Representation Learning of Music Using Artist Labels
In music domain, feature learning has been conducted mainly in two ways: unsupervised learning based on sparse representations or supervised learning by semantic labels such as music genre. However, finding discriminative features in an unsupervised …
Authors: Jiyoung Park, Jongpil Lee, Jangyeon Park
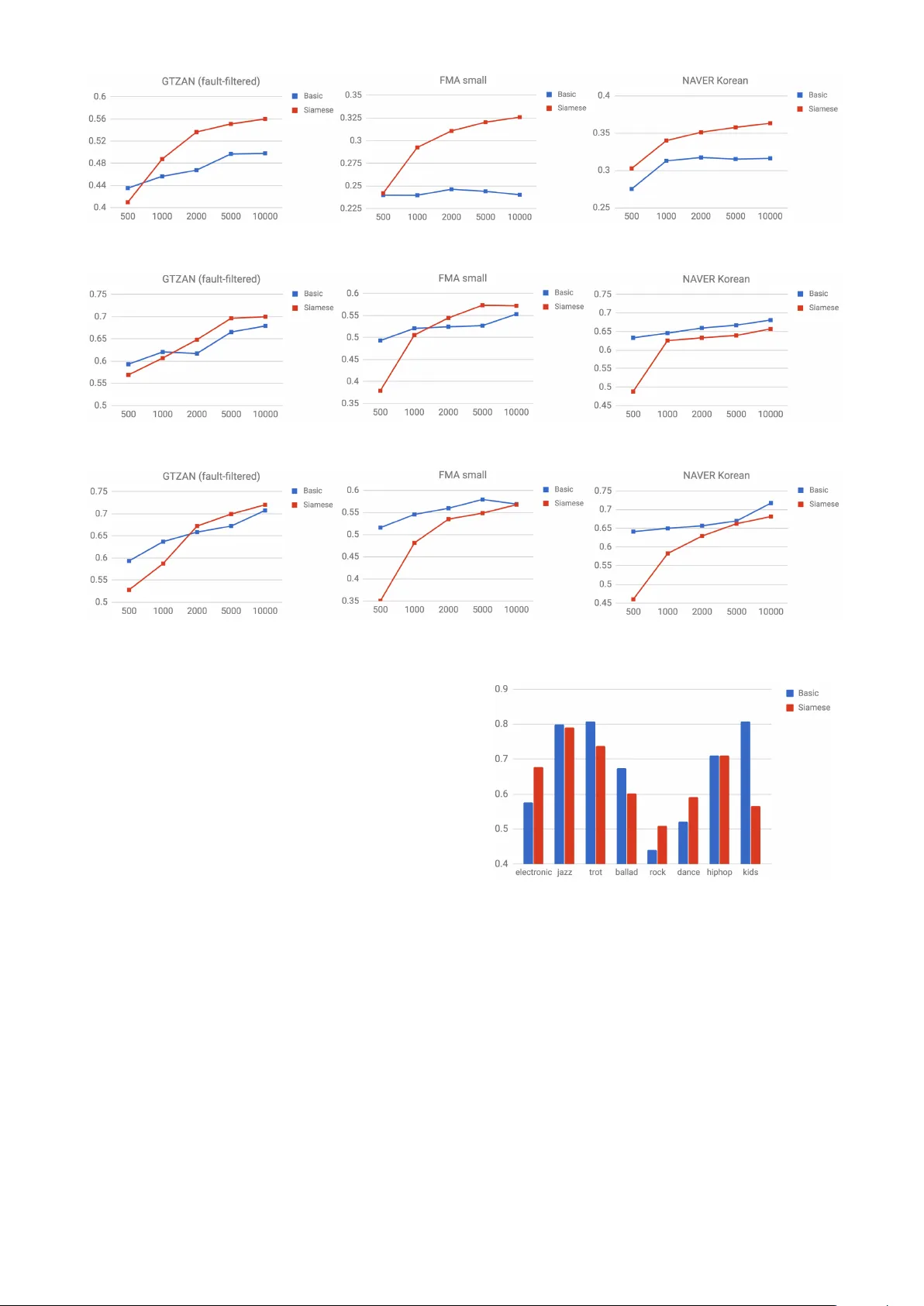
REPRESENT A TION LEARNING OF MUSIC USING AR TIST LABELS Jiy oung Park 1 ∗ Jongpil Lee 2 ∗ Jangy eon Park 1 Jung-W oo Ha 1 Juhan Nam 2 1 N A VER Corp. 2 Graduate School of Culture T echnology , KAIST { j.y.park, jangyeon.park, jungwoo.ha } @navercorp.com, { richter, juhannam } @kaist.ac.kr ABSTRA CT In music domain, feature learning has been conducted mainly in two ways: unsupervised learning based on sparse representations or supervised learning by semantic labels such as music genre. Ho wev er , finding discriminativ e fea- tures in an unsupervised way is challenging and supervised feature learning using semantic labels may inv olve noisy or expensi ve annotation. In this paper , we present a super - vised feature learning approach using artist labels anno- tated in e very single track as objectiv e meta data. W e pro- pose two deep con volutional neural networks (DCNN) to learn the deep artist features. One is a plain DCNN trained with the whole artist labels simultaneously , and the other is a Siamese DCNN trained with a subset of the artist labels based on the artist identity . W e apply the trained models to music classification and retriev al tasks in transfer learning settings. The results show that our approach is compara- ble to previous state-of-the-art methods, indicating that the proposed approach captures general music audio features as much as the models learned with semantic labels. Also, we discuss the advantages and disadvantages of the two models. 1. INTR ODUCTION Representation learning or feature learning has been ac- tiv ely explored in recent years as an alternati ve to feature engineering [1]. The data-dri ven approach, particularly us- ing deep neural networks, has been applied to the area of music information retriev al (MIR) as well [14]. In this pa- per , we propose a no vel audio feature learning method us- ing deep con volutional neural networks and artist labels. Early feature learning approaches are mainly based on unsupervised learning algorithms. Lee et al. used con volu- tional deep belief network to learn structured acoustic pat- terns from spectrogram [19]. They showed that the learned features achiev e higher performance than Mel-Frequency Cepstral Coefficients (MFCC) in genre and artist clas- sification. Since then, researchers ha ve applied v arious * Equally contributing authors. c Jiyoung Park, Jongpil Lee, Jangyeon Park, Jung-W oo Ha, Juhan Nam. Licensed under a Creativ e Commons Attribution 4.0 International License (CC BY 4.0). Attribution: Jiyoung Park, Jongpil Lee, Jangyeon Park, Jung-W oo Ha, Juhan Nam. “Representation Learn- ing of Music Using Artist Labels”, 19th International Society for Music Information Retriev al Conference, Paris, France, 2018. unsupervised learning algorithms such as sparse coding [12, 24, 29, 31], K-means [8, 24, 30] and restricted Boltz- mann machine [24, 26]. Most of them focused on learn- ing a meaningful dictionary on spectrogram by exploiting sparsity . While these unsupervised learning approaches are promising in that it can exploit abundant unlabeled audio data, most of them are limited to single or dual layers, which are not sufficient to represent complicated feature hierarchy in music. On the other hand, supervised feature learning has been progressiv ely more e xplored. An early approach was map- ping a single frame of spectrogram to genre or mood labels via pre-trained deep neural netw orks and using the hidden- unit activ ations as audio features [11, 27]. More recently , this approach was handled in the context of transfer learn- ing using deep con volutional neural networks (DCNN) [6, 20]. Lev eraging large-scaled datasets and recent ad- vances in deep learning, they sho wed that the hierarchi- cally learned features can be effecti ve for div erse music classification tasks. Ho we ver , the semantic labels that they use such as genre, mood or other timbre descriptions tend to be noisy as they are sometimes ambiguous to annotate or tagged from the crowd. Also, high-quality annotation by music experts is known to be highly time-consuming and expensi ve. Meanwhile, artist labels are the meta data annotated to songs naturally from the alb um release. The y are objectiv e information with no disagreement. Furthermore, consid- ering e very artist has his/her o wn style of music, artist la- bels may be regarded as terms that describe div erse styles of music. Thus, if we hav e a model that can discriminate different artists from music, the model can be assumed to explain v arious characteristics of the music. In this paper , we verify the hypothesis using two DCNN models that are trained to identify the artist from an audio track. One is the basic DCNN model where the softmax output units corresponds to each of artist. The other is the Siamese DCNN trained with a subset of the artist labels to mitigate the excessiv e size of the output layer in the plain DCNN when a large-scale dataset is used. After training the two models, we reg ard them as a feature extractor and apply artist features to three different genre datasets in two experiment settings. First, we directly find similar songs using the artist features and K-nearest neighbors. Second, we conduct transfer learning to further adapter the features to each of the datasets. The results show that proposed ap- proach captures useful features for unseen audio datasets (a) The Basic Model (b) The Siamese Model Figure 1 . The proposed architectures for the model using artist labels. and the propose models are comparable to those trained with semantic labels in performance. In addition, we dis- cuss the adv antages and disadvantages of the two proposed DCNN models. 2. LEARNING MODELS Figure 1 shows the two proposed DCNN models to learn audio features using artist labels. The basic model is trained as a standard classification problem. The Siamese model is trained using pair-wise similarity between an an- chor artist and other artists. In this section, we describe them in detail. 2.1 Basic Model This is a widely used 1D-CNN model for music classifica- tion [5, 9, 20, 25]. The model uses mel-spectrogram with 128 bins in the input layer . W e configured the DCNN such that one-dimensional con volution layers slide over only a single temporal dimension. The model is composed of 5 con volution and max pooling layers as illustrated in Fig- ure 1(a). Batch normalization [15] and rectified linear unit (ReLU) activ ation layer are used after ev ery con volution layer . Finally , we used cate gorical cross entropy loss in the prediction layer . W e train the model to classify artists instead of semantic labels used in many music classification tasks. For exam- ple, if the number of artists used is 1,000, this becomes a classification problem that identifies one of the 1,000 artists. After training, the extracted 256-dimensional fea- ture vector in the last hidden layer is used as the final audio feature learned using artist labels. Since this is the repre- sentation from which the identity is predicted by the lin- ear softmax classifier , we can regard it as the highest-level artist feature. 2.2 Siamese Model While the basic model is simple to train, it has two main limitations. One is that the output layer can be excessi vely large if the dataset has numerous artists. For example, if a dataset has 10,000 artists and the last hidden layer size is 100, the number of parameters to learn in the last weight matrix will reach 1M. Second, whenever new artists are added to the dataset, the model must be trained again en- tirely . W e solve the limitations using the Siamese DCNN model. A Siamese neural network consists of twin networks that share weights and configuration. It then provides unique inputs to the network and optimizes similarity scores [3, 18, 22]. This architecture can be extended to use both positi ve and negati ve examples at one optimization step. It is set up to tak e three e xamples: anchor item (query song), positiv e item (relev ant song to the query) and nega- tiv e item (different song to the query). This model is often called triplet networks and has been successfully applied to music metric learning when the relativ e similarity scores of song triplets are a v ailable [21]. This model can be further extended to use se veral negati ve samples instead of just one negati ve in the triplet network. This technique is called ne gative sampling and has been popularly used in word embedding [23] and latent semantic model [13]. By using this technique, the y could ef fectively approximate the full softmax function when the output class is extremely lar ge (i.e. 10,000 classes). W e approximate the full softmax output in the basic model with the Siamese neural networks using negati ve sampling technique. Regarding the artist labels, we set up the ne gati ve sampling by treating identical artist’ s song to the anchor song as positi ve sample and other artists’ songs as negati ve samples. This method is illustrated in Figure 1(b). Following [13], the relev ance score between the an- chor song feature and other song feature is measured as: R ( A, O ) = cos( y A , y O ) = y T A y O | y A || y O | (1) where y A and y O are the feature vectors of the anchor song and other song, respectiv ely . Meanwhile, the choice of loss function is important in this setting. W e tested two loss functions. One is the soft- max function with categorical cross-entropy loss to max- imize the positi ve relationships. The other is the max- margin hinge loss to set only margins between positive and negati ve examples [10]. In our preliminary experiments, the Siamese model with negati ve sampling was success- fully trained only with the max-margin loss function be- tween the two objecti ves, which is defined as follows: loss ( A, O ) = X O − max[0 , ∆ − R ( A, O + ) + R ( A, O − )] (2) where ∆ is the margin, O + and O − denotes positi ve ex- ample and negati ve examples, respecti vely . W e also grid- searched the number of negativ e samples and the margin, and finally set the number of negati ve samples to 4 and the margin value ∆ to 0.4. The shared audio model used in this approach is exactly the same configuration as the basic model. 2.3 Compared Model In order to verify the usefulness of the artist labels and the presented models, we constructed another model that has the same architecture as the basic model but using semantic tags. In this model, the output layer size corresponds to the number of the tag labels. Hereafter , we categorize all of them into artist-label model and tag-label model , and compare the performance. 3. EXPERIMENTS In this section, we describe source datasets to train the two artist-label models and one tag-label model. W e also in- troduce target datasets for e valuating the three models. Fi- nally , the training details are explained. 3.1 Source T asks All models are trained with the Million Song Dataset (MSD) [2] along with 30-second 7digital 1 previe w clips. Artist labels are naturally annotated onto ev ery song, thus we simply used them. For the tag label, we used the Last.fm dataset augmented on MSD. This dataset contains tag annotation that matches the ID of the MSD. 3.1.1 Artist-label Model The number of songs that belongs to each artist may be ex- tremely skewed and this can make fair comparison among the three models difficult. Thus, we selected 20 songs for each artist e venly and filtered out the artists who ha ve less than this. Also, we configured se veral sets of the artist lists to see the ef fect of the number of artists on the model per - formances (500, 1,000, 2,000, 5,000 and 10,000 artists). W e then di vided them into 15, 3 and 2 songs for training, validation and testing, respecti vely for the sets contain less than 10,000 artists. For the 10,000 artist sets, we parti- tioned them in 17, 1 and 2 songs because once the artists reach 10,000, the validation set already become 10,000 songs ev en when we only use 1 song from each artist which is already suf ficient for v alidating the model performance. 1 https://www .7digital.com/ W e also should note that the testing set is actually not used in the whole experiments in this paper because we used the source dataset only for training the models to use them as feature e xtractors. The reason we filtered and split the data in this way is for future work 2 . 3.1.2 T ag-label Model W e used 5,000 artists set as a baseline experiment setting. This contains total 90,000 songs in the training and valida- tion set with a split of 75,000 and 15,000. W e thus con- structed the same size set for tagging dataset to compare the artist-label models and the tag-label model. The tags and songs are first filtered in the same way as the previous works [4, 20]. Among the list with the filtered top 50 used tags, we randomly selected 90,000 songs and split them into the same size as the 5,000 artist set. 3.2 T arget T asks W e used 3 different datasets for genre classification. • GTZAN (fault-filtered version) [17, 28]: 930 songs, 10 genres. W e used a “fault-filtered” version of GTZAN [17] where the dataset was divided to pre- vent artist repetition in training/v alidation/test sets. • FMA small [7]: 8,000 songs, 8 balanced genres. • NA VER Music 3 dataset with only Korean artists: 8,000 songs, 8 balanced genres. W e filtered songs with only have one genre to clarify the genre char- acteristic. 3.3 T raining Details For the preprocessing, we computed the spectrogram using 1024 samples for FFT with a Hanning window , 512 sam- ples for hop size and 22050 Hz as sampling rate. W e then con verted it to mel-spectrogram with 128 bins along with a log magnitude compression. W e chose 3 seconds as a context window of the DCNN input after a set of experiments to find an optimal length that works well in music classification task. Out of the 30- second long audio, we randomly extracted the context size audio and put them into the networks as a single exam- ple. The input normalization was performed by dividing standard de viation after subtracting mean value across the training data. W e optimized the loss using stochastic gradient descent with 0.9 Nesterov momentum with 1 e − 6 learning rate de- cay . Dropout 0.5 is applied to the output of the last ac- tiv ation layer for all the models. W e reduce the learning rate when a valid loss has stopped decreasing with the ini- tial learning rate 0.015 for the basic models (both artist- label and tag-label) and 0.1 for the Siamese model. Zero- padding is applied to each con volution layer to maintain its size. 2 All the data splits of the source tasks are available at the link for re- producible research https://github.com/jiyoungpark527/ msd- artist- split . 3 http://music.nav er .com Our system was implemented in Python 2.7, Keras 2.1.1 and T ensorflow-gpu 1.4.0 for the back-end of Keras. W e used NVIDIA T esla M40 GPU machines for training our models. Code and models are av ailable at the link for re- producible research 4 . 4. FEA TURE EV ALU A TION W e apply the learned audio features to genre classifica- tion as a target task in two different approaches: feature similarity-based retrie val and transfer learning. In this sec- tion, we describe feature extraction and feature ev aluation methods. 4.1 Featur e Extraction Using the DCNN Models In this work, the models are ev aluated in three song-lev el genre classification tasks. Thus, we divided 30-second au- dio clip into 10 segments to match up with the model input size and the 256-dimension features from the last hidden layer are averaged into a single song-level feature vector and used for the following tasks. For the tasks that require song-to-song distances, cosine similarity is used to match up with the Siamese model’ s relev ance score. 4.2 Featur e Similarity-based Song Retrieval W e first ev aluated the models using mean average preci- sion (MAP) considering genre labels as rele vant items. Af- ter obtaining a ranked list for each song based on cosine similarity , we measured the MAP as following: AP = P k ∈ r el pr ecision k number of r elev ant items (3) M AP = P Q q =1 AP ( q ) Q (4) where Q is the number of queries. pr ecision k measures the fraction of correct items among first k retrieved list. The purpose of this experiment is to directly verify how similar feature vectors with the same genre are in the learned feature space. 4.3 T ransfer Learning W e classified audio examples using the k-nearest neigh- bors (k-NN) classifier and linear softmax classifier . The ev aluation metric for this experiment is classification ac- curacy . W e first classified audio examples using k-NN to classify the input audio into the largest number of genres among k nearest to features from the training set. The num- ber of k is set to 20 in this experiment. This method can be regarded as a similarity-based classification. W e also clas- sified audio using a linear softmax classifier . The purpose of this e xperiment is to verify how much the audio features of unseen datasets are linearly separable in the learned fea- ture space. 4 https://github.com/jongpillee/ ismir2018- artist . MAP Artist-label Basic Model Artist-label Siamese Model T ag-label Model GTZAN (fault-filtered) 0.4968 0.5510 0.5508 FMA small 0.2441 0.3203 0.3019 N A VER Korean 0.3152 0.3577 0.3576 T able 1 . MAP results on feature similarity-based retrie val. KNN Artist-label Basic Model Artist-label Siamese Model T ag-label Model GTZAN (fault-filtered) 0.6655 0.6966 0.6759 FMA small 0.5269 0.5732 0.5332 N A VER K orean 0.6671 0.6393 0.6898 T able 2 . KNN similarity-based classification accuracy . Linear Softmax Artist-label Basic Model Artist-label Siamese Model T ag-label Model GTZAN (fault-filtered) 0.6721 0.6993 0.7072 FMA small 0.5791 0.5483 0.5641 N A VER Korean 0.6696 0.6623 0.6755 T able 3 . Classification accuracy of a linear softmax. 5. RESUL TS AND DISCUSSION 5.1 T ag-label Model vs. Artist-label Model W e first compare the artist-label models to the tag-label model when they are trained with the same dataset size (90,000 songs). The results are shown in T able 1, 2 and 3. In feature similarity-based retrie val using MAP (T able 1), the artist-based Siamese model outperforms the rest on all tar get datasets. In the genre classification tasks (T able 2 and 3), T ag-label model works slightly better than the rest on some datasets and the trend becomes stronger in the classification using the linear softmax. Considering that the source task in the tag-based model (trained with the Last.fm tags) contains genre labels mainly , this result may attribute to the similarity of labels in both source and target tasks. Therefore, we can draw two conclusions from this experiment. First, the artist-label model is more ef fectiv e in similarity-based tasks (1 and 2) when it is trained with the proposed Siamese networks, and thus it may be more useful for music retriev al. Second, the semantic-based model is more effecti ve in genre or other semantic label tasks and thus it may be more useful for human-friendly music content organization. 5.2 Basic Model vs. Siamese Model Now we focus on the comparison of the two artist-label models. From T able 1, 2 and 3, we can see that the Siamese model generally outperforms the basic model. Howe ver , the difference become attenuated in classification tasks and the Siamese model is ev en worse on some datasets. Among them, it is notable that the Siamese model is significantly worse than the basic model on the N A VER Music dataset Figure 2 . MAP results with regard to different number of artists in the feature models. Figure 3 . Genre classification accuracy using k-NN with regard to dif ferent number of artists in the feature models. Figure 4 . Genre classification accuracy using linear softmax with regard to different number of artists in the feature models. in the genre classification using k-NN e ven though the y are based on feature similarity . W e dissected the result to see whether it is related to the cultural difference between the training data (MSD, mostly W estern) and the target data (the N A VER set, only Korean). Figure 5 shows the de- tailed classification accuracy for each genre of the NA VER dataset. In three genres, ‘Trot’,‘K-pop Ballad’ and ‘Kids’ that do not exist in the training dataset, we can see that the basic model outperforms the Siamese model whereas the results are opposite in the other genres. This indicates that the basic model is more robust to unseen genres of music. On the other hand, the Siamese model slightly ov er-fits to the training set, although it effecti vely captures the artist features. 5.3 Effect of the Number of Artists W e further analyze the artist-label models by in vestigat- ing ho w the number of artists in training the DCNN af- fects the performance. Figure 2, 3 and 4 are the results that sho w similarity-based retrie val (MAP) and genre clas- sification (accuracy) using k-NN and linear softmax, re- spectiv ely , according to the increasing number of training artists. They show that the performance is generally pro- portional to the number of artists but the trends are quite different between the two models. In the similarity-based retriev al, the MAP of the Siamese model is significantly higher than that of the basic model when the number of Figure 5 . The classification results of each genre for the N A VER dataset with only Korean music. artists is greater than 1,000. Also, as the number of artists increases, the MAP of the Siamese model consistently goes up with a slight lo wer speed whereas that of the ba- sic model saturates at 2,000 or 5,000 artists. On the other hand, the performance gap changes in the two classifica- tion tasks. On the GTZAN dataset, while the basic model is better for 500 and 1,000 artists, the Siamese model rev erses it for 2,000 and more artists. On the N A VER dataset, the basic model is consistently better . On the FMA small, the results are mixed in two classifiers. Again, the results may be explained by our interpretation of the mod- els in Section 5.2. In summary , the Siamese model seems Models GTZAN (fault-filtered) FMA small 2-D CNN [17] 0.6320 - T emporal features [16] 0.6590 - Multi-lev el Multi-scale [20] 0.7200 - SVM [7] - 0.5482 † Artist-label Basic model 0.7076 0.5687 Artist-label Siamese model 0.7203 0.5673 T able 4 . Comparison with previous state-of-the-art mod- els: classification accuracy results. Linear softmax classi- fier is used and features are extracted from the artist-label models trained with 10,000 artists. † This result was ob- tained using the provided code and dataset in [7]. to work better in similarity-based tasks and the basic model is more robust to different genres of music. In addition, the Siamese model is more capable of being trained with a large number of artists. 5.4 Comparison with State-of-the-arts The ef fectiveness of artist labels is also supported by com- parison with previous state-of-the-art models in T able 4. For this result, we report two artist-label models trained with 10,000 artists using linear softmax classifier . In this table, we can see that the proposed models are comparable to the previous state-of-the-art methods. 6. VISU ALIZA TION W e visualize the extracted feature to provide better insight on the discriminative power of learned features using artist labels. W e used the DCNN trained to classify 5,000 artists as a feature e xtractor . After collecting the feature v ec- tors, we embedded them into 2-dimensional vectors using t-distributed stochastic neighbor embedding (t-SNE). For artist visualization, we collect a subset of MSD (apart from the training data for the DCNN) from well- known artists. Figure 6 shows that artists’ songs are appro- priately distrib uted based on genre, v ocal style and gender . For example, artists with similar genre of music are closely located and female pop singers are close to each other ex- cept Maria Callas who is a classical opera singer . Interest- ingly , some songs by Michael Jackson are close to female vocals because of his distincti ve high-pitched tone. Figure 7 sho ws the visualization of features extracted from the GTZAN dataset. Even though the DCNN was trained to discriminate artist labels, they are well clustered by genre. Also, we can observe that some genres such as disco, rock and hip-hop are divided into two or more groups that might belong to different sub-genres. 7. CONCLUSION AND FUTURE WORK In this work, we presented the models to learn audio fea- ture representation using artist labels instead of semantic labels. W e compared two artist-label models and one tag- label model. The first is a basic DCNN consisting of a softmax output layer to predict which artist they belong to out of all artists used. The second is a Siamese-style ar- chitecture that maximizes the relativ e similarity score be- Figure 6 . Feature visualization by artist. T otal 22 artists are used and, among them, 15 artists are represented in color . Figure 7 . Feature visualization by genre. T otal 10 genres from the GTZAN dataset are used. tween a small subset of the artist labels based on the artist identity . The last is a model optimized using tag labels with the same architecture as the first model. After the models are trained, we used them as feature extractors and validated the models on song retriev al and genre classifi- cation tasks on three different datasets. Three interesting results were found during the experiments. First, the artist- label models, particularly the Siamese model, is compa- rable to or outperform the tag-label model. This indicates that the cost-free artist-label is as effecti ve as the e xpensiv e and possibly noisy tag-label. Second, the Siamese model showed the best performances on song retrie val task in all datasets tested. This can indicate that the pair-wise rele- vance score loss in the Siamese model helps the feature similarity-based search. Third, the use of a large number of artists increases the model performance. This result is also useful because the artists can be easily increased to a very lar ge number . As future work, we will inv estigate the artist-label Siamese model more thoroughly . First, we plan to in- vestigate advanced audio model architecture and div erse loss and pair-wise relev ance score functions. Second, the model can easily be re-trained using new added artists be- cause the model does not hav e fixed output layer . This property will be ev aluated using cross-cultural data or us- ing extremely small data (i.e. one-shot learning [18]). 8. A CKNO WLEDGEMENT This work was supported by Basic Science Research Pro- gram through the National Research Foundation of Korea funded by the Ministry of Science, ICT & Future Planning (2015R1C1A1A02036962) and by N A VER Corp. 9. REFERENCES [1] Y oshua Bengio, Aaron Courville, and Pascal V incent. Representation learning: A revie w and new perspec- tiv es. IEEE transactions on pattern analysis and ma- chine intelligence , 35(8):1798–1828, 2013. [2] Thierry Bertin-Mahieux, Daniel PW Ellis, Brian Whit- man, and Paul Lamere. The million song dataset. In Pr oc. of the International Society for Music Informa- tion Retrieval Conference (ISMIR) , volume 2, pages 591–596, 2011. [3] Jane Bromley , Isabelle Guyon, Y ann LeCun, Ed- uard S ¨ ackinger , and Roopak Shah. Signature verifica- tion using a “siamese” time delay neural network. In Advances in Neural Information Pr ocessing Systems (NIPS) , pages 737–744, 1994. [4] Keunwoo Choi, George Fazekas, and Mark Sandler . Automatic tagging using deep con volutional neural networks. In Pr oc. of the International Society for Mu- sic Information Retrieval Conference (ISMIR) , pages 805–811, 2016. [5] Keunwoo Choi, Gy ¨ orgy Fazekas, Mark Sandler , and Kyungh yun Cho. Con volutional recurrent neural net- works for music classification. In Pr oc. of the IEEE In- ternational Conference on Acoustics, Speech, and Sig- nal Pr ocessing (ICASSP) , pages 2392–2396, 2017. [6] Keunwoo Choi, Gy ¨ orgy Fazekas, Mark Sandler , and Kyungh yun Cho. Transfer learning for music classi- fication and regression tasks. In Pr oc. of the Interna- tional Conference on Music Information Retrieval (IS- MIR) , pages 141–149, 2017. [7] Micha ¨ el Def ferrard, Kirell Benzi, Pierre V an- derghe ynst, and Xavier Bresson. Fma: A dataset for music analysis. In Proc. of the International Society for Music Information Retrieval Confer ence (ISMIR) , pages 316–323, 2017. [8] Sander Dieleman and Benjamin Schrauwen. Multi- scale approaches to music audio feature learning. In International Society for Music Information Retrieval Confer ence (ISMIR) , pages 116–121, 2013. [9] Sander Dieleman and Benjamin Schrauwen. End-to- end learning for music audio. In Pr oc. of the IEEE In- ternational Conference on Acoustics, Speech and Sig- nal Pr ocessing (ICASSP) , pages 6964–6968, 2014. [10] Andrea Frome, Greg S Corrado, Jon Shlens, Samy Bengio, Jeff Dean, T omas Mikolov , et al. Devise: A deep visual-semantic embedding model. In Advances in neur al information pr ocessing systems (NIPS) , pages 2121–2129, 2013. [11] Philippe Hamel and Douglas Eck. Learning features from music audio with deep belief networks. In Pr oc. of the International Confer ence on Music Information Retrieval (ISMIR) , pages 339–344, 2010. [12] Mikael Henaf f, K evin Jarrett, K oray Ka vukcuoglu, and Y ann LeCun. Unsupervised learning of sparse features for scalable audio classification. In Proc. of the Inter- national Confer ence on Music Information Retrieval (ISMIR) , pages 681–686, 2011. [13] Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. Learning deep structured semantic models for web search using clickthrough data. In Proc. of the 22nd ACM international confer- ence on Conference on information & knowledge man- agement , pages 2333–2338. A CM, 2013. [14] Eric Humphrey , Juan Bello, and Y ann LeCun. Feature learning and deep architectures: new directions for mu- sic informatics. Journal of Intelligent Information Sys- tems , 41(3):461–481, Dec 2013. [15] Sergey Ioffe and Christian Szegedy . Batch normaliza- tion: Accelerating deep network training by reducing internal co variate shift. In International Confer ence on Machine Learning (ICML) , pages 448–456, 2015. [16] Il-Y oung Jeong and Kyogu Lee. Learning temporal fea- tures using a deep neural network and its application to music genre classification. In Pr oc. of the Interna- tional Society for Music Information Retrieval Confer- ence (ISMIR) , pages 434–440, 2016. [17] Corey Kereliuk, Bob L Sturm, and Jan Larsen. Deep learning and music adversaries. IEEE T ransactions on Multimedia , 17(11):2059–2071, 2015. [18] Gregory Koch, Richard Zemel, and Ruslan Salakhut- dinov . Siamese neural networks for one-shot image recognition. In ICML Deep Learning W orkshop , vol- ume 2, 2015. [19] Honglak Lee, Peter Pham, Y an Largman, and An- drew Y Ng. Unsupervised feature learning for au- dio classification using conv olutional deep belief net- works. In Advances in neural information pr ocessing systems (NIPS) , pages 1096–1104, 2009. [20] Jongpil Lee and Juhan Nam. Multi-le vel and multi- scale feature aggregation using pretrained conv olu- tional neural networks for music auto-tagging. IEEE Signal Pr ocessing Letters , 24(8):1208–1212, 2017. [21] Rui Lu, Kailun W u, Zhiyao Duan, and Changshui Zhang. Deep ranking: T riplet matchnet for music met- ric learning. In Pr oc. of the IEEE International Con- fer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 121–125, 2017. [22] Pranay Manocha, Rohan Badlani, Anurag Kumar , Ankit Shah, Benjamin Elizalde, and Bhiksha Raj. Content-based representations of audio using siamese neural networks. In Pr oc. of the IEEE International Confer ence on Acoustics, Speech and Signal Pr ocess- ing (ICASSP) , 2018. [23] T omas Mikolov , Ilya Sutskev er, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of w ords and phrases and their compositionality . In Advances in neural information pr ocessing systems (NIPS) , pages 3111–3119, 2013. [24] Juhan Nam, Jorge Herrera, Malcolm Slaney , and Julius O. Smith. Learning sparse feature representa- tions for music annotation and retriev al. In Pr oc. of the International Conference on Music Information Re- trieval (ISMIR) , pages 565–570, 2012. [25] Jordi Pons, Thomas Lidy , and Xavier Serra. Experi- menting with musically motiv ated conv olutional neu- ral networks. In Pr oc. of the International W orkshop on Content-Based Multimedia Indexing (CBMI) , pages 1–6, 2016. [26] Jan Schl ¨ uter and Christian Osendorfer . Music Simi- larity Estimation with the Mean-Cov ariance Restricted Boltzmann Machine. In Pr oc. of the International Con- fer ence on Machine Learning and Applications , pages 118–123, 2011. [27] Erik M. Schmidt and Y oungmoo E. Kim. Learning emotion-based acoustic features with deep belief net- works. In Pr oc. of the IEEE W orkshop on Applications of Signal Pr ocessing to Audio and Acoustics (W AS- P AA) , pages 65–68, 2011. [28] George Tzanetakis and Perry Cook. Musical genre classification of audio signals. IEEE T ransactions on speech and audio processing , 10(5):293–302, 2002. [29] Y onatan V aizman, Brian McFee, and Gert Lanckriet. Codebook-based audio feature representation for mu- sic information retriev al. IEEE/A CM T ransactions on Audio, Speech and Language Pr ocessing (T ASLP) , 22(10):1483–1493, 2014. [30] Jan W ¨ ulfing and Martin Riedmiller . Unsupervised learning of local features for music classification. In Pr oc. of the International Society for Music Informa- tion Retrieval Confer ence (ISMIR) , pages 139–144, 2012. [31] Chin-Chia Y eh, Li Su, and Y i-Hsuan Y ang. Dual-layer bag-of-frames model for music genre classification. In Pr oc. of the IEEE International Conference on Acous- tics, Speech, and Signal Pr ocessing (ICASSP) , pages 246–250, 2013.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment