Resource Allocation for a Wireless Coexistence Management System Based on Reinforcement Learning
In industrial environments, an increasing amount of wireless devices are used, which utilize license-free bands. As a consequence of these mutual interferences of wireless systems might decrease the state of coexistence. Therefore, a central coexistence management system is needed, which allocates conflict-free resources to wireless systems. To ensure a conflict-free resource utilization, it is useful to predict the prospective medium utilization before resources are allocated. This paper presents a self-learning concept, which is based on reinforcement learning. A simulative evaluation of reinforcement learning agents based on neural networks, called deep Q-networks and double deep Q-networks, was realized for exemplary and practically relevant coexistence scenarios. The evaluation of the double deep Q-network showed that a prediction accuracy of at least 98 % can be reached in all investigated scenarios.
💡 Research Summary
The paper addresses the growing problem of mutual interference among heterogeneous wireless devices operating in license‑free bands within industrial environments. To mitigate this, the authors propose a centrally managed coexistence system that uses reinforcement learning (RL) to predict future medium utilization and allocate conflict‑free resources accordingly. The central coordination point (CCP) acts as an RL agent, observing the radio environment through two types of measurements: (1) a fast‑Fourier‑transform (FFT) based spectral snapshot of the entire band, and (2) a wireless‑interference‑classification (WIC) output that identifies which known wireless technologies are present. In the experimental setup, the WIC component is omitted for simplicity, leaving the FFT magnitude as the sole observation.
Actions correspond to resource allocations for each wireless network (WN) under the CCP’s control. Some WNs use static channel selection (e.g., WLAN) and receive a single frequency channel, while others employ frequency‑hopping (e.g., Bluetooth) and receive a set of channels from which they can choose. After the CCP allocates resources, each WN transmits data and evaluates the quality‑of‑coexistence (QoC) metric, which aggregates transmission time, update latency, and packet‑loss ratio. The QoC values are fed back as the reward vector R for the RL agent, directly linking the success of the allocation to the learning process.
Two RL algorithms are compared: a deep Q‑network (DQN) and a double deep Q‑network (DDQN). Both use a feed‑forward neural network with four dense layers (sizes 256, 64, 32, and 4) to map observations to Q‑values for each possible action. Experience replay is employed in both cases, while the DDQN additionally uses a target network to reduce over‑estimation bias inherent in single‑network Q‑learning. Hyper‑parameters (learning rate 1e‑4, discount factor 0.96, minibatch size 32, ε‑greedy exploration decaying from 1.0 to 0.01, target‑network update every 20 episodes) are tuned for stability.
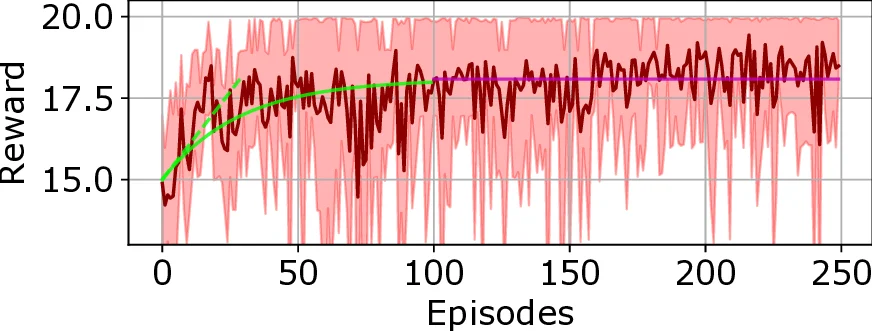
The simulation environment is built with GNU Radio for signal generation and OpenAI Gym for RL interaction. A “lean” scenario is used: a single WN consisting of two devices, four possible static channels, and PSK modulation. The reward is computed as 1 − BER for each transmission step. Two interference patterns are examined: (i) a static interferer that occupies a single channel for the whole episode (WLAN‑like), and (ii) a sequential‑hopping interferer that changes its channel after each step (WirelessHART‑like). Each episode contains 20 steps, and the experiments run for 250 episodes, repeated 15 times to obtain statistically reliable results. The first 100 episodes serve as a training phase with high exploration; the remaining 150 episodes constitute the operational phase.
Results show that the DDQN consistently achieves a mean accumulated reward of at least 19.6 out of a possible 20 across all scenarios, corresponding to a prediction accuracy of roughly 98 %. This indicates that the DDQN learns to allocate the correct channel in almost every step, even when the interferer changes its channel dynamically. The standard DQN performs slightly worse, especially in the sequential‑hopping scenario, highlighting the advantage of the double‑Q architecture in noisy, non‑stationary wireless environments.
Key contributions of the work are:
- Demonstration that a centrally‑located RL agent can successfully predict future spectrum occupancy and allocate resources in a heterogeneous, partially non‑cooperative industrial setting.
- Empirical evidence that DDQN outperforms conventional DQN in terms of prediction accuracy and robustness to interference dynamics.
- A modular observation framework that can be extended with advanced WIC classifiers (e.g., CNN, neuro‑fuzzy systems) to handle more complex multi‑technology environments.
The authors acknowledge that the current study is limited to a single WN and a simplified observation space. Future research directions include scaling the approach to multiple WNs with diverse traffic patterns, incorporating asynchronous traffic, implementing a real‑time control channel for bidirectional communication, and validating the methodology on physical testbeds. Moreover, exploring meta‑learning or transfer‑learning techniques could reduce the training time required when the industrial environment changes (e.g., new machinery or additional wireless standards). Overall, the paper provides a solid proof‑of‑concept that deep reinforcement learning, particularly DDQN, can serve as an effective engine for proactive spectrum management in modern, densely‑populated industrial wireless networks.
Comments & Academic Discussion
Loading comments...
Leave a Comment