Deconvolution-Based Global Decoding for Neural Machine Translation
A great proportion of sequence-to-sequence (Seq2Seq) models for Neural Machine Translation (NMT) adopt Recurrent Neural Network (RNN) to generate translation word by word following a sequential order. As the studies of linguistics have proved that language is not linear word sequence but sequence of complex structure, translation at each step should be conditioned on the whole target-side context. To tackle the problem, we propose a new NMT model that decodes the sequence with the guidance of its structural prediction of the context of the target sequence. Our model generates translation based on the structural prediction of the target-side context so that the translation can be freed from the bind of sequential order. Experimental results demonstrate that our model is more competitive compared with the state-of-the-art methods, and the analysis reflects that our model is also robust to translating sentences of different lengths and it also reduces repetition with the instruction from the target-side context for decoding.
💡 Research Summary
The paper addresses a fundamental limitation of most neural machine translation (NMT) systems: the decoder generates the target sentence strictly in a left‑to‑right, word‑by‑word fashion, relying only on previously generated tokens and a source‑side attention. Linguistic theory, however, suggests that translation is a globally informed process that simultaneously considers the whole target‑side structure and meaning. To bridge this gap, the authors propose a dual‑decoder architecture that augments the conventional recurrent neural network (RNN) decoder with a deconvolution‑based global decoder.
Model Overview
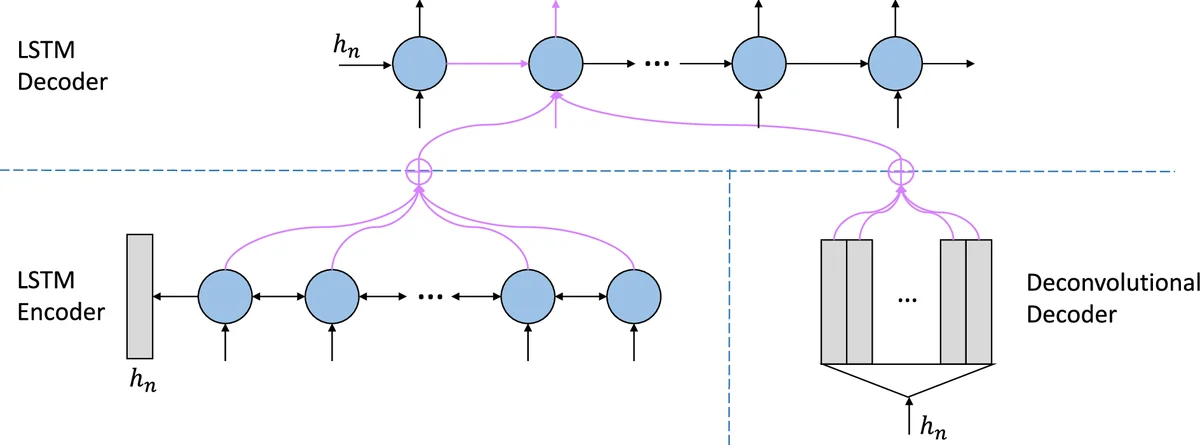
The encoder is a bidirectional LSTM that reads the source sentence and produces a sequence of hidden states h₁…hₙ. Its final hidden state hₙ serves as a compact representation of the source and is fed into two parallel decoders.
-
Deconvolution‑Based Decoder – This component is a multi‑layer transposed‑convolution (deconvolution) network. Starting from hₙ, it expands the vector into a matrix E ∈ ℝ^{T×dim}, where T is a pre‑defined target length and each column is intended to approximate the embedding of a target word. Because deconvolution does not enforce any sequential order, the matrix captures global syntactic and semantic cues of the whole sentence. The network is trained to make E close to the true embedding matrix \tilde E using a smooth L1 loss, which is robust to outliers. Additionally, a cosine‑based cross‑entropy loss is applied to the deconvolution decoder’s own token predictions, encouraging the matrix to be semantically meaningful.
-
RNN‑Based Decoder – A standard unidirectional LSTM generates the translation token by token. At each time step t, it attends to two sources of information: (a) the conventional source‑side attention over the encoder hidden states h_i, producing context c_t; and (b) a novel target‑side attention over the columns of E, producing a global context \tilde c_t. These two contexts are combined with the current hidden state to compute the output distribution via a softmax layer.
Training Objective
The overall loss is the sum of three terms: (i) the negative log‑likelihood of the reference translation given the RNN decoder’s outputs (standard NLL), (ii) the smooth L1 distance between E and \tilde E, and (iii) the cosine‑based cross‑entropy for the deconvolution decoder’s token predictions. This multi‑task formulation forces the deconvolution module to learn a high‑quality global representation while still optimizing the final translation quality.
Experiments
The authors evaluate the model on two benchmarks: (1) Chinese‑to‑English translation using the NIST dataset (≈1.25 M sentence pairs) and (2) English‑to‑Vietnamese translation using the IWSLT 2015 TED talks (≈133 K pairs). Both tasks use a 30 K (or 17.7 K/7 K) vocabulary, 512‑dimensional embeddings, and hidden layers, trained on a single NVIDIA 1080Ti GPU with Adam (lr = 0.0003).
Results show consistent BLEU improvements over a strong Seq2Seq baseline: +2.82 BLEU on the Chinese‑English test sets and +1.54 BLEU on English‑Vietnamese. Detailed analysis reveals that the proposed model reduces repetitive phrases, handles longer sentences more robustly, and better captures syntactic structures, as evidenced by attention visualizations and qualitative case studies.
Strengths and Limitations
The main strength lies in providing the decoder with an explicit, globally informed target‑side context, which mitigates the long‑range dependency problem inherent in pure RNN decoding. The deconvolution approach is computationally efficient compared to recurrent alternatives for global modeling and can be trained jointly with the standard decoder. However, the architecture introduces extra parameters and memory consumption due to the CNN decoder and dual attention mechanisms. Moreover, the target length T must be fixed in advance, requiring padding or truncation for sentences whose actual length deviates significantly.
Future Directions
Potential extensions include dynamic length prediction for the deconvolution output, lightweight transposed‑convolution designs, and applying the framework to other sequence generation tasks such as summarization or dialogue.
In summary, the paper presents a novel integration of deconvolution‑based global decoding with conventional RNN decoding, demonstrating that explicit target‑side global information can substantially improve NMT performance, especially for long and complex sentences.
Comments & Academic Discussion
Loading comments...
Leave a Comment