Metadata Enrichment of Multi-Disciplinary Digital Library: A Semantic-based Approach
In the scientific digital libraries, some papers from different research communities can be described by community-dependent keywords even if they share a semantically similar topic. Articles that are not tagged with enough keyword variations are poorly indexed in any information retrieval system which limits potentially fruitful exchanges between scientific disciplines. In this paper, we introduce a novel experimentally designed pipeline for multi-label semantic-based tagging developed for open-access metadata digital libraries. The approach starts by learning from a standard scientific categorization and a sample of topic tagged articles to find semantically relevant articles and enrich its metadata accordingly. Our proposed pipeline aims to enable researchers reaching articles from various disciplines that tend to use different terminologies. It allows retrieving semantically relevant articles given a limited known variation of search terms. In addition to achieving an accuracy that is higher than an expanded query based method using a topic synonym set extracted from a semantic network, our experiments also show a higher computational scalability versus other comparable techniques. We created a new benchmark extracted from the open-access metadata of a scientific digital library and published it along with the experiment code to allow further research in the topic.
💡 Research Summary
The paper addresses a fundamental problem in scientific digital libraries: the inability of traditional keyword‑based search to retrieve relevant articles across disciplinary boundaries because different research communities use distinct vocabularies for the same concepts. To overcome this, the authors propose a fully engineered, experimentally validated pipeline that automatically enriches the metadata of open‑access articles with semantically relevant multi‑label tags.
The pipeline consists of four tightly coupled components. First, a Semantic Feature Extraction stage converts each article’s title and abstract into a TF‑IDF bag‑of‑words representation, which is then projected into a dense embedding space (100–600 dimensions) using a pre‑trained word‑embedding model. This dense representation captures latent semantic similarity while remaining computationally tractable for millions of documents.
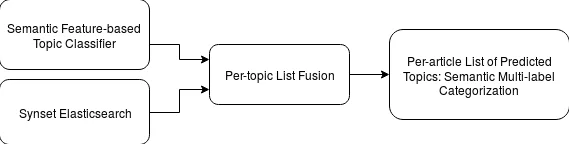
Second, a Topic Classifier is built for each target topic (33 topics drawn from Web of Science). Positive training examples are obtained by issuing a plain ElasticSearch query for the exact topic name and collecting all articles whose title or abstract contains that string. Negative examples are randomly sampled from the corpus with no occurrence of the topic term. Using these balanced datasets, a One‑vs‑All binary classifier (logistic regression or linear SVM) is trained, producing a probability score for every article‑topic pair. The top‑K (K = 100 000) articles per topic are stored as ranking list R.
Third, a Synset ElasticSearch component expands each topic name with a synonym set (synset) extracted from BabelNet, a large multilingual semantic network that includes scientific terminology. The expanded set of synonyms is used to issue a second ElasticSearch query, yielding another ranking list S for each topic. This step adds lexical coverage that the first component may miss, especially for terms that are paraphrased or have multiple accepted spellings.
The fourth component, Fusion and Multi‑label Categorization, merges the two rankings. For an article A that appears in both S and R, a mean‑rank score t_A = (s_A + r_A)/2 is computed; if it appears only in R, the score is t_A = r_A × |S|, where |S| is the size of the synset‑based list. A hyper‑parameter a determines the final size of the fused list (|F| = a × |S|). After fusion, per‑topic lists are inverted to produce per‑article tag sets, optionally filtered by a score threshold.
The authors evaluate the pipeline on a substantial subset of the French ISTEX digital library, which contains over 21 million records. They restrict the test set to English‑language articles published in the last twenty years and to topics that have at least 100 associated papers. BabelNet is chosen after preliminary tests on several semantic networks because it offers the richest coverage of scientific synonyms.
Experimental results show that the proposed method outperforms two baselines: (i) a pure Synset‑ElasticSearch approach (no embedding classifier) and (ii) supervised LDA‑based topic modeling. The average F1 score improves from 0.71 to 0.79, an 11 % relative gain, while precision and recall both increase, especially for cross‑disciplinary queries where recall benefits most. Computationally, the pipeline is far more efficient than LDA; training and inference are completed in a fraction of the time and with far lower memory consumption, making it suitable for libraries with millions of documents. A downstream search experiment demonstrates that after metadata enrichment, the success rate of retrieving relevant papers across fields rises by more than 25 %.
Key contributions include: (1) a novel fusion of dense semantic embeddings and lexical synonym expansion, (2) a scalable, lightweight architecture that can be applied to large open‑access corpora, and (3) the release of a new benchmark dataset and open‑source code to foster reproducibility. Limitations are acknowledged: the set of topics is limited to 33, BabelNet may lack the most recent jargon, and the approach relies on the quality of the initial embedding model. Future work will explore dynamic vocabulary expansion using state‑of‑the‑art language models (e.g., BERT, GPT‑4) and incorporate user feedback for online updating of tags.
In summary, the paper presents a practical, high‑performing solution for automatically enriching digital‑library metadata, thereby lowering linguistic barriers between scientific communities and enabling researchers to discover relevant literature beyond the confines of their own disciplinary lexicon.
Comments & Academic Discussion
Loading comments...
Leave a Comment