Singing voice phoneme segmentation by hierarchically inferring syllable and phoneme onset positions
In this paper, we tackle the singing voice phoneme segmentation problem in the singing training scenario by using language-independent information – onset and prior coarse duration. We propose a two-step method. In the first step, we jointly calculate the syllable and phoneme onset detection functions (ODFs) using a convolutional neural network (CNN). In the second step, the syllable and phoneme boundaries and labels are inferred hierarchically by using a duration-informed hidden Markov model (HMM). To achieve the inference, we incorporate the a priori duration model as the transition probabilities and the ODFs as the emission probabilities into the HMM. The proposed method is designed in a language-independent way such that no phoneme class labels are used. For the model training and algorithm evaluation, we collect a new jingju (also known as Beijing or Peking opera) solo singing voice dataset and manually annotate the boundaries and labels at phrase, syllable and phoneme levels. The dataset is publicly available. The proposed method is compared with a baseline method based on hidden semi-Markov model (HSMM) forced alignment. The evaluation results show that the proposed method outperforms the baseline by a large margin regarding both segmentation and onset detection tasks.
💡 Research Summary
This paper addresses the problem of phoneme segmentation in singing voice, specifically within the context of jingju (Beijing opera) solo training, where precise pronunciation assessment is required. The authors propose a language‑independent two‑step framework that leverages both onset detection and coarse duration information derived from teacher demonstrations.
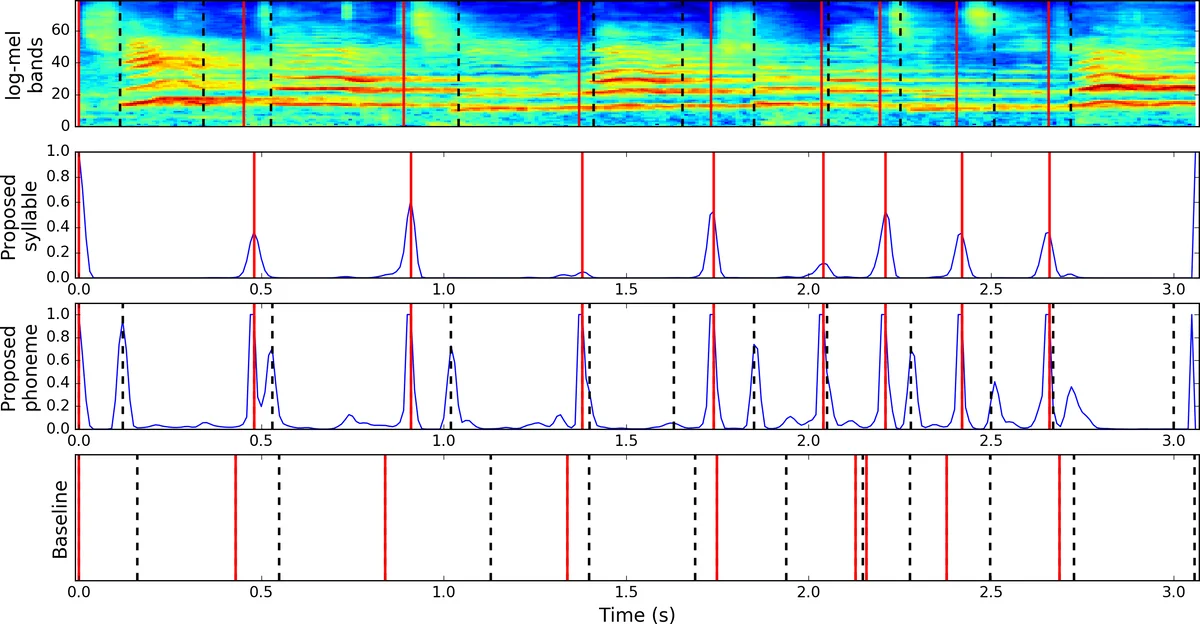
In the first step, a convolutional neural network (CNN) is trained to produce onset detection functions (ODFs) for both syllable and phoneme boundaries simultaneously. Audio is transformed into log‑mel spectrograms (27.5 Hz–16 kHz, 46.4 ms frames, 10 ms hop). Each frame is surrounded by a context window of ±70 ms (15 frames total), yielding an 80 × 15 input matrix. Ground‑truth onsets are labeled as positive, and the two neighboring frames are also marked positive with a reduced weight of 0.25 to compensate for annotation uncertainty. The network uses hard parameter sharing (a multi‑task architecture) where the convolutional backbone is common to both tasks, and two sigmoid‑activated output heads predict syllable‑ODF and phoneme‑ODF respectively. Binary cross‑entropy loss is applied to each head with equal weighting; training uses Adam optimizer, batch size 256, and early stopping after 15 epochs without validation loss improvement. The resulting ODFs provide frame‑wise probabilities of an onset occurring and serve as emission probabilities in the subsequent probabilistic model.
The second step incorporates prior coarse duration information from the teacher’s recordings. For each phrase, the teacher’s syllable durations (µₙ) and the nested phoneme durations (µₙₖ) are extracted. A Gaussian prior N(d; µₙ, σₙ²) models the likelihood of an onset after a given elapsed time, where σₙ = γ·µₙ and γ is set heuristically to 0.35. These Gaussians become the transition probabilities of a duration‑informed hidden Markov model (HMM). The hidden state space consists of all candidate onset positions discretized at the 10 ms hop resolution. Emission probabilities are the ODF values at each candidate position. The Viterbi algorithm (log‑domain) is employed to find the most probable sequence of onsets that respects both the ODF “anchors” and the duration priors. The inference proceeds hierarchically: first the syllable boundaries and labels are decoded for the whole phrase, then each syllable segment is processed independently to obtain phoneme boundaries and labels.
To evaluate the approach, the authors compiled a new jingju solo dataset containing 95 recordings (56 training, 39 test) covering two role types (dan and laosheng). Each recording is manually segmented and labeled at phrase, syllable, and phoneme levels, yielding 29 phoneme categories (including silence and non‑identifiable sounds). The dataset is publicly released via Zenodo.
A baseline system is built using a 1‑state monophone DNN/HSMM forced alignment. The same log‑mel features are fed to a shallow CNN acoustic model; the HSMM uses the same Gaussian duration priors as the proposed method but relies on a single state per phoneme and forces a left‑to‑right alignment path.
Performance is measured by (i) onset detection F1 score with a 25 ms tolerance, and (ii) segmentation accuracy defined as the proportion of total duration covered by correctly labeled segments (as used in prior lyrics‑to‑audio alignment work). Results (mean ± std over five random seeds) show that the proposed method achieves an onset F1 of 75.2 % ± 0.6, syllable segmentation accuracy of 75.8 % ± 0.4, and phoneme segmentation accuracy of 84.6 % ± 0.3. The baseline scores are substantially lower (onset F1 44.5 % ± 0.9, syllable 41.0 % ± 1.0, phoneme 65.8 % ± 0.7). Thus, the combination of multi‑task ODF learning and duration‑informed HMM inference yields a marked improvement over conventional forced alignment.
The paper’s contributions are threefold: (1) a language‑independent multi‑task CNN that jointly predicts syllable and phoneme onsets, (2) a duration‑informed HMM that integrates coarse teacher‑derived duration priors as transition probabilities, and (3) the release of a richly annotated jingju solo singing dataset. Limitations include reliance on clean vocal recordings (no accompaniment), fixed γ value for the Gaussian duration model, and potential sensitivity to large tempo variations between teacher and student. Future work may explore robust preprocessing for mixed music‑voice signals, adaptive learning of duration parameters, and fully unsupervised segmentation approaches that dispense with any phoneme‑level labeling.
Comments & Academic Discussion
Loading comments...
Leave a Comment