Dynamic Spectrum Matching with One-shot Learning
Convolutional neural networks (CNN) have been shown to provide a good solution for classification problems that utilize data obtained from vibrational spectroscopy. Moreover, CNNs are capable of identification from noisy spectra without the need for …
Authors: Jinchao Liu, Stuart J. Gibson, James Mills
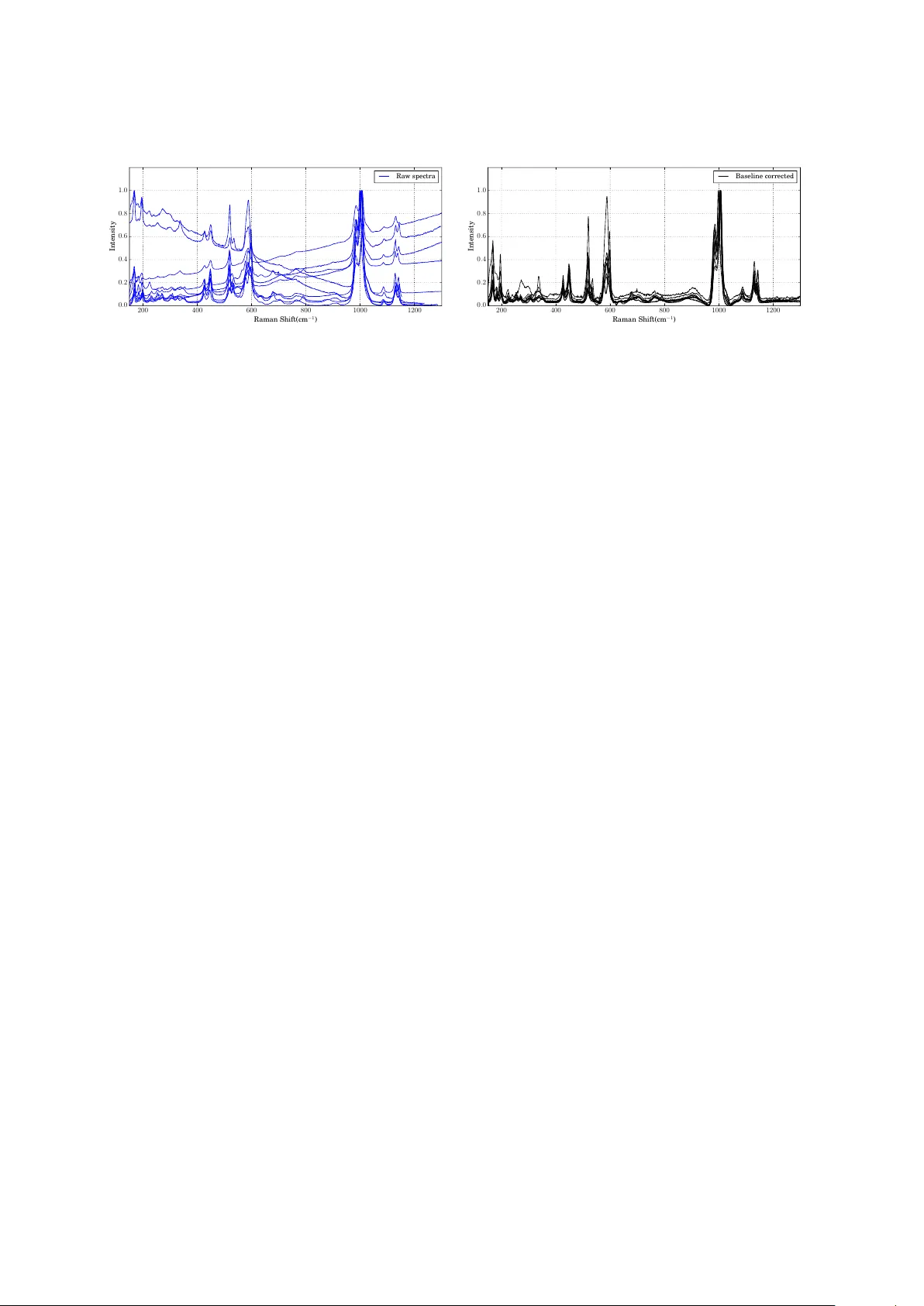
Dynamic Sp ectrum Matching with One-shot Learning Jinchao Liu 1 , Stuart J. Gibson 1,2 , James Mills 3 , and Margarita Osadchy 4 1 VisionMetric Ltd, Canterbury , Kent, UK. E-mail: liujinchao2000@gmail.com 2 Department of Physical Science, University of K ent, Canterbur y , K ent, UK. E-mail: S.J.Gibson@kent.ac.uk 3 Sandexis Ltd, Sandwich, K ent, UK. E-mail: james.mills@sandexis.co.uk 4 Department of Computer Science, University of Haifa, Mount Carmel, Haifa, Israel. E-mail: rita@cs.haifa.ac.il Abstract Convolutional neural networks (CNN) have b een shown to provide a goo d solution for classification problems that utilize data obtained from vibrational spectroscopy . Moreover , CNNs are capable of identification from noisy spe ctra without the ne ed for additional pre- processing. However , their application in practical spectroscopy is limited due to two short- comings. The eectiveness of the classification using CNNs drops rapidly when only a small number of spectra per substance are available for training (which is a typical situation in real applications). A dditionally , to accommo date new , previously unseen substance classes, the network must be retrained which is computationally intensive. Here we address these issues by reformulating a multi-class classification problem with a large number of classes, but a small number of samples p er class, to a binar y classification problem with suicient data available for representation learning. Namely , we define the learning task as identifying pairs of inputs as b elonging to the same or dierent classes. W e achieve this using a Siamese convolutional neural network. A novel sampling strategy is proposed to address the imbal- ance problem in training the Siamese Network. The trained network can eectively classify samples of unseen substance classes using just a single reference sample (termed as one-shot learning in the machine learning community ). Our results demonstrate b eer accuracy than other practical systems to date, while allowing eortless updates of the system’s database with novel substance classes. 1 Introduction Raman spectroscopy is use d for the identification and quantification of solids (particles, pellets, powers, films, fib ers), liquids (gels, pastes) and gases. The te chnique relies upon the inelastic scaering of mono chromatic light, caused by interactions with molecular vibrations. A “molec- ular fingerprint” of a substance can ther efore be obtained in the form of a spectrum comprising peaks that are characteristic of its chemical composition. 1 Since it provides fast, non-contact, and non-destructive analysis, Raman spectroscopy has a wide range of applications in a variety of industries and academic fields. In chemistr y it is used to identify mole cules and study chemical bonding. In solid-state physics it is used to char- acterize materials, measure temperature, and find the cr ystallographic orientation of a sample. It has a wide range of applications in biology and medicine. Raman spectroscopy is also use d for development and quality assessment in many industries such as semiconductors, polymers, pharmaceutics, and more. Raman spectroscopy is an eicient and non-destructive way to in- vestigate works of art. Finally , it can b e use d in homeland security for identifying dangerous substances. Paern recognition methods can be used for automatic identification of substances from their Raman spectrum. Ho wever , most of the paern recognition metho ds require prepr o cess- ing of the data. Due to this limitation, a standard pipeline for a machine classification system based on Raman spectroscopy includes preprocessing in the following order: cosmic ray removal, smoothing and baseline corr e ction. Additionally , the dimensionality of the data is oen reduce d using principal components analysis (PCA) prior to the classification step. It was shown in [1], that the Raman Sp ectra classification can be achieved successfully us- ing convolutional neural networks (CNNs). There are three main benefits in using CNNs for vibrational spe ctra classification. Firstly , a CNN can b e trained to remove baselines, extract good featur es, and dierentiate b etween sp ectra from a large number of classes in an integrated manner within a single network architecture. Thus it removes the nee d for preprocessing the signal. Secondly , CNN has b een shown to achieve significantly beer classification results than all previous metho ds[2, 3, 4, 5, 6, 7, 8, 1]. Thirdly , the classification is very eicient in terms of computation time. In addition to these factors, a practical sp ectrum matching system should b e able to add/remove spectra from a database dynamically in real time, without the additional overheads asso ciated with retraining the underlying classifier . Some substances might have only few or even a single sample per class. Thus a practical system should b e able to provide accurate classification even when the training data is sparse. In that context, applying CNN is problematic. First, adding a new class to a CNN requires a change in architecture of the network (or at least its last layers) and retraining of the network 1 which is computationally intensive and therefore time consum- ing. Second, training CNN requires many labelle d samples, while using one or a few training samples per class dramatically degrades the accuracy of CNN compared to a fully trained CNN or a simpler classifier with a small training set. Previous methods, that pro vide the capability of a dynamic update of the reference set with one or fe w samples per substance, hav e tended to use v er y simple paern matching algorithms. T ypically , commercial systems return a short list of candidate substances ranke d according to their similarity with the quer y sp ectrum according to the relative magnitudes of their hit quality index (HQI) scores. Dierent metrics have been used for HQI including Euclidean distance and 1 A more eicient method is to retrain the last layers and only fine tune the rest of the weights. However , the success of this approach depends on the similarity of the new class to the existing ones. 2 correlation and the cosine of the angle b etween two spe ctra. The cosine similarity metric has also previously b een combined with a nearest neighbour classifier [9, 10]. V ariations on these metrics include assigning greater weight to particularly discriminating peaks, or eliminating peaks that only occur in the quer y spectrum on the assumption that they are due to impurities that are of no interest. The HQI value can be aecte d by artefacts due to baseline and purge pr oblems and the presence of additional p eaks cause d by sample contamination and is therefore susceptible to misinterpretation. Databases shipped with commercial vibrational spe ctroscop y instrumenta- tion sometimes contain records for substances that simply list the positions and intensities of the peaks contained within the spe ctra and these could b e determine d from the oretical models (con- versely our application is concerned with matching to reference spectra obtained empirically ). Although reducing the data to peak p ositions allows queries to be run quickly , p eak width can be important for interpretation [11]. Multi-scale methods make use of the structures of individual peaks [12, 13, 14]. Where a sample contains an unknown mixtur e of substances, probabilities for the presence of each component may b e obtaine d by , for example, a generalize d linear mo del [15] or rev erse searching using non-negative least squares [16]. A rev erse search ignores p eaks that occur in the quer y sp ectrum but not in the reference sp ectrum containe d in the library/database. Howe ver , these methods do not extract salient features from the data and are therefore highly susceptible to noise. Ther efore preprocessing of the raw signal is required for good matching performance. T o summarize, CNN is advantages over other metho ds in providing accurate, eicient, and fully automated classification of sp ectra, but it requires large training sets and retraining when a substance is added or deleted from the system. In this paper , we present a system based on CNN that solves these two pr oblems. The problem of limited data in the CNN training can b e addressed by reformulating an n-way classification task into a binary task of classifying pairs of inputs as either the same or dierent classes. For this binary problem, applied to a large number of classes, even a small number of samples per class would result in a large number of training pairs (w e provide further details in Section 2.2). A spe cial architecture, referr e d to as Siamese network [17], has be en used to determine if pairs of inputs b elong to the same or dierent class in a numb er of domains (e.g., RGB images [18, 19, 20], NIR images [21], spee ch [22] and text [23]). The Siamese network architecture can be viewed as a combination of a non-linear mapping for extracting features from the input pairs with a weighted metric for comparing the resulting feature vectors. Siamese networks learn features and metrics in an integrated manner using gradient-base d learning. In this work we use a CNN for non-linear mapping as it can learn invariance and hierarchy present in the data and has exhibited unique advantages in processing spectral data. When a Siamese network is trained on many classes, the resulting features and the corre- sponding learned metric are capable of generalizing beyond the classes seen in training. Thus it can b e used for learning to classify unseen classes using a single training sample, termed one- shot learning. Previous work show e d the merit of using Siamese networks for one-shot learning in character recognition and object classification (e.g. [18, 24]). W e propose applying one-shot 3 Figure 1: Diagram of a Siamese network with a convolutional neural network as its twin network. x 1 and x 2 are two samples to compare, f 1 and f 2 denote their features extracted by the twin CNN. The metric in the featur e space has chosen to be weighted L 1 which is learnable by adjusting w . Finally the network outputs a similarity measure s ( x 1 , x 2 ) ∈ [0 , 1] . learning, using a Siamese network, for spe ctra classification and use it to build a dynamic clas- sification system that enables online up dating of a spectra database ( without retraining of the system). Spe cifically , for an n-way classification problem, we use a single reference sample per class, including the new classes that were not previously represented during the training of the Siamese network, and map the reference samples and the test sample to the feature space via the CNN part of the the Siamese network. Then, the nearest neighbour rule is applied using the learned similarity metric for classifying the test sample. If more samples are available per class, the comparison can b e extended to k-nearest neighb ors. One can also perform ranking or any other analysis of distances between the test sample to the reference set. Our experiments show that the proposed method can p erform an accurate classification of spectra even in cases where the numb er of classes is large and with a single or a handful of samples per class. Moreover , it allows ne w classes to be added or existing classes to be remo ved from the model in real time with no additional eort. 2 Materials and Methods 2.1 Siamese Network for One-Shot Learning Siamese networks [18] consist of two (twin) networks that have exactly the same structure and identical weights. The architecture of the Siamese net used in this work is shown in Figure 1. W e implemented the twin networks using the CNN architecture shown in Figure 2. The twin network maps an input sp ectrum to a feature space using the same mechanism as is employed for classification using a single CNN [1] and thus enjoys all the benefits of CNN as detaile d above. The CNN architecture includes six blocks, each with a convolutional layer , followed by batch normalization, LeakyReLU non-linearity , and max-pooling. The numb er of feature maps is decreased in every second layer . The outputs of the last block are concatenated and f laene d to form a featur e vector , which is used as an input to the metric learning part of the Siamese net. 4 Figure 2: Diagram of convolutional neural networks that are variants of LeNets[25]. This was used in our work as the twin network in Siamese networks. BN stands for batch normal- ization. Conv(m, n) stands for a convolutional layer with m neurons/filters of kernel size n. Maxpooling( σ, s ) denotes a MaxPooling layer with kernel size σ and stride s . Further details of the CNN architecture are sho wn in Figure 2. Mathematically , the model is given as follows, s ( x i , x j ) = 1 / (1 + exp( − w > k f ( x i ) − f ( x j ) k 1 )) (1) where x i , x j are a pair of samples, f is a non-linear transform realized by a convolutional network (twin network) and w are the trainable weights that can b e viewed as a metric in the feature space. W e use a binary cross-entropy loss function to train the Siamese netw ork. 2.2 Imbalanced Positive and Negative Pairs: A Sampling Strategy One of the core problems asso ciated with training a Siamese network is generating negative and p ositive pairs eiciently and suiciently for the purpose of distinguishing b oth similar and dissimilar samples. Supp ose there are N classes, each of which has M samples, the total number of positive and negative pairs are M ( M − 1) N/ 2 and M 2 N ( N − 1) / 2 , respe ctively . In applications like mineral recognition, in which there are typically hundreds of dierent minerals, but only a handful of sp ectra available for each, there will be considerably more negative than p ositive pairs i.e. for M ∼ 10 and N ∼ 100 , there will be roughly 5 K positive and 500 K negative pairs. If we feed this ratio of training pairs into the network without proper countermeasures, positive pairs may be dominate d by negative pairs during training and will therefore be under-represented in the model. As a result, the network is likely to be biased towards distinguishing dissimilar pairs. 5 An extreme case would be a classifier that only reports negative responses and fails to learn variance within the same class or similar samples. A common way of dealing with an imbalanced dataset is to under-sample the majority class i.e. negative pairs in this case, or over-sample the minority class i.e. positive pairs, or to combine both these strategies [26]. Here, we propose using a Bootstrapping-base d strategy as follows: assume that we have S m positive pairs and S n negative pairs wher e S m S n , for each iteration. W e then sample S m positive pairs and an equal number of negative pairs, b oth with replace- ment. W e r ep eat a number of iterations until the Siamese network has been trained suiciently . It should be noted that it is crucial to sample the positive pairs with replacement, instead of generating all the positive pairs deterministically , to prevent o verfiing to positive pairs. 2.3 T raining Convolutional Siamese Nets The Siamese network was traine d using the Adam algorithm[27] (a variant of stochastic gradient descent) for 30 iterations. The learning rate was reduced by half every 10 iterations. Xavier initialization was used to initialize the convolution layers. W e applied early stopping to prevent overfiing. Training was performed on a single NVIDIA GTX-1080 GP U. 2.4 Mineral Datasets W e teste d the proposed method on the problem of recognising minerals using the largest pub- licly available mineral database , RRUFF[28]. W e used a dataset that contains raw (uncorrected) spectra for 512 minerals. In order to investigate the performance of the teste d methods on pre- processed spectra, we employed a widely-used baseline correction te chnique, asymmetric least squares [29], to produce a baseline-correcte d version of the dataset. 3 Results and Discussion Our experiments include three parts. The first part (discussed in Section 3.1) tests the perfor- mance of the proposed method on unseen classes. Good classification results in this e xperiment show the merit of the pr op osed method in a practical application that allo ws for online changes in a database (the reference set). The second part ( discussed in Se ction 3.2) compares the per- formance of the Siamese network with CNN [1] in a standard multi-class classification seing. This experiment sho ws that the proposed method has a comparable classification accuracy with a static CNN (which requires re-training aer each change in the database). Finally , we use a visualization technique (shown in Section 3.3) to illustrate the ability of the network to map samples of dierent classes to non-ov erlapping clusters. 6 200 400 600 800 1000 1200 Raman Shift(cm − 1 ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Intensity Ra w spectra (a) Raw spectra where baselines can be obser ved. 200 400 600 800 1000 1200 Raman Shift(cm − 1 ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Intensity Baseline corrected (b) Baseline corrected by asymmetric least squares Figure 3: Spectra of a mineral, hydro xylherderite , from RRUFF raw database and corresponding baseline corrected spectra by asymmetric least squares. 3.1 One-shot Classification for Unseen Classes 3.1.1 Evaluation Protocol W e first investigated the proposed method on unseen classes using the following protocol: W e split all 512 classes (minerals) into non-ov erlapping sets for training, validation, and test. W e used 50% of the classes for training, 10% for validation, and 40% for testing. W e trained the Siamese network using all samples in the training set as discussed in Section 2.2. W e validated the results for early stopping on pairs produced from the samples in the validation set. During test time, we picked at random a single sample from each class in the test set to form a reference set. W e tested the classification of all other samples from the test set by searching for their best match in the reference set. Using randomization of data partition, we repeate d both training and test several times to obtain statistically r eliable results. 3.1.2 Results and Analysis W e compared our method with with three others: nearest neighbour (NN) with L 2 distance, nearest neighb our with cosine similarity and large margin nearest neighbour (LMNN). Nearest neighbour with the Euclidean distance and cosine similarity have b een widely used in com- mercial soware for spe ctrum matching and were therefor e included for comparison. LMNN is a popular metric learning method that learns a Mahanalobis distance for k -nearest neighbour classification ( k NN). A linear transform of the input space is learned such that the k -nearest neighbors of a sample in the training set share the same class label with the sample , while sam- ples from dierent classes are separated by a large margin. In short, LMNN learns a linear transform, which is particularly beneficial for k NN classification. The results are summarize d in T able 1. On raw data, NN with either L 2 or cosine similarity performed p oorly , with a low accuracy rate of ∼ 0.5. LMNN achieved beer results, with an accuracy of 0.725. The Siamese network significantly outperforme d all tested methods and gave the highest rate of 0.901. On the baseline corrected (i.e. preprocessed) data, all previous methods 7 T able 1: One-shot classification accuracy ( f 1 -score) of convolutional Siamese nets and other compared methods on RRUFF mineral dataset with and without baseline correction. Signal T yp e NN( L 2 ) NN(cosine) LMNN[30] Siamese Net Raw Spectra 0.461 ± 0.046 0.525 ± 0.036 0.725 ± 0.041 0.901 ± 0.014 Preprocessed 0.802 ± 0.033 0.833 ± 0.030 0.818 ± 0.029 0.886 ± 0.032 performed much beer (as expected). The Siamese network achie ved 0.886, which is lower than on the raw data but still significantly beer than the other three methods. These results show that the Siamese network succee ds to learn beer features and a beer , problem sp ecific, similarity metric. This is consistent with our previous work [1] in which end- to-end learning with a CNN resulted in classification rates for unprocesse d spectra that were superior to those achieved when these spectra were analysed using pipeline methods. It is worth noting that on the raw data, LMNN achie ved beer results than NN with both L 2 and cosine similarity (as shown in T able 1). LMNN is capable of learning a linear transform to facilitate the subse quent nearest neighb our classification. This means it has limite d pr eprocess- ing capability 2 , which is form of learning when compared with CNN, but certainly beer than no preprocessing of the raw sp ectra. On the other hand, on baseline corr e cted data, LMNN does not benefit much from the limited preprocessing and its performance was comparable with NN with the L 2 distance metric and worse than NN with cosine similarity . 3.2 Multi-class Classification for Trained/Seen Classes Next we compared our convolutional Siamese network with a CNN [1] in a standard multi- class classification, in which unseen samples are classified into learned classes. W e applied the Siamese network as described in Section 3.1, but with the r eference set composed of the known classes (used to train the Siamese network). For this set of experiments, we followed the test pro- tocol, [1], which randomly sele cts one sample from each class to form a test set. The remaining samples were used for training and validation. The process was repeated a numb er of times. The results are summarized in T able 2. W e can see that when data augmentation is used in training, the classification accuracy of the Siamese network is comparable to CNN on the preprocessed spectra and only slightly lower than CNN on the raw data. This indicates that Siamese networks can be used for a large-scale classification of spectra with almost no accuracy loss. W e investigated the eect of data augmentation on conv olutioinal Siamese networks and on CNNs. T able 2 shows that the convolutional Siamese network traine d with no data augmentation is able to achieve a good accuracy of roughly 85% on both raw and preprocessed spe ctra. A 2 If one closely obser ves samples in Figure 3(a), rotating the spectra clockwise or counterclockwise respectively , which is a kind of linear transform, would certainly correct the baselines to a certain degree, though not thoroughly . 8 T able 2: Classification accuracy on trained classes of convolutional Siamese nets and CNNs on the RRUFF mineral dataset, with or without baseline correction. Methods Data A ugmentation Raw Spectra Preprocessed Sp ectra Convolutional Nets[1] No ♣ 0.705 ± 0.031 0.779 ± 0.015 Y es 0.933 ± 0.007 0.920 ± 0.008 Convolutional Siamese Nets No 0.850 ± 0.029 0.842 ± 0.035 Y es 0.921 ± 0.010 0.919 ± 0.007 trained CNN network with no augmentation, was heavily ov erfied. Halving its size by keeping only one copy of each block (instead of two) resulted in significant loss in classification compared with the original network trained on augmented data, spe cifically , 70 . 5% on raw spectra and 77 . 9% on preprocessed spe ctra. Furthermore, a smaller CNN aained higher accuracy on the preproceessed data than on the raw spectra, which is contrary to the results of the original CNN trained on the augmented data. This suggests that the reduced CNN is not large/de ep enough to learn a baseline correction well. Since synthetic augmentation of the data is not always easy and in some cases is not even possible, one could consider using Siamese networks for classification instead of CNN. Siamese networks learn a binar y task from pairs of samples. The number of pairs that could be obtained from a data set comprising many classes with a small number of samples in each, is large enough to prev ent strong overfiing. 3.3 Visualization W e used t-distributed stochastic neighb our embe dding (t-SNE)[31] to visualize the feature space learned by the Siamese netw ork. T o av oid cluer in the visualization, we reduced the number of unseen classes by removing the minerals with fewer than three samples. The results depicte d in Figure 4 show that the pr oje cted samples cluster by mineral type. 4 Conclusion and Future W ork In this paper , we have proposed an one-shot learning solution base d on convolutional siamese networks to realize a dynamic spe ctrum matching system which is capable of classifying both seen and unseen classes accurately . Especially , for unseen classes/substances, the proposed sys- tem requires as few as one example p er class to achieve accurate classification which allows adding classes/substances into the mo del dynamically . W e validate d the feasibility and eective- ness of our method on the largest public available mineral dataset. Although we demonstrated our metho d on mineral sp ecies classification using Raman spectra, the proposed framew ork can generalize to other kinds of sp ectroscopy and other applications in the computational chemistry , 9 Figure 4: t-SNE projection of the transformed features of some test samples. Classes are high- lighted in dierent colors. 10 drug discovery , and health care etc, esp ecially in the cases where available data for training is limited and/or frequent updates of the database are required. References [1] J. Liu, M. Osadchy , L. Ashton, M. Foster , C. J. Solomon, and S. J. Gibson, “Deep convolu- tional neural networks for raman spe ctrum recognition: a unifie d solution, ” A nalyst , vol. 142, pp. 4067–4074, 2017. [2] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with de ep convolu- tional neural networks, ” in Advances in Neural Information Processing Systems 25 , pp . 1097– 1105, 2012. [3] T . W ang, D . J. W u, A. Coates, and A. Y . Ng, “End-to-end text recognition with conv olutional neural networks, ” in Proceedings of the 21st International Conference on Paern Recognition (ICPR2012) , pp. 3304–3308, Nov 2012. [4] I. Sutskever , O . Vinyals, and Q . V . Le, “Sequence to sequence learning with neural net- works, ” in Advances in Neural Information Processing Systems 27 (Z. Ghahramani, M. W elling, C. Cortes, N. D. Lawrence, and K. Q . W einberger , eds.), pp. 3104–3112, Curran Associates, Inc., 2014. [5] R. Girshick, J. Donahue, T . Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation, ” in Computer Vision and Paern Recognition , 2014. [6] K. He, G. Gkioxari, P. Dollár , and R. Girshick, “Mask R-CNN, ” in Proceedings of the Interna- tional Conference on Computer Vision (ICCV) , 2017. [7] M. Bojarski, D . Del T esta, D. Dworakowski, B. Firner, B. F lepp, P. Goyal, L. D . Jackel, M. Monfort, U . Muller, J. Zhang, X. Zhang, J. Zhao, and K. Zieba, “End to End Learning for Self-Driving Cars, ” A rXiv e-prints , Apr . 2016. [8] D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Baenberg, C. Case, J. Casper , B. Catanzaro , Q. Cheng, G. Chen, J. Chen, J. Chen, Z. Chen, M. Chrzanowski, A. Coates, G. Diamos, K. Ding, N. Du, E. Elsen, J. Engel, W . Fang, L. Fan, C. Fougner , L. Gao, C. Gong, A. Hannun, T . Han, L. Johannes, B. Jiang, C. Ju, B. Jun, P. LeGresley , L. Lin, J. Liu, Y . Liu, W . Li, X. Li, D . Ma, S. Narang, A. Ng, S. Ozair , Y . Peng, R. Prenger , S. Qian, Z. an, J. Raiman, V . Rao, S. Sathe esh, D. Seetapun, S. Sengupta, K. Srinet, A. Sriram, H. T ang, L. T ang, C. W ang, J. W ang, K. W ang, Y . W ang, Z. W ang, Z. W ang, S. Wu, L. W ei, B. Xiao, W . Xie, Y . Xie, D . Y ogatama, B. Y uan, J. Zhan, and Z. Zhu, “Deep spee ch 2 : End-to-end spee ch recognition in english and mandarin, ” in Proceedings of The 33rd International Con- ference on Machine Learning (M. F. Balcan and K. Q. W einberger , eds.), vol. 48 of Procee dings 11 of Machine Learning Research , (New Y ork, New Y ork, USA), pp. 173–182, PMLR, 20–22 Jun 2016. [9] S. T . Ishikawa and V . C. Gulick, “ An automated mineral classifier using raman spe ctra, ” Comput. Geosci. , vol. 54, pp. 259–268, Apr . 2013. [10] C. Carey , T . Boucher , S. Mahadevan, P. Bartholomew , and M. Dyar , “Machine learning to ols for mineral recognition and classification from raman spectroscopy , ” Journal of Raman Spe c- troscopy , v ol. 46, no. 10, pp. 894–903, 2015. [11] A. Goss and M. Adams, “Spectral retrieval by fuzzy matching, ” in A nalytical Procee dings including A nalytical Communications , vol. 31, pp. 23–25, Royal Society of Chemistry , 1994. [12] Z.-M. Zhang, X. T ong, Y . Peng, P . Ma, M.-J. Zhang, H.-M. Lu, X.-Q. Chen, and Y .-Z. Liang, “Multiscale peak detection in wavelet space, ” A nalyst , vol. 140, no. 23, pp . 7955–7964, 2015. [13] H.- Y . Fu, J.- W . Guo, Y .-J. Y u, H.-D. Li, H.-P . Cui, P.-P . Liu, B. W ang, S. W ang, and P. Lu, “ A simple multi-scale gaussian smoothing-based strategy for automatic chromatographic peak extraction, ” Journal of Chromatography A , vol. 1452, pp. 1–9, 2016. [14] X. T ong, Z. Zhang, F . Zeng, C. Fu, P. Ma, Y . Peng, H. Lu, and Y . Liang, “Recursive wavelet peak detection of analytical signals, ” Chromatographia , vol. 79, no. 19-20, pp. 1247–1255, 2016. [15] T . Vignesh, S. Shanmukh, M. Y arra, E. Botonjic-Sehic, J. Grassi, H. Boudries, and S. Dasaratha, “Estimating probabilistic confidence for mixture components identifie d using a spectral search algorithm, ” A pplied sp ectroscopy , v ol. 66, no. 3, pp. 334–340, 2012. [16] Z.-M. Zhang, X.-Q. Chen, H.-M. Lu, Y .-Z. Liang, W . Fan, D . Xu, J. Zhou, F. Y e, and Z.- Y . Y ang, “Mixture analysis using reverse searching and non-negative least squares, ” Chemometrics and Intelligent Laborator y Systems , vol. 137, pp . 10–20, 2014. [17] J. Bromley , I. Guyon, Y . LeCun, E. Säckinger , and R. Shah, “Signature verification using a "siamese " time delay neural network, ” in Proceedings of the 6th International Conference on Neural Information Processing Systems , NIPS’93, pp. 737–744, 1993. [18] S. Chopra, R. Hadsell, and Y . LeCun, “Learning a similarity metric discriminatively , with application to face verification, ” in Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Paern Recognition (CVPR’05) - V olume 1 - V olume 01 , CVPR ’05, (W ashington, DC, USA), pp. 539–546, IEEE Computer Society , 2005. [19] Y . T aigman, M. Y ang, M. Ranzato, and L. W olf, “Deepface: Closing the gap to human-level performance in face verification, ” in Procee dings of the 2014 IEEE Conference on Computer Vision and Paern Recognition , CVPR ’14, pp. 1701–1708, 2014. 12 [20] F. Schro, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recog- nition and clustering, ” in 2015 IEEE Conference on Computer Vision and Paern Re cognition (CVPR) , pp. 815–823, 2015. [21] C. A. Aguilera, F. J. Aguilera, A. D . Sappa, C. Aguilera, and R. T oledo, “Learning cross-spectral similarity measures with deep convolutional neural networks, ” in 2016 IEEE Conference on Computer Vision and Paern Recognition W orkshops (CVPRW) , 2016. [22] K. Chen and A. Salman, “Extracting sp eaker-specific information with a regularized siamese deep network, ” in Advances in Neural Information Processing Systems 24 ( J. Shawe- T aylor , R. S. Zemel, P . L. Bartle, F. Pereira, and K. Q . W einb erger , eds.), pp. 298–306, 2011. [23] Z. Lu and H. Li, “ A deep architecture for matching short texts, ” in Advances in Neural Infor- mation Processing Systems 26 (C. J. C. Burges, L. Boou, M. W elling, Z. Ghahramani, and K. Q . W einberger , e ds.), pp. 1367–1375, 2013. [24] G. Koch, R. Zemel, and R. Salakhutdinov , “Siamese neural networks for one-shot image recognition, ” 2015. [25] Y . Lecun, L. Boou, Y . Bengio, and P. Haner , “Gradient-base d learning applied to do cument recognition, ” in Procee dings of the IEEE , pp. 2278–2324, 1998. [26] N. V . Chawla, K. W . Bowyer , L. O . Hall, and W . P. Kegelmey er , “Smote: Synthetic minority over-sampling te chnique, ” Journal of A rtificial Intelligence Research , vol. 16, pp . 321–357, 2002. [27] D. Kingma and J. Ba, “ Adam: A metho d for stochastic optimization, ” arXiv pr eprint arXiv:1412.6980 , 2014. [28] B. Lafuente, R. T . Downs, H. Y ang, and N. Stone, “The p ower of databases: the rru project, ” Highlights in Mineralogical Crystallography , pp. 1–30, 2015. [29] P. H. C. Eilers and H. F . Boelens, “Baseline correction with asymmetric least squares smoothing, ” tech. rep ., Leiden University Medical Centre, Oct 2005. [30] K. Q . W einb erger and L. K. Saul, “Distance metric learning for large margin nearest neighbor classification, ” J. Mach. Learn. Res. , vol. 10, pp. 207–244, June 2009. [31] L. van der Maaten and G. Hinton, “Visualizing high-dimensional data using t-sne, ” 2008. 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment