Environmental Sound Classification Based on Multi-temporal Resolution Convolutional Neural Network Combining with Multi-level Features
Motivated by the fact that characteristics of different sound classes are highly diverse in different temporal scales and hierarchical levels, a novel deep convolutional neural network (CNN) architecture is proposed for the environmental sound classi…
Authors: Boqing Zhu, Kele Xu, Dezhi Wang
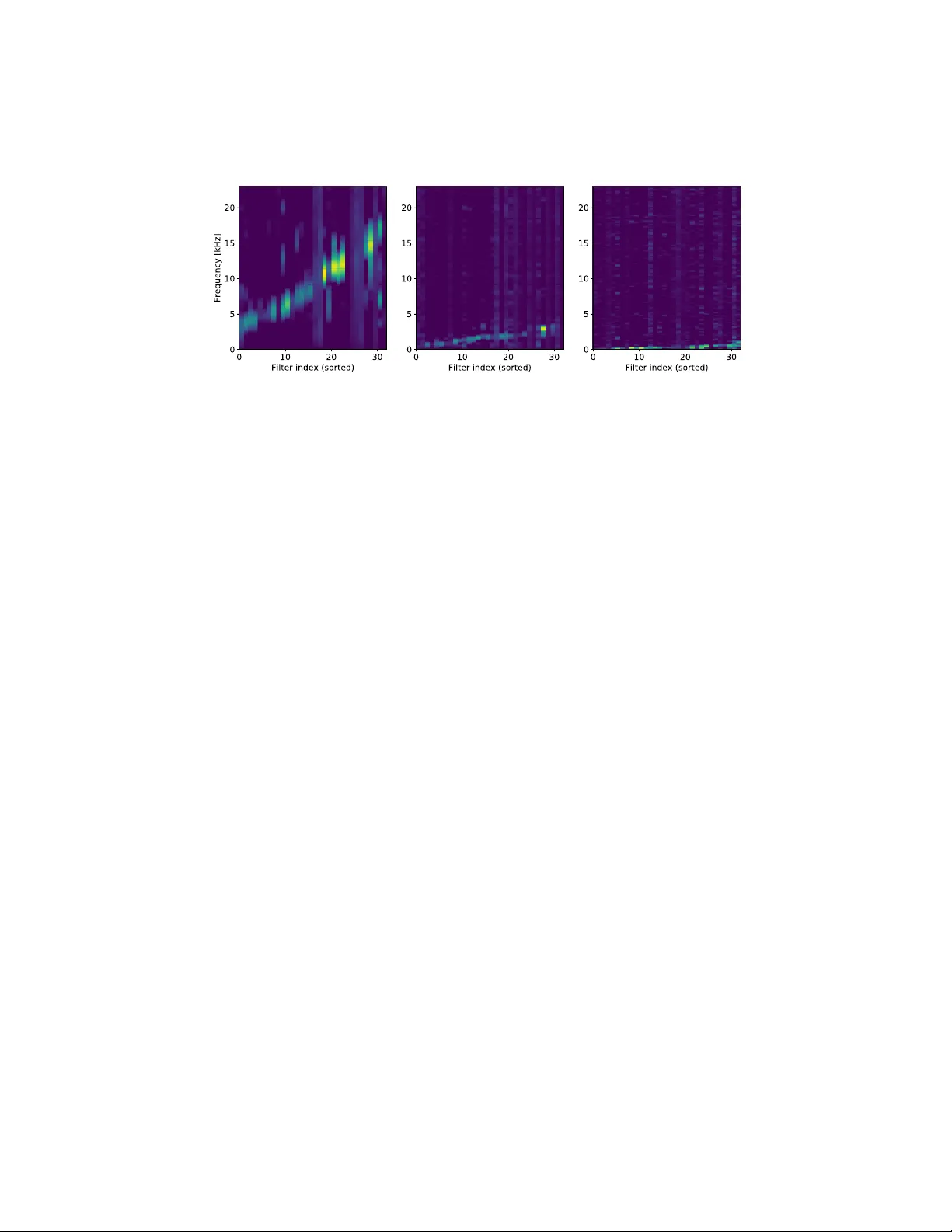
En vironmen tal Sound Classification Based on Multi-temp oral Resolution Con v olutional Neural Net w ork Com bining with Multi-lev el F eatures Bo qing Zh u 1 , Kele Xu 1 , 2 , Dezhi W ang 3 ? , Lilun Zhang 3 , Bo Li 4 , and Y uxing Peng 1 1 Science and T ec hnology on P arallel and Distributed Laboratory , National Univ ersity of Defense T echnology , Changsha, China zhuboqing09@nudt.edu.cn, pengyuxing@aliyun.com 2 Sc ho ol of Information Communication, National Univ ersity of Defense T echnology , W uhan, China kelele.xu@Gmail.com 3 College of Meteorology and Oceanograph y , National Universit y of Defense T echnology , Changsha, China wang dezhi@hotmail.com, zll0434@163.com 4 Beijing Universit y of P osts and T elecommunications, Beijing, China deepblue.lb@gmail.com Abstract. Motiv ated by the fact that characteristics of different sound classes are highly div erse in different temporal scales and hierarchical lev els, a nov el deep con volutional neural netw ork (CNN) architecture is prop osed for the environmen tal sound classification task. This net- w ork arc hitecture takes raw wa veforms as input, and a set of separated parallel CNNs are utilized with differen t con volutional filter sizes and strides, in order to learn feature represen tations with m ulti-temp oral res- olutions. On the other hand, the prop osed architecture also aggregates hierarc hical features from m ulti-level CNN la yers for classification us- ing direct connections b et ween conv olutional lay ers, whic h is b eyond the t ypical single-level CNN features employ ed by the ma jority of previous studies. This netw ork arc hitecture also improv es the flow of information and av oids v anishing gradient problem. The com bination of multi-lev el features bo osts the classification p erformance significan tly . Comparative exp erimen ts are conducted on tw o datasets: the environmen tal sound classification dataset (ESC-50), and DCASE 2017 audio scene classifica- tion dataset. Results demonstrate that the proposed metho d is highly effectiv e in the classification tasks by employing multi-temporal resolu- tion and multi-lev el features, and it outp erforms the previous metho ds whic h only account for single-level features. Keyw ords: Audio scene classification · Multi-temporal resolution · Multi- lev el · Conv olutional neural netw ork. ? Corresp onding author. 2 Bo qing, Kele, Dezhi et al. 1 In tro duction Audio classification aims to predict the most descriptive audio tags from a set of given tags determined before the analysis. Generally , it can b e divided into three main sub-domains: en vironmental sound classification, m usic classification and sp eec h classification. En vironmental sound signals are quite informative in c haracterizing environmen tal context in order to ac hieve a detailed understand- ing of the acoustic scene itself [19,20,27]. And a wide range of applications can b e found in [3,8]. Environmen tal sound classification (ESC) is also very impor- tan t for mac hines to understand the surroundings, but it is still a challenging problem, which has attracted extensiv e interest recen tly . In particular, the deep- learning based metho ds using more complex neural net w orks [11,9,1] ha ve shown great p oten tial and significant impro vemen t in this field. Due to the capabilit y of learning hierarc hical features from high-dimensional raw data, conv olutional neural netw orks (CNNs) based approaches ha ve b ecome a choice in audio clas- sification problem. Time-frequency represen tation and its v ariants, such as spectrograms, mel- frequency cepstral co efficien ts (MF CCs) [29,2], mel-filterbank features [15,5], are the most p opular input for CNN-based architectures. Ho wev er, the h yp er- parameters (suc h as hop size or window size) of short time F ourier transform (STFT) in the generation of these sp ectrogram-based representations is normally not particularly optimized for the task, while en vironmen tal sounds actually hav e differen t discriminativ e patterns in terms of time-scales and feature hierarch y [17,31,16]. T o a void exhausting parameter search, this issue may b e addressed b y applying feature extraction netw orks that directly take raw audio wa veforms as input. There are a decent num b er of CNN architectures that learns from raw w av eforms [25,4]. The ma jorit y of them emplo yed large-sized filters in the input con volutional lay ers with v arious sizes of stride to capture frequency-selective resp onses, which are carefully designed to handle their target problems. There are also a few works that used small filter and stride sizes in the input con volution la yers [28,21] inspired b y the VGG net w orks in image classification that use very small filters for conv olutional lay ers. Inspired by the fact that the different en vironmental sound tags hav e differen t p erformance sensitivity to different time-scales, a multi-scale conv olutional neu- ral netw ork named W av eMsNet [32] was prop osed to extract features b y filter banks at m ultiple scales. It uses the wa veform as input and facilitates learn- ing more precise representations on a suitable temp oral s cale to discriminate difference of en vironmental sounds. After combining the representations of the differen t temp oral resolutions, the proposed metho d claimed that sup erior p er- formance can b e ac hieved with wa v eform as input on the environmen tal sound classification datasets ESC-10 and ESC-50 [23]. Unlike previous attempts fo cus- ing on the adjustment the CNN architectures to enable the feature extraction at m ulti time-scales; in this pap er, w e explore to extend the approac h to handle the m ulti-level features from hierarchical CNN la y ers together with m ulti-scale audio features in order to even further improv e the current p erformance on the ESC problem. Similar to the netw ork setup of DenseNet [14], the concatenation of Multi-temp oral Resolution & Multi-level F eatures 3 m ulti-level features is implemented by direct connections b et ween conv olutional la yers in a feed-forward fashion, whic h accounts for more hierarchical features and also allo ws conv olutional net works to b e more efficien t to train with the help of similar mechanism of skip connections [13]. Moreov er, our metho d is also ev aluated on another b enc hmark dataset from the DCASE 2017 audio scene classification task to demonstrate the generalization capabilit y . In this study , w e ha ve follo wing contributions: 1) a nov el CNN-based architec- ture is designed that is capable of comprehensively com bining the audio features with m ulti-temp oral resolutions from ra w w av eforms and the m ulti-level features from different CNN hierarchical lay ers. 2) Comparativ ely studies are conducted to demonstrate the effect of multi time-scale and multi-lev el features on the classification p erformance of environmen tal sounds. 3) Explore to visualize the learned multi-temporal resolution and multi-lev el audio features to explain the ph ysical meaning of what the mo del has really learned. The rest of the pap er is organized as follows. Section 2 discusses related w ork. In Section 3, w e describ e our prop osed arc hitecture with implementation details. The exp erimental setup and results are given in section 4, while Section 5 concludes this pap er. 2 Related W ork Due to the rapid dev elopmen t in signal pro cessing and machine learning domains, there is an extensive surge of interest in applying deep learning approaches for the audio classification (or audio tagging) task. Most of the approaches with goo d p erformance [15,12] for the environmen tal sound classification related tasks of the DCASE 2017 c hallenge [20] utilize deep learning models suc h as CNNs, whic h ha ve already b ecome the most p opular metho d. The frequency based features are commonly used as input of CNN mo dels in the environmen tal sound clas- sification. The frequency based features are also replaced with raw audio wa ves as the input for the classifiers in some studies. This kind of end-to-end learning approac h has b een successfully used in speech recognition [25], m usic genre recog- nition [7] and so on. Recently , a ra w w av eform-based approac h so-called Sample- CNN mo del [18] shows comparable p erformance to the sp ectrogram-based CNN mo del in music tagging by using sample-level filters to learn hierarc hical audio c haracteristics. Most of the previous studies in en vironmental sound classification utilize only one level or one scale of features for the classification, which is typically adopted in image classification. How ever, this kind of method ignores that, for the audio, discriminativ e features are generally positioned in different levels or time-scales in a hierarc hy . This issue is addressed in some work b y comparing or combining m ulti-lay er or multi-scale audio features [10,6]. The combination of different res- olutions of sp ectrograms in terms of time-scale [10] is extensively studied for the prediction of audio tags. This idea is also further impro ved by using Gaussian and Laplacian pyramids [6]. Instead of concatenating the multi-scaling features only on the input lay er, attempts are also made to combine audio features from 4 Bo qing, Kele, Dezhi et al. raw w avef orm 1.5s max -pool ing max -pool ing 96 × 441 32 × 40 16 × 20 8 × 10 4 × 5 32 × 66150 32 × 13230 32 × 6615 branc h I branc h II branc h III Fig. 1. Netw ork arc hitecture for en vironmental sound classification. differen t levels [16], whic h is b elieved to provide a sup erior p erformance. T o increase temp oral resolutions of Mel-sp ectrogram segments for acoustic scene classification, an architecture [26] consisting of parallel conv olutional neural net- w orks is presented where it shows a significant improv ement compared with the b est single resolution mo del. In the pap er [30], mixup method is explored to pro vide higher prediction accuracy and robustness. 3 Prop osed Metho d In this section, we inv estigate the combination of multi-temporal resolution and m ulti-level features, for the problem of environmen tal sound classification. 3.1 Ov erview The prop osed net work arc hitecture is presented in the Fig.1. The netw ork is designed as an end-to-end system which tak es the w av e signal as input and class lab el as output. When training the netw ork, we randomly select 1.5 seconds from the original training raw w av eform data and input it into the netw ork. The selected section is different in each ep o c h, and we use the same training lab el regardless of the selected section. When testing, we classify testing data based on probability-v oting. That is, we divide the testing audio into m ultiple 1.5s sections and input each of them into the netw ork. W e take the sum of all the output probabilities after softmax and use it to classify the testing data. 3.2 Multi-temp oral Resolution CNN The arc hitecture is comp osed of a set of separated parallel 1-D time domain con volutional la yers with different filter sizes and strides, in order to learn fea- ture represen tations with multi-temporal resolutions. Sp ecifically , to learn high- frequency features, filters with a short window are applied at a small stride. Lo w-frequency features, on the con trary , employ a long window that can be ap- plied at a larger stride. Then feature maps with differen t temp oral resolution Multi-temp oral Resolution & Multi-level F eatures 5 are concatenated along frequency axis and p ooled to the same dimension on the time axis. In our exp erimen ts, we apply three branc hes of separated parallel 1-D conv o- lutional lay ers (branc h I: (size 11, stride 1), branch I I: (size 51, stride 5), branch I II: (size 101, stride 10)). Eac h branch has 32 filters. Another time-domain con- v olutional lay er is follow ed to create inv ariance to phase shifts with filter size 3 and stride 1. W e aggressively reduce the temporal resolution to 441 with a max p ooling lay er to each branch s feature map. Then we concatenate three feature map together to get the multi-temporal resolution features to represent the audios. 3.3 Multi-lev el F eature Concatenation Next, w e apply four con volutional la y ers for the m ulti-temp oral resolution feature map. The t wo dimensions of the feature map corresp ond to f r equency × time . There are 64, 128, 256, 256 filters in eac h con volutional la yer resp ectiv ely with a size of 3 × 3, and we stride the filter by 1 × 1. W e leverage non-o verlapping max p ooling to down-sample the features to the corresp onding size as sho wn in Fig.1. The outputs of the four con v olutional la yers are concatenated and then delivered to the full connection lay ers. Before the concatenation, the dimensions of the outputs are reduced to 4 × 5 by max p o oling. In the exp erimen tal section, w e in vestigate the effect of the concatenated la yers in m ulti-lev el features. The input size of full connection la yer adjusts to the dimensionalit y of the concatenated feature maps. F or instance, when we pic k features from last 3 la yers, the mo del will hav e (128 + 256 + 256) × 4 × 5 dimensional feature maps. 4 Exp erimen ts In this section, details of the DCASE 2017 ASC dataset and ESC-50 dataset used in the exp erimen t are first introduced. Then the mo del parameters and ex- p erimen tal setup are presented for the comparison of p erformance b et ween the prop osed mo del and the previous mo dels. W e p erformed 5-fold cross-v alidation fiv e times on the dataset. Finally , the conclusion is drawn based on the exp eri- men tal results. 4.1 Dataset W e use tw o datasets: 2017 DCASE challenge dataset for audio scene classifica- tion task and ESC-50 dataset to v alidate the p erformance of prop osed metho d. DCASE challenge dataset [20,27] is established to determine the con text of a giv en recording through selecting one appropriate lab el from a pre-determined set of 15 acoustic scenes suc h as cafe/restaurant, car, city cen ter and so on. Eac h scene con tains 312 recordings with a length of 10 seconds, a sampling rate of 44.1 kHz and 24-bit resolution in stereo in the dev elopment dataset. T otally there are 6 Bo qing, Kele, Dezhi et al. T able 1. Comparison of Multi-T emp oral Resolution and Single-T emp oral Resolution. T emp oral Resolution Filter Number Mean Accuracy (%) branc h I branch I I branch I II ESC-50 DCASE 2017 Lo w 96 0 0 69.1 ± 2.63 70.3 ± 3.63 Middle 0 96 0 68.2 ± 2.29 71.6 ± 3.78 High 0 0 96 68.4 ± 3.13 71.3 ± 4.02 Multi 32 32 32 71.6 ± 2.58 73.1 ± 3.34 baseline [24,20] - 64.5 61.0 4680 audio recordings in the developmen t dataset which is provided at the b e- ginning of the challenge, together with ground truth. Besides, an ev aluation dataset is also released with 1620 audio recordings in total after the c hallenge submission is closed. A four-fold cross-v alidation setup is provided so as to make results rep orted strictly comparable. The ev aluation dataset is used to ev aluate the p erformance of classification mo dels. ESC-50 [23] dataset whic h is public lab eled sets of en vironmental recordings are also used in our exp eriments. ESC-50 dataset comprises 50 equally balanced classes, each clip is ab out 5 seconds and sampled at 44.1kHz. The 50 classes can b e divided in to 5 ma jor groups: animals, natural soundscap es and water sounds, h uman non-sp eec h sound, interior/domestic sounds, and exterior/urban noises. Datasets hav e b een prearranged into 5 folds for comparable cross-v alidation and other exp erimen ts [28] used these folds. The same fold division is employ ed in our ev aluation. The metric used is classification accuracy , and the av erage accuracy across the fiv e folds is rep orted for comparison. 4.2 Exp erimen tal Details F or the net work training, cross-entrop y loss is used. T o optimize the loss, the momen tum sto c hastic gradient descent algorithm is applied with momentum 0.9. W e use Rectified Linear Units (ReLUs) to implement nonlinear activ ation functions. A batc h size of 64 is applied. All weigh t parameters are sub jected to ` 2 regularization with co efficient 5 × 10 − 4 . W e train mo dels for 160 ep ochs un til conv ergence. Learning rate is set as 10 − 2 for first 60 ep ochs, 10 − 3 for next 60 ep ochs, 10 − 4 for next 20 ep ochs and 10 − 5 for last 20 ep ochs. The w eights in the time-domain con volutional lay ers are randomly initialized. The mo dels in exp erimen t are implemen ted by PyT orch [22] and trained on GTX Titan X GPU cards. W e randomly select a 1.5 seconds w av eform as input when training the mo del. In testing phase, w e use the probabilit y-voting strategy . 4.3 Results Effect of multi-temporal resolution. W e compare the p erformances with constan t filter size at three different temporal resolutions, lo w temporal-resolution Multi-temp oral Resolution & Multi-level F eatures 7 T able 2. Performance with Multi-Level F eature. Last N lay ers feature Mean Accuracy (%) ESC-50 DCASE 2017 N = 1 71.6 ± 2.58 73.1 ± 3.34 N = 2 71.8 ± 2.79 73.2 ± 3.27 N = 3 73.0 ± 2.19 73.9 ± 2.95 N = 4 73.2 ± 2.90 74.7 ± 2.46 (Lo w), middle temp oral-resolution (Middle) and high temporal-resolution (High). These three mo dels remain only one corresp onding branc h (Low remains branch I, Middle remains branch II and High remains branc h I II). As we reduce the n um- b er of con volution filters, it ma y cause p erformance degradation. So w e use triple filters in time-domain conv olution in single temp oral resolution mo dels for fair comparison. These three v arian t models are trained separately . T able 1 demon- strates the mean accuracy and standard error using multi-temporal resolution features and single-temp oral resolution features. Both single-temporal resolution CNNs and m ulti-temp oral resolution CNN show ed b etter p erformance against the baseline. Our multi-temporal resolution mo del achiev es av erage impro ve- men t of 3.0% and 2.0% compared with the single-temp oral resolution mo dels on ESC-50 and DCASE2017 dataset resp ectiv ely . Effect of m ulti-level features. Next, we demonstrate the effectiveness of m ultiple-level features. W e down-sample and stack the feature map of the last N ( N = 1 , 2 , 3 , 4) lay ers of the netw ork. They are deliv ered to the full connection la yers. When N = 1, single-lev el features are used. As demonstrated in T able 2, the accuracies consisten tly increase on both datasets. F urther, the p erformances are alw ays b enefited from the increase of N . When N = 4, that is, concatenating features of each lay er of 2D con volution lay er, we got the b est result on ESC-50 and DCASE2017. Analysis of the results. Here, we present the analysis of the multi-temporal resolution features. The technique of visualizing the filters at differen t branc hes [18] can provide deep er understanding of what the net works hav e learned from the ra w wa v eforms. Fig.2 shows the resp onses of the m ulti-temp oral resolution fea- ture maps. Most of the filters learn to b e band-pass filters while the filters are sorted b y their central frequencies from low to high as sho wn in the figure. Branc h I has learned more dispersed bands across the frequency that can extract the features from all frequencies. But the frequency resolution is low er. On the con- trary , branch I I I has learned high-frequency resolution bands and most of them lo cate at the low-frequency area. Branch I I b eha ves b et ween branch I and I I I. This indicts that differen t branc h could learn discrepant features, and the filter 8 Bo qing, Kele, Dezhi et al. Fig. 2. F requency resp onse of the m ulti-temp oral resolution feature maps. Left shows the frequency response of feature map pro duct b y branch I. Middle corresp onds to branc h I I. Right corresp onds to branch I II. banks split resp onsibilities based on what they efficien tly can represen t. This explains wh y m ulti-temp oral resolution mo dels get a b etter performance than the single-temp oral resolution mo del sho wn in T able 1. 5 Conclusion In this article, we prop osed an effectiv e CNN architecture integrating the net- w orks for multi-temporal resolution analysis and m ulti-level feature extraction in order to ac hieve more comprehensive feature represen tations of audios and tac kle the m ulti-scale problem in the en vironmental sound classification. Through the exp erimen ts, it is shown that combining the multi-lev el and m ulti-scale features impro ves the ov erall p erformance. The raw wa veforms are directly taken as the mo del input, which enables the prop osed approac h to b e applied in an end-to- end manner. The frequency resp onse of learned filters at the mo del branches with different temp oral resolutions is visualized to b etter interpret the multi time-scale effect on filter characteristics. In future, we w ould like to ev aluate the p erformance of our metho d on a large-scale dataset of Go ogle AudioSet for the general-purp ose audio tagging task. Ac kno wledgments This study w as funded by the National Key R&D Program of China under Gran t No.2016YF C1401800, the National Natural Science F oundation of China (No.61379056, No.61702531) and the Scientific Research Pro ject of NUDT (No.ZK 17-03-31, No.ZK16-03-46). Multi-temp oral Resolution & Multi-level F eatures 9 References 1. Ab eßer, J., Mimilakis, S.I., Gr¨ afe, R., Luk ashevic h, H., F raunhofer, I.: Acoustic scene classification by combining auto enco der-based dimensionality reduction and con volutional neural netw orks (2017) 2. Bo ddapati, V., Petef, A., Rasmusson, J., Lundb erg, L.: Classifying environmen tal sounds using image recognition netw orks. Pro cedia Computer Science 112 , 2048– 2056 (2017) 3. Bugalho, M., Portelo, J., T rancoso, I., Pellegrini, T., Abad, A.: Detecting audio ev ents for semantic video searc h. In: T en th Annual Conference of the International Sp eec h Communication Asso ciation (2009) 4. Dai, W., Dai, C., Qu, S., Li, J., Das, S.: V ery deep conv olutional neural netw orks for raw w av eforms. In: Acoustics, Sp eec h and Signal Pro cessing (ICASSP), 2017 IEEE International Conference on. pp. 421–425. IEEE (2017) 5. Deng, J., Cummins, N., Han, J., Xu, X., Ren, Z., Pandit, V., Zhang, Z., Sc huller, B.: The univ ersity of passau op en emotion recognition system for the multimodal emotion challenge. In: Chinese Conference on Pattern Recognition. pp. 652–666. Springer (2016) 6. Dieleman, S., Schrau w en, B.: Multiscale approac hes to music audio feature learn- ing. In: 14th International Society for Music Information Retriev al Conference (ISMIR-2013). pp. 116–121. Pon tif ´ ıcia Universidade Cat´ olica do Paran´ a (2013) 7. Dieleman, S., Schrau wen, B.: End-to-end learning for m usic audio. In: Acoustics, Sp eec h and Signal Pro cessing (ICASSP), 2014 IEEE International Conference on. pp. 6964–6968. IEEE (2014) 8. Eyb en, F., W eninger, F., Gross, F., Sc huller, B.: Recen t dev elopmen ts in op ensmile, the m unich op en-source multimedia feature extractor. In: Pro ceedings of the 21st A CM international conference on Multimedia. pp. 835–838. A CM (2013) 9. F onseca, E., Gong, R., Bogdanov, D., Slizovsk aia, O., G´ omez Guti ´ errez, E., Serra, X.: Acoustic scene classification by ensembling gradient b oosting machine and con volutional neural net works. In: Virtanen T, Mesaros A, Heittola T, Diment A, Vincen t E, Benetos E, Martinez B, editors. Detection and Classification of Acoustic Scenes and Ev ents 2017 W orkshop (DCASE2017); 2017 No v 16; Munic h, German y . T amp ere (Finland): T ampere Universit y of T echnology; 2017. p. 37-41. T amp ere Univ ersity of T echnology (2017) 10. Hamel, P ., Bengio, Y., Eck, D.: Building musically-relev ant audio features through m ultiple timescale representations. In: ISMIR. pp. 553–558 (2012) 11. Han, Y., Lee, K.: Acoustic scene classification using con volutional neural net- w ork and m ultiple-width frequency-delta data augmentation. arXiv preprint arXiv:1607.02383 (2016) 12. Han, Y., Park, J., Lee, K.: Conv olutional neural net works with binaural represen- tations and background subtraction for acoustic scene classification (2017) 13. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Computer Vision and P attern Recognition. pp. 770–778 (2016) 14. Huang, G., Liu, Z., W einberger, K.Q., v an der Maaten, L.: Densely connected con volutional net works. In: Proceedings of the IEEE conference on computer vision and pattern recognition. vol. 1, p. 3 (2017) 15. Jung, J.W., Heo, H.S., Y ang, I.H., Y o on, S.H., Shim, H.J., Y u, H.J.: Dnn-based audio scene classification for dcase 2017: Dual input features, balancing cost, and sto c hastic data duplication. System 4 , 5 10 Bo qing, Kele, Dezhi et al. 16. Lee, J., Nam, J.: Multi-level and m ulti-scale feature aggregation using pretrained con volutional neural netw orks for music auto-tagging. IEEE signal pro cessing let- ters 24 (8), 1208–1212 (2017) 17. Lee, J., Park, J., Kim, K.L., Nam, J.: Sample-lev el deep conv olutional neu- ral net works for m usic auto-tagging using ra w wa veforms. arXiv preprint arXiv:1703.01789 (2017) 18. Lee, J., Park, J., Kim, K.L., Nam, J.: Samplecnn: End-to-end deep conv olutional neural net works using v ery small filters for music classification. Applied Sciences 8 (1), 150 (2018) 19. Marc hi, E., T onelli, D., Xu, X., Ringev al, F., Deng, J., Squartini, S., Sch uller, B.: P airwise decomp osition with deep neural netw orks and multiscale kernel subspace learning for acoustic scene classification. In: Pro ceedings of the Detection and Classification of Acoustic Scenes and Even ts 2016 W orkshop (DCASE2016). pp. 65–69 (2016) 20. Mesaros, A., Heittola, T., Diment, A., Elizalde, B., Shah, A., Vincent, E., Ra j, B., Virtanen, T.: Dcase 2017 challenge setup: T asks, datasets and baseline system. In: DCASE 2017-W orkshop on Detection and Classification of Acoustic Scenes and Ev ents (2017) 21. P alaz, D., Magimai.-Doss, M., Collob ert, R.: Analysis of cnn-based sp eec h recog- nition system using raw sp eec h as input. T ech. rep., Idiap (2015) 22. P aszke, A., Gross, S., Chintala, S., Chanan, G., Y ang, E., DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., Lerer, A.: Automatic differentiation in p ytorch (2017) 23. Piczak, K.J.: ESC: Dataset for Environmen tal Sound Classification. In: Proceed- ings of the 23rd Annual ACM Conference on Multimedia. pp. 1015–1018. ACM Press. h ttps://doi.org/10.1145/2733373.2806390, http://dl.acm.org/citation. cfm?doid=2733373.2806390 24. Piczak, K.J.: Environmen tal sound classification with conv olutional neural net- w orks. In: Machine Learning for Signal Pro cessing (MLSP), 2015 IEEE 25th In- ternational W orkshop on. pp. 1–6. IEEE (2015) 25. Sainath, T.N., W eiss, R.J., Senior, A., Wilson, K.W., Vin yals, O.: Learning the sp eec h front-end with raw wa veform cldnns. In: Sixteen th Annual Conference of the International Sp eec h Communication Asso ciation (2015) 26. Sc hindler, A., Lidy , T., Rauber, A.: Multi-temporal resolution con volutional neural net works for the dcase acoustic scene classification task 27. Sto well, D., Giannoulis, D., Benetos, E., Lagrange, M., Plumbley , M.D.: Detection and classification of acoustic scenes and even ts. IEEE T ransactions on Multimedia 17 (10), 1733–1746 (2015) 28. T okozume, Y., Harada, T.: Learning en vironmental sounds with end-to-end conv o- lutional neural netw ork. In: IEEE International Conference on Acoustics, Sp eec h and Signal Pro cessing. pp. 2721–2725 (2017) 29. V alero, X., Alias, F.: Gammatone cepstral co efficien ts: Biologically inspired fea- tures for non-sp eec h audio classification. IEEE T ransactions on Multimedia 14 (6), 1684–1689 (2012) 30. Xu, K., F eng, D., Mi, H., Zh u, B., W ang, D., Zhang, L., Cai, H., Liu, S.: Mixup- based acoustic scene classification using multi-c hannel con volutional neural net- w ork. arXiv preprint arXiv:1805.07319 (2018) 31. Xu, Y., Huang, Q., W ang, W., Plum bley , M.D.: Hierarc hical learning for dnn-based acoustic scene classification. arXiv preprin t arXiv:1607.03682 (2016) 32. Zh u, B., W ang, C., Liu, F., Lei, J., Lu, Z., P eng, Y.: Learning en vironmental sounds with multi-scale conv olutional neural net work. arXiv preprin t (2018)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment