and th e final out- put D ( y , c ) is g iv en b y the p roduct of all these probab ilities. See Section 4 for mor e details. Domain Classifier: W e also devise a d omain classifier C u s- ing a gated CNN, whic h takes an acou stic featu re seq uence y and prod uces a seq uence of class proba b ility distributions that m easures how likely each segment of y is to belon g to attribute c . The outp ut of the l -th laye r of C is given in the same way as (2 0) and th e final ou tput p C ( c | y ) is g i ven by the product of all th ese distributions. See Sectio n 4 fo r more details. 4. SUBJECTIVE EV ALU A TION T o confirm th e performan c e o f the propo sed metho d, we con- ducted subjective evaluation experimen ts on a n on-pa r allel many-to-ma ny speaker iden tity conversion task. W e u sed the V oice Con version Challen ge (VCC) 2018 dataset [50], which consists of reco rdings of six female and six m ale US En - glish speakers. W e u sed a subset of spea kers fo r training and evaluation. Specifically , we selected two fe m ale spe a k- ers, ‘ VCC2SF1’ a n d ‘VCC2SF2’, and two male speakers, ‘VCC2SM1’ and ‘VCC2SM2’. Thu s, c is rep resented as a four-dimension a l one-hot vector and there were twelve d iffer - ent combinatio ns o f source and target speakers in total. The audio files for each spea ker were manually segmented into 116 shor t sen tences (ab out 7 minu te s) where 81 a n d 3 5 sen- tences (ab o ut 5 and 2 minutes) were provided as tr aining and ev aluation sets, respectively . All th e speech signa ls were sam- pled at 2205 0 Hz. For ea ch utter ance, a spectral envelope, a logarithm ic fun damental frequ ency ( log F 0 ), and aperio d ici- ties (APs) were extracte d ev ery 5 ms using th e WORLD an- alyzer [46]. 36 mel-cepstral coefficients (M CCs) were then extracted from each spectral envelope. The F 0 contour s were conv erted using th e logarithm Gaussian n ormalized transfor- mation descr ib ed in [51]. The aperio dicities were u sed di- rectly witho ut modificatio n. The network configur ation is shown in detail in Fig. 3. The signals of th e con verted speech were obtained using the metho d described in 3.2. W e ch o se the V AEGAN-based a pproach [23] as a com- parison for our expe r iments. Althoug h we would have liked to exactly rep licate the implemen tation of this meth od, we made our own design choices o wing to missing d etails of the network con figuration an d h yperpar ameters. W e cond ucted an AB test to compare the sound qu ality of th e c onv erted speech samples and an ABX test to compar e the similar ity to target speaker of the conv erted speech samp les, wh ere “ A ” and “B” were c onv erted speech sam ples obtain ed with th e propo sed an d baseline method s an d “X” was a real spe ech sample of a target speaker . With these listenin g tests, “ A ” and “B” were p resented in random o rders to eliminate bias in the order of stimuli. Eig h t listen e r s participa ted in ou r listening tests. For th e AB test for soun d q uality , each lis- tener was p resented { “ A ”, “B” } × 20 u tterances, and for th e ABX test for speaker similarity , each listener was pr esented { “ A ”,“B”,“X” } × 24 utter a nces. Each listen e r was then asked to select “ A ”, “ B” or “fair” fo r each utteran ce. The results are sho wn in Fig. 5. As the results sh ow , the prop osed method significan tly outperf ormed the baseline m e th od in terms of both sound qua lity an d speaker similarity . Fig. 4 shows an example of the M CC sequences of source, rec on- structed, and co n verted speech. Audio sam ples are provided at htt p://www.kecl. ntt.co.jp/pe ople/kameoka.hirokaz u / D e m o s / s t a r g a n - v c / . 5. CONCLUSION This paper p ropo sed a method that allows n on-pa r allel many- to-many VC by u sing a n ovel GAN variant called Star GAN. Our method, wh ich we call StarGAN-VC, is noteworthy in that it ( 1) requ ires no parallel utteran c es, tr a n scriptions, or Fig. 3 . Network architectures o f gen erator G , real/fake discrimin ator D and domain c lassifier C . Here, the inputs and ou tputs of G , D and C are interpre ted as images, where “ h”, “w” and “c ” denote the heigh t, width and c h annel numb er , respectively . “Con v”, “Batch no rm”, “GLU”, “Deconv” “Sigmoid”, “Softmax ” and “Product” d enote conv olution, batch norm a lization, gated lin e ar unit, tran sp osed convolution, sigmoid, softma x , and prod uct po o ling lay ers, respectively . “k ”, “c” and “s” de n ote the kernel size, outpu t chann el num ber and stride size of a conv olution layer, respectively . No te tha t all the networks a r e f ully conv olutional with n o fully connecte d layers, thus allowing inputs to hav e arbitrary sizes. 0 1 2 3 4 5 6 Time (s) 0 10 20 30 MCC order 0 1 2 3 4 5 6 7 Time (s) 0 10 20 30 MCC order 0 1 2 3 4 5 6 Time (s) 0 10 20 30 MCC order 0 1 2 3 4 5 6 Time (s) 0 10 20 30 MCC order (a) (b) (c) (d) Fig. 4 . Ex amples o f acoustic f eature sequen ces of (a) sou rce speec h , (c) converted spe ech obtained with the baseline m ethod and (d) converted speech obtain ed with the propo sed m ethod, along with an aco u stic feature sequence of (b) the target speaker uttering the same sentence. time align ment pro c edures for speech g enerator training , (2 ) simultaneou sly learns many-to -many mappin gs across differ - ent voice attribute dom ains using a single g enerator network, (3) is ab le to gen e rate signa ls of converted sp eech quick ly enoug h to allow real- time impleme ntations and (4) r equires only sev eral min utes of tra ining examples to genera te r ea- sonably re a listic soun ding speech . Subjective ev aluation ex- periments on a non-p arallel many-to-many speaker identity conv ersion task revealed that the pr oposed meth od ob tained higher sound qu ality and speaker similarity than a baselin e Sound quality Speaker similarity 0 20 40 60 80 100 Proposed Fair Baseline Preferencescore(%) Fig. 5 . Results of the AB test for sound qu ality and the ABX test fo r speaker similarity . method based on a V AE-GAN approach . 6. REFERENCES [1] A. Kain and M. W . Macon, “Spectral vo ice con v ersion for text- to-speech synthesis, ” in Pro c. IEEE I nternational Confer ence on Acoustics, Speech and Signal P r ocessing ( I C ASSP) , 1998, pp. 285–288. [2] A. B. Kain, J.-P . Hosom, X. Niu, J. P . v an S anten, M. F ried- Oken, and J. S taehely , “Improv ing t he intelli gibility of dysarthric speech, ” Speech Communications , vol. 49, no. 9, pp. 743–759, 2007. [3] K. N akamura, T . T oda, H. Saruwatari, and K. Shikano, “Speaking-aid systems using GMM-base d voice con version for electrolaryngeal speech, ” Speech Communications , vol. 54, no. 1, pp. 134–1 46, 2012. [4] Z. Inanoglu and S. Y oung, “Data-driv en emotion con version in spok en English, ” Speech Communications , vol. 51, no. 3, pp. 268–28 3, 2009. [5] O. T ¨ urk and M. Schr ¨ oder , “Evaluation of expressi ve speech synthesis wi t h voice con v ersion and copy resynthesis tech- niques, ” IEEE T ransactions on Audio, Speech and Languag e Pr ocessing , vol. 18, no. 5 , pp. 965–973, 2010. [6] T . T od a, M. Nakagiri, and K. Shikano, “S tatistical voice con- version techniques for body-conduc ted un voiced speech en- hancement, ” IEEE T ransa ctions on Audio, Speech and Lan- guag e Pr ocessin g , v ol. 20, no. 9, p p. 2505 –2517, 2012. [7] T . Kaneko, H. Kameoka, K. Hiramatsu, and K. Kashino, “Sequence-to-sequ ence voice conv ersion wit h similari ty met- ric learned using generati ve adversarial networks, ” in Pro c. Annual Confere nce of the International Speech Communica- tion Association (Interspeec h) , 2017, pp. 1283–1 287. [8] Y . St ylianou, O. Capp ´ e, and E. Moulines, “Continuous prob- abilistic transform for voice con ve rsion, ” I E EE Tr ansactions on Speech and Audio Proc essing , vol. 6, no. 2, pp. 131–142, 1998. [9] T . T oda, A. W . Black, and K. T okuda , “V oice con version based on maximumlikelihood estimation of spectral parameter tra- jectory , ” IEEE T ran sactions on Audio, Speech and Langua ge Pr ocessing , vol. 15, no. 8 , pp. 2222–2235, 2007. [10] E . Helander , T . V irtanen, J. Nurminen, and M. Gabbouj, “V oice con v ersion using partial least squares regression, ” IEE E/ACM T ra nsactions on Audio, Speech and Languag e Pr ocessing , vol. 18, no. 5, pp. 912–921, 2010 . [11] S . Desai, A. W . Black, B. Y egnanaraya na, and K. Pr ahallad, “Spectral mapping using artificial neural network s for voice con v ersion, ” IEE E T ra nsactions on Audio, Speech and Lan- guag e Pr ocessing , vol. 18, no. 5, pp. 954 –964, 2010. [12] S . H. Mohammad i and A. Kain, “V oice con v ersion using deep neural networks with speake r-independ ent pre-training, ” in Pr oc. SLT , 2014, pp. 19 –23. [13] Y . Saito, S. T akamichi, and H. Saruwatari, “V oice con version using input-to-output highw ay netw orks, ” IEICE Tr ansactions on Information and Systems , vol. E100-D, no. 8, pp. 1925– 1928, 20 17. [14] L . Sun, S. Kang, K. Li, and H. Meng, “V oice con versio n us- ing deep bidirectional long short-term memory base d recurrent neural networks, ” in Pr oc. IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , 201 5, pp. 4869–4 873. [15] R. T akashima, T . T akiguchi, and Y . Ari ki, “Exemplar-based voice con version using sparse represen tation in noisy en viron- ments, ” IEICE T ransa ctions on Information and Systems , vol. E96-A, no. 10, pp. 1946–1953 , 2013. [16] Z . W u, T . V irtanen, E. S. Chng, and H. Li, “Exemplar-based sparse representation with residual compensation f or voice con v ersion, ” IEEE/ACM T rans actions on Audio, Speech and Langua ge Pr ocessing , vol. 22, no. 10, pp. 1506 –1521, 2014. [17] L . -H. Chen, Z.-H. Ling, L.-J. Liu, and L. - R . Dai, “V oice con- version using deep neu ral netwo rks with layer -wise gen erativ e training, ” I E EE/ACM Tr ansactions on Audio, Speech and Lan- guag e Pr ocessing , vol. 22, no. 12, pp. 18 59–1872 , 2014. [18] T . Nakashika, T . T akiguchi, and Y . Ariki, “V oice con version based on speaker -dependen t restricted Boltzmann machines, ” IEICE T ra nsactions on Information and Systems , vol. 97, no. 6, pp. 1403–141 0, 2014. [19] T . Nakashika, T . T akiguchi, and Y . Ar iki, “High-order se- quence modeling using speak er-depend ent recurrent t emporal restricted Boltzmann machines for voice con version, ” i n Pr oc. Annual Confer ence of the International Speech Communica- tion Associa tion (Inter speech) , 20 14, pp. 2278–2282. [20] T . Nakashika, T . T akiguchi, and Y . Ari ki, “Parallel-data-free, many-to-ma ny voice con v ersion using an adaptiv e restricted Boltzmann machine, ” in Pr oc. IEEE International W orkshop on Machine Learning for Signal Proce ssing (MLSP) , 2015. [21] M. Blaauw and J. Bonada, “Modeling and transforming speech using variational autoencoders, ” in Pr oc. Annual Confer ence of the International Speech Communication Association (In- terspeec h) , 20 16, pp. 1770–1774. [22] C. -C. Hsu, H.-T . Hw ang, Y .-C. Wu, Y . Tsao, and H.-M. W ang, “V oice con version from non-parallel corpora using v ariational auto-encode r , ” in P r oc. Asia P acific Signal and Information Pr ocessing Association Annual Summit and Confere nce (AP - SIP A ASC) , 2016, pp. 1–6. [23] C. -C. Hsu, H.-T . Hw ang, Y .-C. W u, Y . Tsao, and H. - M. W ang , “V oice con v ersion from unaligned corpora using variational autoencod ing W asserstein generativ e adversarial networks, ” in Pr oc. Annu al Confer ence of the International Speec h Commu- nication Association (Interspeec h) , 201 7, pp. 33 64–3368 . [24] F .-L. Xie, F . K. S oong, and H. Li, “ A KL div erge nce and DNN- based approach to voice con ve rsion without parallel training sentences, ” i n Proc . Annual Conferen ce of the International Speec h Communication A ssociation (Interspeech ) , 2016, pp. 287–29 1. [25] T . Kinnunen, L. Juvela, P . Alku, and J. Y amagishi, “Non- parallel voice con v ersion using i-vector PLDA: T o wards uni- fying speaker verification and transformation, ” in Proc . IEE E International Confer ence on Acoustics, Speech and Signal P r o- cessing (ICA SSP) , 2017, pp. 5535–5539. [26] T . Kane ko and H. Kam eoka, “Parallel-data-free v oice con v ersion using cycle-consistent adv ersarial networks, ” arXiv:1711.112 93 [stat.ML] , No v . 2017. [27] A. van den Oord and O. V inyals, “Neural discrete representa- tion learnin g, ” in A dv . Neur al Information Pr oc essing Sys tems (NIPS) , 2017, pp. 6309–6318. [28] T . Hashimoto, H. Uchida, D. Saito, and N. Minematsu, “Parallel-data-free many-to-man y voice con version based on dnn integrated with eigenspace using a non-p arallel speech cor- pus, ” in Pr oc. Annual Confer ence of the International Speec h Communication Assoc iation (Inter speech) , 2 017. [29] Y . Sait o, Y . Ijima, K. Nishida, and S. T akamichi, “Non-parallel voice con version using variational autoencoders conditioned by phonetic posterior grams and d-vectors, ” in Pr oc. IEE E In- ternational Confer ence on Acoustics, Speech and Signal Pro - cessing (ICA SSP) , 2018, pp. 5274–5278. [30] N. Dehak, P . Kenn y , R. Dehak, P . Dumouchel, and P . Ouel- let, “Front-end factor analysis for speak er verification, ” IEEE T ra nsactions on Audio, Speech and Langua ge Pr ocessing , v ol. 19, no. 4, pp. 788–79 8, 2011. [31] D. P . Kingma and M. W elli ng, “ Auto-en coding variational Bayes, ” in Proc. Internationa l Confer ence on Learning Repr e- sentations (ICL R) , 2014. [32] D. P . King ma and D. J. Rezende y , S. Mohamedy , and M. W elling, “Semi-supervised learning with deep genera- tiv e models, ” in Adv . Neural Information Processing Systems (NIPS) , 2014, pp. 3581–3589. [33] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde- Farley , S. Ozair, A. Courville, and Y . Bengio, “Generati ve ad- versarial nets, ” in Adv . Neur al Information P r ocessing Systems (NIPS) , 2014, pp. 2672–2680. [34] T . Kaneko, H . Kameoka, N. Hojo, Y . Ijima, K. Hiramatsu, and K. Kashino, “Generati ve adversarial network-based postfilter for statistical parametric speech synthesis, ” in Pro c. IEE E In- ternational Confer ence on Acoustics, Speech and Signal Pro - cessing (ICA SSP) , 2017, pp. 4910–4914. [35] Y . Saito, S. T akamichi, and H. Saruwatari, “S tatistical paramet- ric speech synthesis incorporating generativ e adversarial net- works, ” IEE E/ACM T rans. Audio, Speech, L angua ge Pr ocess. , vol. 26, no . 1, pp. 84–96, Jan . 2018. [36] S . Pascual, A. Bonafonte, and J. Serr ´ a, “SEGAN: Speech en- hancement generati ve adversarial network, ” [cs.LG] , Ma r . 2017. [37] T . Kaneko, S. T akaki, H. Kameoka, and J. Y amagishi, “Gen- erativ e adversarial network-based postfil t er for STFT spec- trograms, ” in Pr oc. Annual Confer ence of the International Speec h Communication A ssociation (Interspeech ) , 2017, pp. 3389–3 393. [38] K. Oyamada, H. Kameoka, T . Kaneko, K. T an aka, N. Hojo, and H. Ando, “Generati ve adve rsarial network-based ap- proach to signal reconstruction from magnitude spectrograms, ” arXiv:1804.021 81 [eess.SP] , Apr . 2018 . [39] J.- Y . Zhu, T . Park, P . Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks, ” in Pr oc. IC C V , 2017, pp. 2223–2232. [40] T . K i m, M. C ha, H. Kim, J. K. Lee, and J. Kim, “Learning to discov er cross-domain r elations with generati ve adve rsar- ial networks, ” in Pr oc. International Confer ence on Mach ine Learning (ICML ) , 2017, pp . 1857– 1865. [41] Z . Y i, H. Zhang, P . T an, and M. Gong, “DualGAN: Unsuper- vised dual learning for image-to-image translation, ” in Proc. ICCV , 2017, pp. 28 49–2857 . [42] Y . Choi, M. Choi, M. Kim, J. -W . Ha, S. Kim, and J. Choo, “StarGAN: Unified generativ e adversarial networks for multi- domain image-to-image translation, ” arXiv:1711.090 20 [cs.CV] , No v . 2017. [43] A. B. L. Larsen, S. K. Sønderby , H. Larochelle, and O. W inther , “ Autoencoding beyo nd pix els using a learned sim- ilarity metri c, ” arXiv:1512.09300 [cs.LG] , Dec. 2015. [44] A. v an den Oord, S. Dieleman, H. Zen, K. Simon yan, O. V iny als, A. Gra ves, N. Kalchbrenner , A. S enior , and K. Kavukcuoglu, “W aveNe t: A generati ve model for raw au- dio, ” arXiv:1609.03499 [cs.SD] , Sept. 201 6. [45] A. v an den Oord, Y . Li, I . Babu schkin, K. Simonyan , O. V iny als, K. Kavukcuo glu, G. van den Driessche, E. Lock- hart, L. C. Cobo, F . Stimberg, N. Casag rande, D. G., S. Noury , S. Dieleman, E. Elsen, N. Kalchbrenner , H. Z en, A. Graves, H. King, T . W alt ers, D. Belov , and D. Hass- abis, “Parallel W aveNet: Fast high-fidelity speech synthesis, ” arXiv:1711.104 33 [cs.LG] , No v . 2017. [46] M. Morise, F . Y ok omori, and K. Ozaw a, “WORLD: a vocode r- based high-qu ality spe ech synthesis system for real-time appli- cations, ” IEICE T r ansactions on Information and Systems , vol. E99-D, no. 7, pp . 1877– 1884, 2016. [47] Y . N. Dauphin, A. Fan, M. Auli, and D. Grangier, “Language modeling with gated con v olutional networks, ” in Proc. Inter- national Confere nce on Mach ine Learning (ICML) , 2017, pp. 933–94 1. [48] L . Li and H. Kameoka, “Deep clustering with gated con v olu- tional network s, ” in Proc . IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , 201 8, pp. 16–20. [49] P . Isola, J.-Y . Zhu, T . Zhou, and A. A. Efros, “Image-to-image translation wi t h conditional adversarial networks, ” in Proc. IEEE Confere nce on Computer V ision and P attern Recognition (CVPR) , 2017. [50] J. Lorenzo-T rueba, J. Y amagishi, T . T oda, D. Saito, F . Villa vi- cencio, T . Kinnu nen, and Z. Ling, “The voice con version chal- lenge 2018: Promoting dev elopment of parallel and nonparal- lel methods, ” arXiv:1804.04262 [eess.AS] , Apr . 2018. [51] K. Liu, J. Z hang, and Y . Y an, “High quality voice con ver- sion through phoneme-based linear mapping functions with STRAIGHT f or mandarin, ” in Pr oc. Interna tional Confer ence on Fuzzy Systems and Knowledge Discovery (F SKD) , 2007, pp. 410–414.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment