Multi-target Voice Conversion without Parallel Data by Adversarially Learning Disentangled Audio Representations
Recently, cycle-consistent adversarial network (Cycle-GAN) has been successfully applied to voice conversion to a different speaker without parallel data, although in those approaches an individual model is needed for each target speaker. In this paper, we propose an adversarial learning framework for voice conversion, with which a single model can be trained to convert the voice to many different speakers, all without parallel data, by separating the speaker characteristics from the linguistic content in speech signals. An autoencoder is first trained to extract speaker-independent latent representations and speaker embedding separately using another auxiliary speaker classifier to regularize the latent representation. The decoder then takes the speaker-independent latent representation and the target speaker embedding as the input to generate the voice of the target speaker with the linguistic content of the source utterance. The quality of decoder output is further improved by patching with the residual signal produced by another pair of generator and discriminator. A target speaker set size of 20 was tested in the preliminary experiments, and very good voice quality was obtained. Conventional voice conversion metrics are reported. We also show that the speaker information has been properly reduced from the latent representations.
💡 Research Summary
The paper addresses two major challenges in voice conversion (VC): the need for parallel training data and the requirement of a separate model for each target speaker. While recent works such as Cycle‑GAN have demonstrated non‑parallel VC, they still train one model per target speaker. The authors propose a unified adversarial learning framework that can convert an utterance to any of a set of target speakers using a single model, without any parallel data.
The approach consists of two training stages. In Stage 1, an autoencoder (AE) learns to separate speaker‑independent linguistic content from speaker identity. The encoder maps an input spectrogram x to a latent representation enc(x). A classifier‑1 (C1) is attached to the latent space and is trained to predict the speaker label from enc(x). Simultaneously, the encoder is trained adversarially to maximize the classification loss, thereby forcing enc(x) to discard speaker information. The decoder receives both enc(x) and the original speaker embedding y and reconstructs the input spectrogram, minimizing a mean‑absolute‑error (MAE) reconstruction loss. This yields a speaker‑independent content vector that can be recombined with any target speaker embedding y₀ to produce a basic conversion output V₁(x, y₀)=dec(enc(x), y₀).
Stage 2 addresses the over‑smoothness that typically arises from reconstruction‑only training. A separate generator (G) takes the fixed encoder output enc(x) and a target speaker embedding y₀ and predicts a residual (fine‑structure) signal. The final output is V₂ = V₁ + G(enc(x), y₀). G is trained against a discriminator‑plus‑classifier‑2 (D+C2) in a WGAN‑GP setting. The discriminator distinguishes real spectrograms from generated ones (adversarial loss L_adv), while classifier‑2 predicts the speaker identity of both real and generated samples (cross‑entropy loss L_d_cls2). The generator is additionally encouraged to produce samples that classifier‑2 assigns to the intended target speaker (loss L_g_cls2). Consequently, the residual generator injects realistic high‑frequency details and reinforces the target speaker characteristics.
Implementation details: the network follows the CBHG architecture (convolution banks, highway layers, bidirectional GRU). 1‑D convolutions are used throughout except for the discriminator, which employs 2‑D convolutions to capture texture. Speaker embeddings are added element‑wise at multiple layers. Dropout (0.5 in encoder, 0.3 in classifier) provides regularization. The λ weight for the adversarial classification loss in Stage 1 is linearly increased from 0 to 0.01 over the first 50 k mini‑batches to avoid destabilizing reconstruction early on.
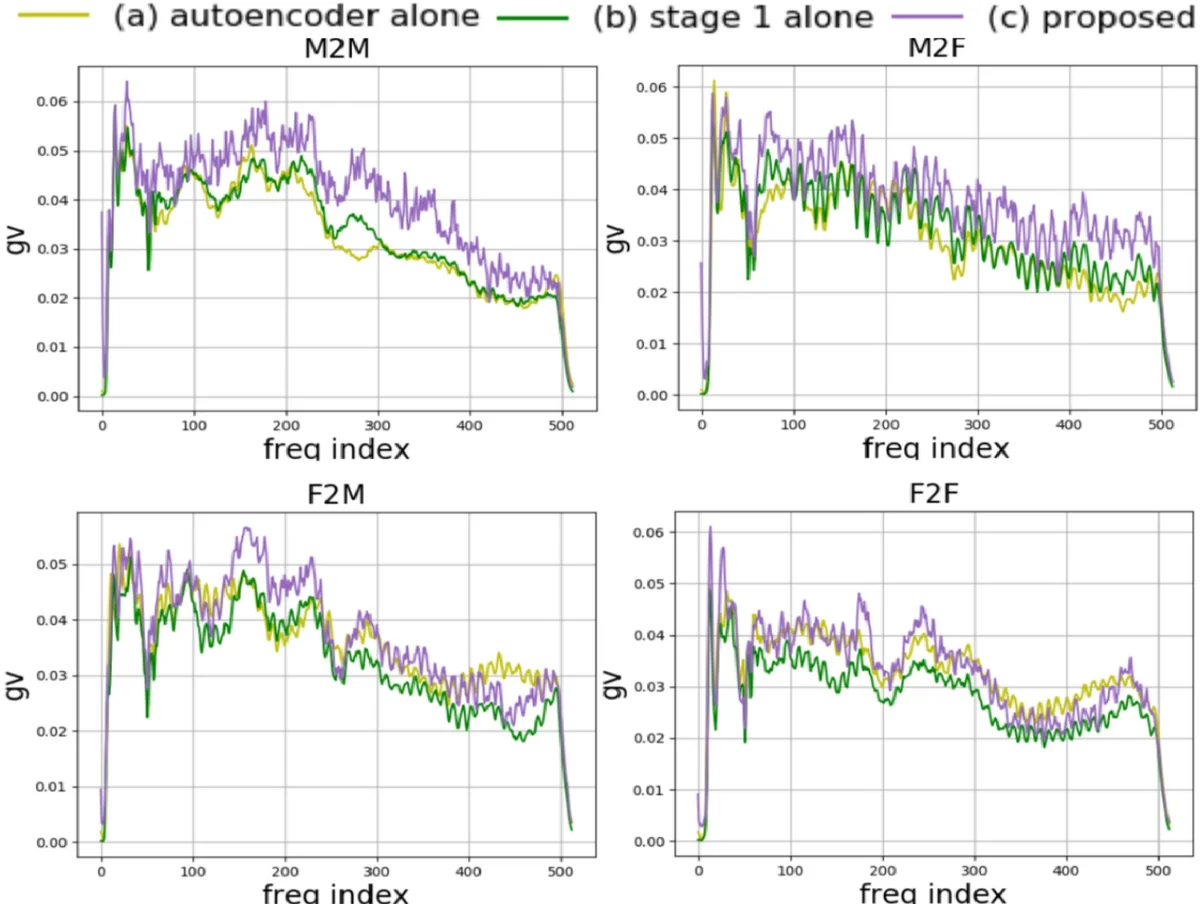
Experiments were conducted on a subset of 20 speakers (10 male, 10 female) from the VCTK corpus. Objective evaluation used Global Variance (GV) of the generated spectrograms, a metric that reflects spectral sharpness and mitigates over‑smoothing. GV was computed for four conversion scenarios (M→M, M→F, F→M, F→F). Results show a clear progression: the plain autoencoder (no C1) yields the lowest GV, adding classifier‑1 improves GV, and the full two‑stage system achieves the highest GV across all scenarios. Subjective listening tests with 20 participants compared (a) the full system versus Stage 1 only, and (b) the full system versus a Cycle‑GAN‑VC baseline. Listeners consistently preferred the proposed method in terms of naturalness and similarity to the target speaker’s voice.
Key contributions:
- An adversarially regularized autoencoder that extracts speaker‑independent linguistic representations without heuristic constraints.
- A residual GAN that refines the decoder output, restoring fine spectral details and enhancing speaker fidelity.
- Demonstration that a single model can handle many target speakers (20 in the experiments) in a non‑parallel setting, reducing model count and training cost.
Limitations include evaluation on a relatively small speaker set and the lack of real‑time inference analysis. Future work could scale to larger speaker pools, explore low‑latency architectures, and test the approach on other voice attributes such as emotion or accent. Overall, the paper presents a compelling, well‑engineered solution that advances the state of the art in multi‑target, non‑parallel voice conversion.
Comments & Academic Discussion
Loading comments...
Leave a Comment