The NES Music Database: A multi-instrumental dataset with expressive performance attributes
Existing research on music generation focuses on composition, but often ignores the expressive performance characteristics required for plausible renditions of resultant pieces. In this paper, we introduce the Nintendo Entertainment System Music Data…
Authors: Chris Donahue, Huanru Henry Mao, Julian McAuley
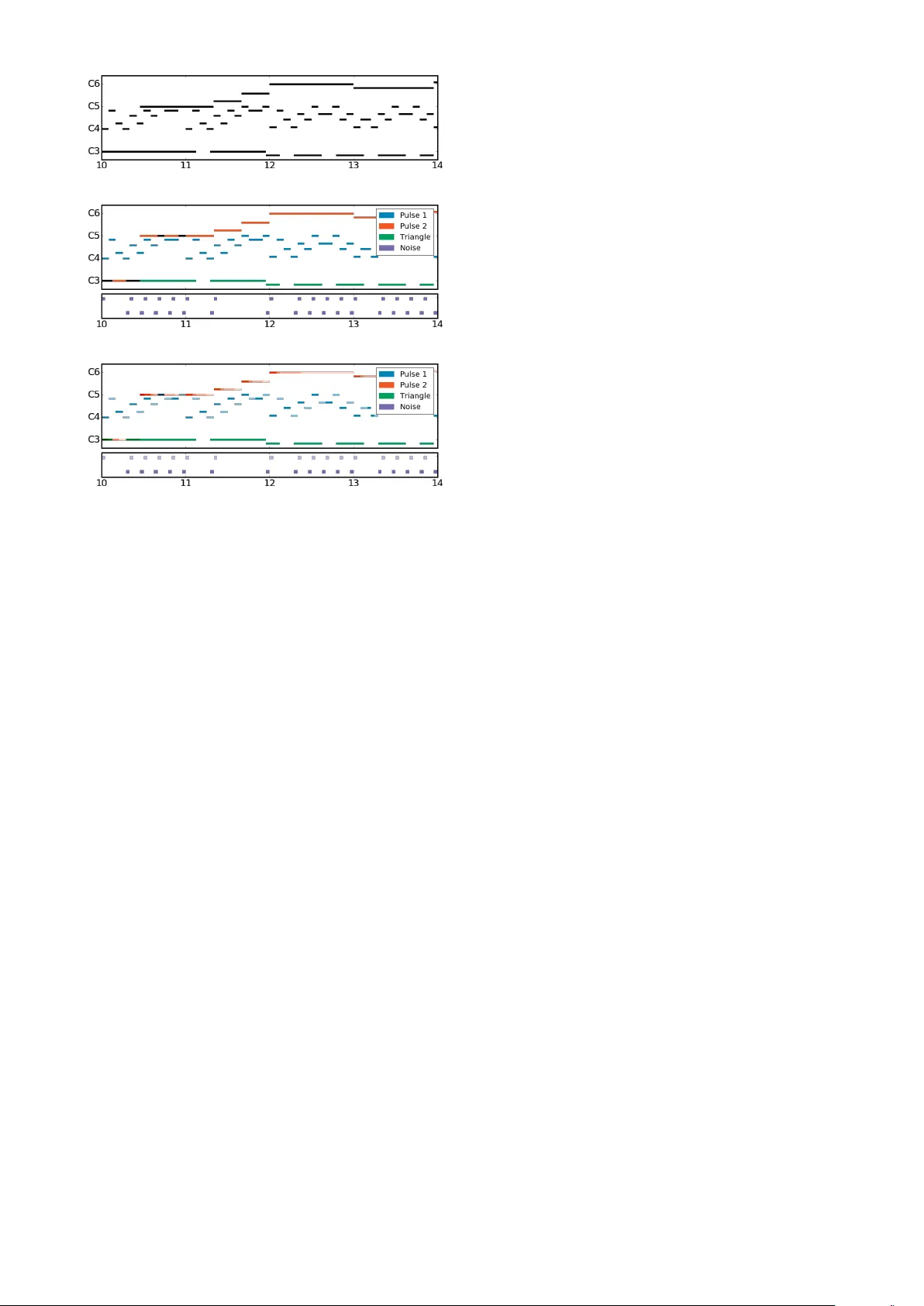
THE NES MUSIC D A T AB ASE: A MUL TI-INSTRUMENT AL D A T ASET WITH EXPRESSIVE PERFORMANCE A TTRIBUTES Chris Donahue UC San Diego cdonahue@ucsd.edu Huanru Henry Mao UC San Diego hhmao@ucsd.edu Julian McA uley UC San Diego jmcauley@ucsd.edu ABSTRA CT Existing research on music generation focuses on compo- sition, but often ignores the expressi ve performance char- acteristics required for plausible renditions of resultant pieces. In this paper , we introduce the Nintendo Entertain- ment System Music Database (NES-MDB), a large corpus allowing for separate examination of the tasks of composi- tion and performance. NES-MDB contains thousands of multi-instrumental songs composed for playback by the compositionally-constrained NES audio synthesizer . For each song, the dataset contains a musical score for four instrument voices as well as expressi ve attributes for the dynamics and timbre of each voice. Unlike datasets com- prised of General MIDI files, NES-MDB includes all of the information needed to render e xact acoustic performances of the original compositions. Alongside the dataset, we provide a tool that renders generated compositions as NES- style audio by emulating the de vice’ s audio processor . Ad- ditionally , we establish baselines for the tasks of compo- sition, which consists of learning the semantics of com- posing for the NES synthesizer , and performance, which in volves finding a mapping between a composition and re- alistic expressi ve attributes. 1. INTRODUCTION The problem of automating music composition is a chal- lenging pursuit with the potential for substantial cultural impact. While early systems were hand-crafted by musi- cians to encode musical rules and structure [25], recent at- tempts vie w composition as a statistical modeling problem using machine learning [3]. A major challenge to casting this problem in terms of modern machine learning meth- ods is building representativ e datasets for training. So f ar, most datasets only contain information necessary to model the semantics of music composition, and lack details about how to translate these pieces into nuanced performances. As a result, demonstrations of machine learning systems trained on these datasets sound rigid and deadpan. The datasets that do contain expressiv e performance character- c Chris Donahue, Huanru Henry Mao, Julian McAuley . Licensed under a Creative Commons Attribution 4.0 International Li- cense (CC BY 4.0). Attribution: Chris Donahue, Huanru Henry Mao, Julian McAuley . “The NES Music Database: A multi-instrumental dataset with expressiv e performance attributes”, 19th International Soci- ety for Music Information Retriev al Conference, Paris, France, 2018. istics predominantly focus on solo piano [10, 27, 32] rather than multi-instrumental music. A promising source of multi-instrumental music that contains both compositional and expressi ve characteris- tics is music from early videogames. There are nearly 1400 1 unique games licensed for the Nintendo Entertain- ment System (NES), all of which include a musical sound- track. The technical constraints of the system’ s audio pro- cessing unit (APU) impose a maximum of four simulta- neous monophonic instruments. The machine code for the games preserves the exact expressi ve characteristics needed to perform each piece of music as intended by the composer . All of the music was composed in a limited time period and, as a result, is more stylistically cohesive than other large datasets of multi-instrumental music. More- ov er, NES music is celebrated by enthusiasts who continue to listen to and compose music for the system [6], appreci- ating the creativity that arises from resource limitations. In this work, we introduce NES-MDB, and formalize two primary tasks for which the dataset serves as a large test bed. The first task consists of learning the semantics of composition on a separated scor e , where individual instru- ment voices are e xplicitly represented. This is in contrast to the common blended scor e approach for modeling poly- phonic music, which examines reductions of full scores. The second task consists of mapping compositions onto sets of expressi ve performance characteristics. Combining strategies for separated composition and expressi ve perfor - mance yields an effecti ve pipeline for generating NES mu- sic de novo . W e establish baseline results and reproducible ev aluation methodology for both tasks. A further contri- bution of this work is a library that con verts between NES machine code (allowing for realistic playback) and repre- sentations suitable for machine learning. 2 2. BA CKGR OUND AND T ASK DESCRIPTIONS Statistical modeling of music seeks to learn the distribution P ( music ) from human compositions c ∼ P ( music ) in a dataset M . If this distrib ution could be estimated accu- rately , a new piece could be composed simply by sampling. Since the space of potential compositions is exponentially large, to make sampling tractable, one usually assumes a factorized distribution. For monophonic sequences, which consist of no more than one note at a time, the probability 1 Including games released only on the Japanese v ersion of the console 2 https://github.com/chrisdonahue/nesmdb (a) Blended score (degenerate) (b) Separated score (melodic voices top , percussi ve voice bottom ) (c) Expressiv e score (includes dynamics and timbral changes) Figure 1 : Three representations (rendered as piano rolls) for a segment of Ending Theme from Abadox (1989) by composer Kiyohiro Sada. The blended score (Fig. 1a), used in prior polyphonic composition research, is degen- erate when multiple voices play the same note. of a sequence c (length T ) might be factorized as P ( c ) = P ( n 1 ) · P ( n 2 | n 1 ) · . . . · P ( n T | n t 10 s 3 , 513 # Notes 2 , 325 , 636 Dataset length 46 . 1 hours P ( Pulse 1 On ) 0 . 861 P ( Pulse 2 On ) 0 . 838 P ( T riangle On ) 0 . 701 P ( Noise On ) 0 . 390 A verage polyphon y 2 . 789 T able 1 : Basic dataset information for NES-MDB. 2.4 T ask summary In summary , we propose three tasks for which NES-MDB serves as a large test bed. A pairing of two models that address the second and third tasks can be used to generate nov el NES music. 1. The blended composition task (Eq. 2) models the semantics of blended scores (Fig. 1a). This task is more useful for benchmarking new algorithms than for NES composition. 2. The separated composition task consists of model- ing the semantics of separated scores (Fig. 1b) using the factorization from Eq. 3. 3. The expr essive performance task seeks to map sep- arated scores to expressi ve characteristics needed to generate an expressi ve score (Fig. 1c). 3. D A T ASET DESCRIPTION The NES APU consists of fiv e monophonic instruments: two pulse wav e generators (P1/P2), a triangle wav e gen- erator (TR), a noise generator (NO), and a sampler which allows for playback of audio wa veforms stored in mem- ory . Because the sampler may be used to play melodic or percussiv e sounds, its usage is compositionally ambiguous and we exclude it from our dataset. In raw form, music for NES games exists as machine code living in the read-only memory of cartridges, entan- gled with the rest of the game logic. An effecti ve method for extracting a musical transcript is to emulate the game and log the timing and v alues of writes to the APU re gis- ters. The video game music (VGM) format 3 was designed for precisely this purpose, and consists of an ordered list of writes to APU registers with 44 . 1 kHz timing resolu- tion. An online repository 4 contains o ver 400 NES games logged in this format. After removing duplicates, we split these games into distinct training, validation and test sub- sets with an 8 : 1 : 1 ratio, ensuring that no composer appears in two of the subsets. Basic statistics of the dataset appear in T able 1. 3 http://vgmrips.net/wiki/VGM_Specification 4 http://vgmrips.net/packs/chip/nes- apu 3.1 Extracting expressiv e scores Giv en the VGM files, we emulate the functionality of the APU to yield an e xpressive score (Fig. 1c) at a tempo- ral discretization of 44 . 1 kHz . This rate is unnecessarily high for symbolic music, so we subsequently downsam- ple the scores. 5 Because the music has no explicit tempo markings, we accommodate a variety of implicit tempos by choosing a permissi ve do wnsampling rate of 24 Hz . By re- moving dynamics, timbre, and voicing at each timestep, we deriv e separated score (Fig. 1b) and blended score (Fig. 1a) versions of the dataset. Instrument Note V elocity Timbre Pulse 1 (P1) { 0 , 32 , . . . , 108 } [0 , 15] [0 , 3] Pulse 2 (P2) { 0 , 32 , . . . , 108 } [0 , 15] [0 , 3] T riangle (TR) { 0 , 21 , . . . , 108 } Noise (NO) { 0 , 1 , . . . , 16 } [0 , 15] [0 , 1] T able 2 : Dimensionality for each timestep of the expres- siv e score representation (Fig. 1c) in NES-MDB. In T able 2, we show the dimensionality of the instru- ment states at each timestep of an expressi ve score in NES- MDB. W e constrain the frequency ranges of the melodic voices (pulse and triangle generators) to the MIDI notes on an 88 -key piano keyboard ( 21 through 108 inclusi ve, though the pulse generators cannot produce pitches below MIDI note 32 ). The per cussive noise v oice has 16 possible “notes” (these do not correspond to MIDI note numbers) where higher values have more high-frequenc y noise. For all instruments, a note value of 0 indicates that the instru- ment is not sounding (and the corresponding velocity will be 0 ). When sounding, the pulse and noise generators have 15 non-linear velocity values, while the triangle generator has no velocity control be yond on or off. Additionally , the pulse wa ve generators have 4 possi- ble duty cycles (affecting timbre), and the noise generator has a rarely-used mode where it instead produces metallic tones. Unlike for velocity , a timbre value of 0 corresponds to an actual timbre setting and does not indicate that an in- strument is muted. In total, the pulse, triangle and noise generators hav e state spaces of sizes 4621 , 89 , and 481 respectiv ely—around 40 bits of information per timestep for the full ensemble. 4. EXPERIMENTS AND DISCUSSION Below , we describe our ev aluation criteria for experiments in separated composition and e xpressiv e performance. W e present these results only as statistical baselines for com- parison; results do not necessarily reflect a model’ s ability to generate compelling musical examples. Negative log-lik elihood and Accuracy Neg ative log- likelihood (NLL) is the (log of the) likelihood that a model assigns to unseen real data (as per Eq. 3). A lo w NLL aver - aged across unseen data may indicate that a model captures 5 W e also release NES-MDB in MIDI format with no downsampling semantics of the data distribution. Accuracy is defined as the proportion of timesteps where a model’ s prediction is equal to the actual composition. W e report both measures for each v oice, as well as aggre gations across all v oices by summing (for NLL) and av eraging (for accuracy). Points of Interest (POI). Unlike other datasets of sym- bolic music, NES-MDB is temporally-discretized at a high, fixed rate ( 24 Hz ), rather than at a variable rate de- pending on the tempo of the music. As a consequence, any given voice has around an 83% chance of playing the same note as that v oice at the pre vious timestep. Accord- ingly , our primary ev aluation criteria focuses on musically- salient points of inter est (POIs), timesteps at which a voice deviates from the pre vious timestep (the beginning or end of a note). This ev aluation criterion is mostly in v ariant to the rate of temporal discretization. 4.1 Separated composition experiments For separated composition, we ev aluate the performance of sev eral baselines and compare them to a cutting edge method. Our simplest baselines are unigram and additiv e- smoothed bigram distributions for each instrument. The predictions of such models are tri vial; the unigram model always predicts “no note” and the bigram model always predicts “last note”. The respecti ve accuracy of these mod- els, 37% and 83% , reflect the proportion of the timesteps that are silent (unigram) or identical to the last timestep (bi- gram). Howe ver , if we e valuate these models only at POIs, their performance is substantially worse ( 4% and 0% ). W e also measure performance of recurrent neural net- works (RNNs) at modeling the voices independently . W e train a separate RNN (either a basic RNN cell or an LSTM cell [15]) on each voice to form our RNN Soloists and LSTM Soloists baselines. W e compare these to LSTM Quartet, a model consisting of a single LSTM that processes all four v oices and outputs an independent soft- max ov er each note category , giving the model full con- text of the composition in progress. All RNNs hav e 2 layers and 256 units, except for soloists which have 64 units each, and we train them with 512 steps of unrolling for backpropagation through time. W e train all models to minimize NLL using the Adam optimizer [19] and employ early stopping based on the NLL of the validation set. While the DeepBach model [13] was designed for mod- eling the chorales of J.S. Bach, the four-v oice structure of those chorales is shared by NES-MDB, making the model appropriate for ev aluation in our setting. DeepBach em- beds each timestep of the four-v oice score and then pro- cesses these embeddings with a bidirectional LSTM to ag- gregate past and future musical context. For each voice, the acti vations of the bidirectional LSTM are concatenated with an embedding of all of the other voices, providing the model with a mechanism to alter its predictions for an y voice in context of the others at that timestep. Finally , these merged representations are concatenated to an independent softmax for each of the four voices. Results for DeepBach and our baselines appear in T able 3. As expected, the performance of all models at POIs is worse than the global performance. DeepBach achiev es substantially better performance at POIs than the other models, likely due to its bidirectional processing which al- lows the model to “peek” at future notes. The LSTM Quar - tet model is attractive because, unlike DeepBach, it permits efficient ancestral sampling. Ho wev er, we observ e qualita- tiv ely that samples from this model are musically unsatis- fying. While the performance of the soloists is worse than the models which e xamine all voices, the superior perfor - mance of the LSTM Soloists to the RNN Soloists suggests that LSTMs may be beneficial in this context. W e also experimented with artificially emphasizing POIs during training, howe ver we found that resultant models produced unrealistically sporadic music. Based on this observation, we recommend that researchers who study NES-MDB always train models with unbiased em- phasis, in order to ef fectiv ely capture the semantics of the particular temporal discretization. 4.2 Expressiv e performance experiments The expressi ve performance task consists of learning a mapping from a separated score to suitable expressiv e characteristics. Each timestep of a separated score in NES- MDB has note information (random variable N ) for the four instrument voices. An expressiv e score addition- ally has velocity ( V ) and timbre ( T ) information for P1, P2, and NO but not TR. W e can express the distribution of performance characteristics gi ven the composition as P ( V , T | N ) . Some of our proposed solutions factorize this further into a conditional autoregressiv e formulation Q T t =1 P ( V t , T t | N , V ˆ t
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment