Multiple Scattering Media Imaging via End-to-End Neural Network
Recovering the image of an object from its phaseless speckle pattern is difficult. Let alone the transmission matrix is unknown in multiple scattering media imaging. Double phase retrieval is a recently proposed efficient method which recovers the un…
Authors: Ziyang Yuan, Hongxia Wang
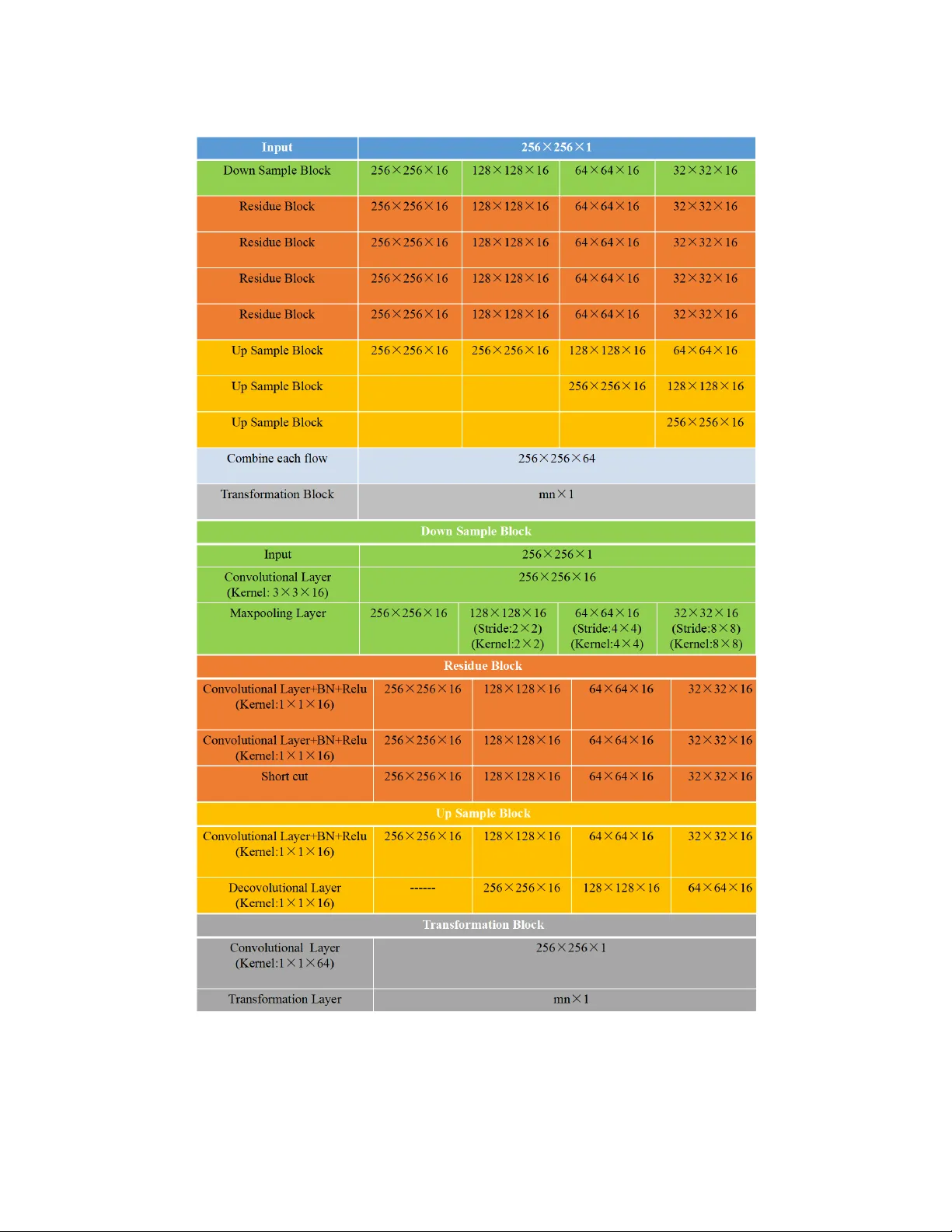
Multiple Scattering Media Imaging via End-to-End Neural Net w ork Ziy ang Y uan ∗ Hongxia W ang † Abstract Reco vering the image of an ob ject from its phaseless speckle pattern is difficult. Let alone the transmission matrix is unkno wn in multiple scattering media imaging. Double phase retriev al is a recently prop osed efficient metho d whic h recov ers the unknown ob ject from its phaseless measuremen ts b y t wo steps with phase retriev al. In this pap er, we combine the tw o steps in double phase retriev al and construct an end-to- end neural netw ork called TCNN(T ransforming Conv olutional Neural Netw ork) whic h directly learns the relationship b etw een the phaseless measurements and the ob ject. TCNN contains a special lay er called transform la yer which aims to b e a bridge b etw een different transform domains. T ested by the empirical data pro vided in[1], images can b e reco vered by TCNN with comparable quality compared with state-of-the-art metho ds. Not only the transmission matrix needn’t to be calculated but also the time to recov er the ob ject can be hugely reduced once the parameters of TCNN are stable. Keyw ords : neural net work, phase retriev al, multiple scattering media, end-to-end 1 In tro duction The light incident on the multiple scattering media will suffer from m ultiple reflection. Th us when observing the ob ject through the m ultiple scattering media with coherent ligh t, the sp eckle pattern display ed on the far side of the scatter isn’t similar with the ob ject which can b e seen from Figure 1. Because the wa v efront in terferences with itself destructiv ely when passing through the m ultiple scattering media, many details ab out the ob ject get lost. At the same time, the transmis- sion matrix about this complex media is hard to be analyzed and constructed. Moreo ver, the detec- tor such as CMOS or CCD can only record the intensit y of the sp ec kle pattern. As is w ell kno wn, reco vering the ob ject from its phaselesss measurements called phase retriev al is an ill-p osed inv erse problem. Overall, it’s hard to recov er image of the ob ject from m ultiple scattering media. Consid- ering the imp ortance of this problem in applications, there are a batch of tec hniques to deal with it such as TOF(Time of Fligh t) metho d[2], m ulti-slice ligh t-propagation metho d[3], strong mem- ory effect metho d[4], holographic in terferometry method[5], temp orally mo dulated phase metho d[6] and double phase retriev al metho d[7][8]. In terested readers can refer to [1] for a review. Comparing to other metho ds, the double phase retriev al metho d can alleviate from the depth ∗ Departmen t of Mathematics, National Univ ersit y of Defense T echnology , Changsha, Hunan, 410073, P .R.China. Corresp onding author. Email: yuanziyang11@nudt.edu.cn † Departmen t of Mathematics, National Univ ersit y of Defense T echnology , Changsha, Hunan, 410073, P .R.China. Email: wanghongxia@nudt.edu.cn 1 Figure 1: The paradigm of the pro cedure. and complexities of the scatterer b esides this metho d is able to reconstruct image after captur- ing only a single sp eckle pattern once the transmission matrix is estimated. The mathematical form ulation of double phase retriev al is: Find A , x s.t. | A ∗ x | 2 = b , (1.1) where A ∈ C n × m is the transmission matrix, x ∈ C n is the signal of in terest. b is the measuremen t, ∗ is the conjugate and transp ose. |· | is the elemen t-wise absolute. The double phase retriev al metho d has tw o main steps: estimating A firstly , then recov ering x based on A from the first step. As its name suggested, the core of double phase retriev al is to solve several phase retriev al problems. Phase retriev al, namely reco vering the ob ject from the phaseless measuremen ts whic h arises from lots of applications suc h as holographic imaging, coheren t diffraction imaging and astronom y ,etc. The mathematical formulation of phase retriev al is same with formula (1.1), but the transmission matrix A is known in adv ance. The uniqueness of the problem is often up to a global phase factor. During sev eral decades, lots of theoretical analyses and numerical algorithms ha v e come up to solve the phase retriev al problem. Gerch berg and Saxton method [9]and Fien up metho d [10] are the t wo types of classical alternating metho ds to find the solutions of phase retriev al problem. They ha ve b een utilized in v arious of applications. In [11], it came up with a gradient descent based metho d called Wirtinger flow to search for the solutions of the non-con vex problem. Theoretical analyses also guaran tee the conv ergence to the global optimum when each column of A satisfies a i i.i.d ∼ N ( 0 , I ) , i = 1 , · · · , m . Based on this, sev eral works were came up to decrease the sampling complexit y b esides increasing the recov ery probability . Con vex relaxation can also be utilized to relief the phase retriev al problem. Phaselift and Phasemax are the tw o differen t representativ es of con vex methods for dimension lifting and constraints relaxation[12][13][14]. In theoretical analyses, when m ≥ 2 n − 1 or m ≥ 4 n − 4 , uniqueness can b e guaran teed for phase retriev al when A is real or generic complex[15][16]. At the same time, ov ersampling can relief the illness of phase retriev al problem and impro ve the p erformance of corresp onding algorithms by numerous numerical tests. 2 The double phase retriev al can also be called blind phase retriev al. In this case, the transmission matrix A and x is unknown. The condition of it is worse than phase retriev al. As a result, in the first step, A will b e ev aluated from k kno wn images x ( i ) , i = 1 , · · · , k and their corresp onding kno wn intensit y measurements b ( i ) , i = 1 , · · · , k . In this circumstance, the mo del can b e defined as b elo w: Find A s.t. | A ∗ x ( i ) | 2 = b ( i ) , i = 1 , · · · , k . (1.2) As a result, define X = [ x (1) , x (2) , · · · , x ( k ) ], B = [ b (1) , b (2) , · · · , b ( k ) ], each column of A namely a j can b e estimated accurately through a series of phase retriev al problems. Find a j s.t. | X ∗ a j | 2 = B ∗ j , j = 1 , · · · , m, where B ∗ j is the j th column of B ∗ . After obtaining the ev aluation of A , utilizing standard phase retriev al metho ds mentioned ab ov e, the unknown x can b e recov ered from its measurements b . In [1], they built up different exp erimental setups to apply multiple-scatter media imaging, then utilizing the double phase retriev al metho d based on differen t phase retriev al algorithms to recov er the image. Numerous tests show the go o d p erformance and robustness of this metho d. Though the double phase retriev al metho d is efficient, it costs lots of computational resources to solve series of phase retriev al problem. It must ev aluate the transmission matrix A firstly whic h demands plent y of training data and the large computational burdens for solving phase retriev al problem. In the second step, solving the classical phase retriev al metho d also needs to o muc h computational cost. Besides it seems a little complicated to solv e the problem in tw o steps. Thus time sav ed, explicit and efficient metho d need to b e devised. Deep learning has reac hed muc h atten tion since Alexnet won the champion in the ISVRC 2012. Since then, lots of la yer structures and optimization metho ds camp up to accelerate the developmen t of deep neural netw ork. With the aid of the hardwares such as GPU and series of famous op en access pro jections such as T ensorflow, Pytorch and Caffe, deep learning hav e b een successfully applied in Ob ject detection, autonomous vehicles, Signal pro cessing such as V oice detection and V oice syn thetic, in verse problem suc h as MRI[17], holography[18] and sup er-resolution[19]. F or phase retriev al, there are some previous w orks which also utilize the neural netw ork to increase the imaging quality . In [20], they built a neural netw ork to diminish the effect of the twin image. Compared to the classical metho ds, this neural net work only requires the measurements obtained in a single distance besides ha ving a competitive p erformance. In [21], it also came up with a neural work to increase the resolution of the image in lensless coherent diffraction image. This neural netw ork is also an end-to-end neural net work which can directly transform the diffraction pattern into the image. Compared to those works ab o ve, the transmission media in our test is worse b esides the sp eckle pattern bear no resem blance to the image. Those factors make it more difficult to recov er the ob ject for neural net work. In this pap er, we combine tw o steps in double phase retriev al together b y deep neural netw ork called TCNN(T ransformation Conv olution Neural Netw ork) to directly learn the relationship b etw een the intensit y of the sp eckle pattern and the image of ob ject. Applying TCNN in to multiple-scatter media imaging, what w e need do is to train the neural net work which fully utilizes the training sets of double phase retriev al metho d in the first step. Once the training of 3 net work is finished, the reco vered image can b e obtained immediately by inputting the intensit y of sp eckle pattern into neural netw ork without calculating the transmission matrix. T ests using the m ultiple-scattering-media imaging data in [1] demonstrate that TCNN can hav e a comp etitiv e p erformance with the state-of-the-art. When the training pro cedure of TCNN has b een completed, the time required by TCNN is muc h less than state-of-art for solving the phase retriev al problem when A is estimated. Besides, TCNN can b e refined based on the w ell-trained netw ork if more training data is a v ailable. But double phase retriev al metho d has to b e calculated from all the training data again so that the transmission matrix can b e up dated. TCNN is a sp ecial netw ork whic h is devised to solve the in v erse problem. Th us special structure called transforming la yer is constructed in TCNN whic h can help the neural net work learn the relationship b etw een the transforming domain and ob ject domain so that TCNN can recov er the image efficiently . The reminders of this pap er are organized as b elo w. In section 2, the details of the exp eriment setup and TCNN are giv en. In section 3, the results of the exp erimen t for TCNN are giv en. Section 4 is the conclusion. 2 The feasible of neural net w ork for solving double phase retriev al Before we describ e TCNN, the feasible analyses of neural netw ork to solve double phase retriev al is built. Neural netw ork wan ts to approximate function g so that x can b e estimated directly from b . g Θ : b → x , (2.1) where Θ is the set of parameters in the neural netw ork which are learned via enough kno wn b and x . Initially , the existence of the op erator g must b e discussed. The op erator f : x → b must b e injective or g doesn’t exist, where ( f ( x ))( i ) = | a ∗ i x | 2 . W e can clearly see that when x ∈ R n , f ( x ) = f ( − x ) b esides if x ∈ C n , f ( x ) = f ( c x ), | c | = 1. As a result, the injective of f can b e satisfied only if x defined up to a global phase factor. Thus w e consider the map f : R n / {± 1 } → R m when x is real, f : C n / T → R m when x is complex(where T is the complex unit circle). Next we introduce the theorem b elo w to guarantee the injective of f . Theorem 2.1. [15] Assuming ther e is no noise, a j , j = 1 , · · · , m ar e generic fr ame ve ctors, when a j ∈ R n , x ∈ R n or a j ∈ C n , x ∈ C n , if m ≥ 2 n − 1 or m ≥ 4 n − 2 , f is inje ctive. Because the ligh t passing through the multiple-scattering media which ma y b e frost glass or pain ted wall. In classical analyses, the rows of transmission matrix A of those media are often assumed satisfying the gaussian or sub-gaussian distribution whic h are generic vectors. So the prop ert y of transmission matrix in Theorem 2.1 can b e satisfied. Before training the netw ork, it m ust sift the dataset so that ev ery b ( i ) , i = 1 , · · · , k is different to guarantee injectiv e. No w that the existence of the inv erse function g is guaranteed. As a result, we can build up the univ ersality theorem b elow: Theorem 2.2. If the inverse function g of phase r etrieval f ( f : R n / {± 1 } → R m or f : C n / T → R m ) exists, then g c an b e appr oximatd by g Θ with any desir e d de gr e e of ac cur acy. Pro of. When x ∈ R n , f : x → b is a contin uous and b orel measurable function. As a result, if g exists, g is also a b orel measurable function. Utilizing the universalit y theorem in [22], g can b e 4 Figure 2: The features learned in TCNN. appro ximated b y g Θ with squashing functions to any desired degree of accuracy as if hidden units are sufficient. When x ∈ C n , we split x into tw o parts x 1 and x 2 uniquely whic h satisfy x 1 + j x 2 = x where j = √ − 1. Because g exists, as a result, let g (1) = ( g + g ) / 2, g (2) = ( g − g ) j / 2, so g (1) ( b ) = x 1 , g (2) ( b ) = x 2 . Because g (1) and g (2) are all b orel measurable function. Thus, utilizing the results when x ∈ R n , g (1) and g (2) can b e appro ximated b y g (1) Θ and g (2) Θ . So x ≈ g (1) Θ ( b ) + j g (2) Θ ( b ). Ab o ve all, utilizing the univ ersality of neural netw ork, when the training set is in R n / {± 1 } or C n / { T } , it is p ossible to train a neural netw ork to approximate this inv erse function g . In this pap er, we build a neural netw ork called TCNN to train g Θ from dataset. The core of TCNN is to utilize t wo sections g Θ 1 and g Θ 2 to appro ximate the inv erse function g which can simulate the imaging pro cedure in multiple scattering media, namely , g ( b ) ≈ g Θ ( b ) = g Θ 2 ( g Θ 1 ( b )) . (2.2) F or g Θ 1 , features of intensit y of sp eckle patterns b are learned from differen t scales which can b e seen from Figure 2. W e can see that the details from differen t scales of sp eckle pattern are learned(the features in Figure 2 are resized to keep the same). Then deconv olution pro cedures deco de those features into a new element g Θ 1 ( b ) in the transform domain so that it can b e approximated to x b y linear transform g Θ 2 . The diagram of TCNN can b e viewed in App endix. The multiple flo w structure is utilized in TCNN which can learn the features of the input in differen t scales. The input of neural netw ork is decimated by the downsample Blo ck which is constructed by one con volutional lay er with batch normalization, Relu activ ation function and one 5 maxp o oling la yer. The maxp o oling lay er here decreases the dimension of the input. Sp ecifically the input is do wnsampled b y × 2, × 4, × 8 respectively . Then, the four different tensors will be successiv ely passed through five r esidue blo cks , eac h blo ck contains t wo con volutional lay ers with batc h normalization and a shortcut b etw een the input and output of the block. The shortcut can accelerate the con vergence of TCNN. After the five r esidue blo cks , the high order features in differen t scales are learned. Then, we will deco de those features to generate four differen t tensors k eeping the same size with the input. So there will b e 3 , 2 , 1 upsampling blo cks for each tensors resp ectiv ely . In each upsample blo ck , there will b e one conv olutional la yer with batc h normalization and one decon volutional lay er. The deconv olution in this pap er adopts the wa y of upsampling in [20] for sup er-resolution. Because this method can alleviate the effect of zero padding b y traditional decon volution b esides fully utilizing the information in the netw ork. After those upsample blo cks , the fused tensor is obtained which will pass through the tr ansformation blo ck instituted b y one con volutional la yer and transformation la yer. The transformation lay er is in fact a full connection la yer which acts as a linear transformation b etw een the transform domain and ob ject domain. In the test, to alleviate the influence of ov er-fit, the units in transformation la yer are randomly neglected. The details of TCNN can b e found in App endix. 3 The test of empirical data The exp erimen t setup display ed in this pap er is made by Rice Universit y in [1]. Here, w e only displa y the exp eriment setup for phase only SLM. As shown in Figure 3, a spatially filtered and collimated laser b eam( λ = 632 . 8 nm ) illuminates an SLM from Holoeye. It is a reflective type displa y(LC2012) with 1024 × 768 resolution and 36 micrometer size square pixels. It can mo dulates the phase of the b eam before the lens L ( f = 150 mm ), this lens can fo cus the beam onto the scattering medium whic h is a holographic 5 degree diffuser from Thorlabs. Then a microscop e ob jectiv e(Newp ort, X10, NA:0.25) is used to image the SLM calibration pattern on to the sensor whic h is the Poin t Grey Grasshopp er 2 with pixel size 6.45 micrometer. Because the phase only SLM is 8 bit, it mo dulates the w av efron t b y an element of { e 0 , e 2 π j 1 256 , · · · , e 2 π j 255 256 } . In the test, the phase mo dulation is restricted to { 0 , π } , which means the v alue of the x is {− 1 , 1 } . F or the amplitude only SLM, set the source pixel as either completely off, 0 , or completely on ,1. then the v alue of x is { 0 , 1 } . F or the details of the exp erimental setup, readers can refer to [1]. The test data can b e download from https://rice.app.box.com/v/TransmissionMatrices . Tw o t yp es of the data are utilized in the exp erimen t. F or amplitude only SLM, the size of the image is 16 × 16 or 64 × 64. F or the phase only SLM, the size of the image is 40 × 40. Exp eriments are applied on desktop computer with GPU NVIDIA 1080 and the CUDA edition is 9.0. Some hyper parameters of the test can b e found in T able 1. W e imply TCNN using deep learning framework tensorflo w. The loss function is chosen as the mean squared error(MSE) betw een the outputs of TCNN and corresp onding b enc hmarks in the training set. The weigh ts of TCNN are trained b y the back propagation using ADAM. The initial learning rate of ADAM is 10 − 3 whic h decays with the factor of 0 . 85 after each ep o ch. The total num b er of ep o c h of the training procedure is 100. T o prepro cess the data in this exp erimen t, w e firstly sift the data so that every image and corresp onding sp eckle pattern is unique. Then we trained TCNN for three different sizes of data. W e compare TCNN with state-of-the-arts in literature such as GS[9], WF[11], PhaseLift[12], Prv amp[1]. TCNN can directly recov er images from those sp eckle patterns without estimating the transmission matrix. F or other metho ds, we utilize the transmission matrix A obtained b y Prv amp 6 Figure 3: Experimental setup with phase only SLM[1] for phase retriev al. The results are shown in Figure 4 and Figure 5. T able 1: Some hyper parameters in TCNN 16 × 16 40 × 40 64 × 64 The num b er of the training sets 3050 3050 35000 The num b er of the v alidation sets 22 20 200 The num b er of test sets 5 5 6 F rom Figure 4 and Figure 5 w e can observe that pictures reco vered by TCNN are comp etitiv e with state-of-arts. It can recov er the outline of the ob ject although some details are lost just like other metho ds. In fact, it is v ery hard to reco ver those images with high qualit y from sp eckle patterns. Because multiple scattering media deteriorates the imaging pro cedure b esides the phase information lost b y CCD is imp ortant to recov er image. Moreo ver, the noise and system error also exist in the exp eriment. But T able 1 shows the time cost b y TCNN is far less than other metho ds. It can sav e the time at least ten folds ev en 100 folds when 64 × 64 whic h demonstrates the adv antages of TCNN to realize real time imaging. Moreov er TCNN only p erforms an end-to- end recov ery but other metho ds must estimate the transformation matrix in adv ance then getting the ev aluation by phase retriev al. Thus, exp eriments ab ov e fully illustrates the p ow er of TCNN to reco ver the image from the intensit y of sp eckle pattern. During the training step, the training error and v alidation error of amplitude only SLM 16 × 16 are given in Figure 6. Considering the large quantities of training set, training error is the MSE of one of the input in training se t by random so there is some oscillations for training error. The v alidation error is the mean MSE for the v alidation set. F rom Figure 6, w e can find the solution quic kly conv erges to the lo cal optimum, after 20 ep o c hs, there is little fluctuation for b oth errors. Besides the v alidation error is very close to the training error whic h fully demonstrates the influence 7 Figure 4: The reconstruction of v arious metho ds for amplitude only SLM with image size 16 × 16 8 Figure 5: The reconstruction of v arious metho ds for phase only SLM with image size 40 × 40 9 Figure 6: The training error and v alidation error of ov er-fit got con trolled. T able 2: Time cost p er image b y different metho ds 16 × 16 40 × 40 64 × 64 Time(s) iteration Time(s) iteration Time(s) iteration WF 4 . 11 100 19 . 49 100 289 . 03 100 GS 3 . 86 100 18 . 86 100 43 . 48 100 PhaseLift 239 . 50 100 — 500 — 1000 PR V AMP 3 . 41 100 17 . 40 100 44 . 52 100 TCNN 0 . 103 — 0 . 117 — 0 . 121 — 4 Conclusion In this pap er, we build a deep neural netw ork called TCNN to directly transform the intensit y of the sp ec kle pattern via the multiple scattering media to the ob ject. Compared to the traditional double phase retriev al metho d, this end-to-end net work don’t need to model this imaging procedure and calculate the transformation matrix. Instead, it needs plent y of training data which includes the original images and corresp onding intensit y of sp eckle patterns to up date the parameters of TCNN. This training pro cedure can be done in adv ance. Compared to state-of-the-arts, the reco ver qualit y of TCNN is comp etitive but the time TCNN cost is m uc h less sp ecifically recov ering p er image needs no more than 1s. In TCNN, we build t wo sections to approximate the in verse function. The nonlinear part encodes the information of the in tensity of the sp eckle pattern b esides deco ding it in to a new element in transform domain, then the linear part transforms this element into the output in ob ject domain. T est demonstrates the effectiveness of the arc hitecture of TCNN b esides tricks utilized in TCNN to alleviate the ov er-fit of netw ork. In the future, the work is to decrease the num b er of parameters in TCNN. Esp ecially for the parameters in the transformation lay er, they occupy large p ortions of the whole parameters. W e 10 consider fuse it implicitly into the con volutional la yers where the parameters are comparatively less. 5 Ac kno wledgement This work w as supp orted in part by National Natural Science foundation(China): 61571008. References [1] Christopher A. Metzler, Mano j K. Sharma, Sudarshan Nagesh, Richard G. Baraniuk, Oliv er Cossairt, and Ashok V eeraragha v an. Coheren t inv erse scattering via transmission matrices: Efficien t phase retriev al algorithms and a public dataset. In IEEE International Confer enc e on Computational Photo gr aphy , pages 1–16, 2017. [2] A V elten, T Willw acher, O Gupta, A V eeraraghav an, M. G. Ba wendi, and R Rask ar. Reco v- ering three-dimensional shap e around a corner using ultrafast time-of-fligh t imaging. Natur e Communic ations , 3(2):745, 2012. [3] Laura W aller and Lei Tian. 3d intensit y and phase imaging from ligh t field measurements in an led arra y microscop e. Optic a , 2(2):104, 2015. [4] I I F reund, M Rosen bluh, and S. F eng. Memory effects in propagation of optical w av es through disordered media. Physic al R eview L etters , 61(20):2328–2331, 1988. [5] S. M. Popoff, G Lerosey , R Carminati, M Fink, A. C. Bo ccara, and S Gigan. Measuring the transmission matrix in optics: an approac h to the study and control of ligh t propagation in disordered media. Physic al R eview L etters , 104(10):100601, 2010. [6] M. C ui. P arallel wa vefron t optimization metho d for fo cusing ligh t through random scattering media. Optics L etters , 36(6):870, 2011. [7] Anglique Drmeau, Antoine Liutkus, Christophe Sc hlke, Da vid Martina, Floren t Krzak ala, Lauren t Daudet, Ori Katz, and Sylv ain Gigan. Reference-less measuremen t of the transmission matrix of a highly scattering material using a dmd and phase retriev al tec hniques. Optics Expr ess , 23(9):11898, 2015. [8] Boshra Ra jaei, Eric W. T ramel, Sylv ain Gigan, Florent Krzak ala, and Laurent Daudet. In tensity-only optical compressive imaging using a m ultiply scattering material and a dou- ble phase retriev al approach. In IEEE International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing , pages 4054–4058, 2016. [9] R. W. Gerc hberg. A practical algorithm for the determination of phase from image and diffraction plane pictures. Optik , 35:237–250, 1971. [10] J R Fien up. Phase retriev al algorithms: a comparison. Applie d Optics , 21(15):2758–2769, 1982. 11 [11] Emman uel J Candes, Xiao dong Li, and Mahdi Soltanolkotabi. Phase retriev al via wirtinger flo w: Theory and algorithms. IEEE T r ansactions on Information The ory , 61(4):1985–2007, 2015. [12] Emman uel J. Cands, Thomas Strohmer, and Vladisla v V oroninski. Phaselift: Exact and stable signal recov ery from magnitude measurements via conv ex programming. Communic ations on Pur e and Applie d Mathematics , 66(8):12411274, 2013. [13] T om Goldstein and Christoph Studer. Phasemax: Con v ex phase retriev al via basis pursuit. arXiv pr eprint arXiv:1610.07531 , 2016. [14] Sohail Bahmani and Romberg Justin. Phase retriev al meets statistical learning theory: A flexible conv ex relaxation. arXiv pr eprint arXiv:1610.04210 , 2016. [15] Radu Balan, Pete Casazza, and Edidin Dan. On signal reconstruction without phase . Applie d and Computational Harmonic Analysis , 20(3):345–356, 2006. [16] Afonso S. Bandeira, Jameson Cahill, Dustin G. Mixon, and Aaron A. Nelson. Saving phase: Injectivit y and stability for phase retriev al. Applie d and Computational Harmonic Analysis , 37(1):106–125, 2013. [17] Shanshan W ang, Zhenghang Su, Leslie Ying, Xi P eng, Shun Zhu, F eng Liang, Dagan F eng, and Dong Liang. Accelerating magnetic resonance imaging via deep learning. In IEEE International Symp osium on Biome dic al Imaging , pages 514–517, 2016. [18] Y Jo, S Park, J Jung, J Y o on, H Jo o, M. H. Kim, S. J. Kang, M. C. Choi, S. Y. Lee, and Y P ark. Holographic deep learning for rapid optical screening of anthrax sp ores. Scienc e A dvanc es , 3(8):e1700606, 2017. [19] C. Dong, C. C. Loy , K. He, and X. T ang. Image sup er-resolution using deep conv olutional net works. IEEE T r ans Pattern Anal Mach Intel l , 38(2):295–307, 2016. [20] Y air Rivenson, Yib o Zhang, Harun Gna ydn, Da T eng, and Aydogan Ozcan. Phase recov ery and holographic image reconstruction using deep learning in neural netw orks. Light Scienc e and Applic ations , 7(2), 2017. [21] Ay an Sinha, George Barbastathis, Justin Lee, and Sh uai Li. Lensless computational imaging through deep learning. Optic a , 4(9), 2017. [22] Kurt Hornik, Maxwell Stinchcom b e, and Halb ert White. Multilay er feedforw ard netw orks are univ ersal appro ximators. Neur al Networks , 2(5):359–366, 1989. 6 App endix 12 Figure 7: The paradigm of TCNN. 13 Figure 8: The details of TCNN 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment