Consolidating the innovative concepts towards Exascale computing for Co-Design of Co-Applications ll: Co-Design Automation - Workload Characterization
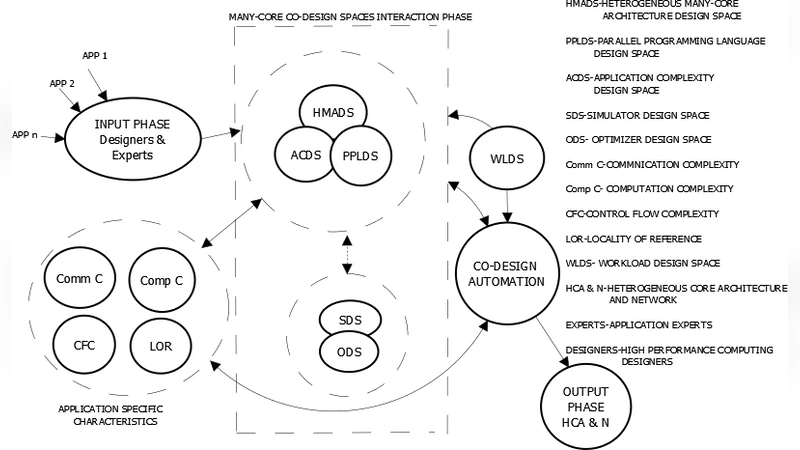
Many-core co-design is a complex task in which application complexity design space, heterogeneous many-core architecture design space, parallel programming language design space, simulator design space and optimizer design space should get integrated through a binding process and these design spaces, an ensemble of what is called many-core co-design spaces. It is indispensable to build a co-design automation process to dominate over the co-design complexity to cut down the turnaround time. The co-design automation is frame worked to comprehend the dependencies across the many-core co-design spaces and devise the logic behind these interdependencies using a set of algorithms. The software modules of these algorithms and the rest from the many-core co-design spaces interact to crop up the power-performance optimized heterogeneous many-core architecture specific for the simultaneous execution of co applications without space-time sharing. It is essential that such co-design automation has a built-in user-customizable workload generator to benchmark the emerging many-core architecture. This customizability benefits the generation of complex workloads with the desired computation complexity, communication complexity, control flow complexity, and locality of reference, specified under a distribution and established on quantitative models. In addition, the customizable workload model aids the generation of what is called computational and communication surges. None of the current day benchmark suites encompasses applications and kernels that can match the attributes of customizable workload model proposed in this paper. Aforementioned concepts are exemplified in, the case study supported by simulation results gathered from the simulator.
💡 Research Summary
The paper proposes a comprehensive co‑design automation framework aimed at the development of power‑efficient, high‑performance heterogeneous many‑core systems suitable for exascale computing. It begins by identifying five interrelated design spaces—application complexity, heterogeneous many‑core architecture, parallel programming language, simulator, and optimizer—and argues that the dependencies among these spaces must be captured through a binding process. To manage this complexity, the authors introduce a set of algorithms that model intra‑ and inter‑space interactions, enabling automatic generation of a heterogeneous core configuration that is optimized for both power and performance when executing multiple co‑applications simultaneously without space‑time sharing.
The central technical contribution is a user‑customizable workload generator. Users first employ an Application Complexity Modeling (ACM) tool to extract a computation‑communication graph from target applications, quantifying four key metrics: computational complexity (C1), communication complexity (C2), control‑flow complexity (C3), and locality of reference (C4). The generator then constructs a graph‑theoretic workload model where node weights represent numeric, semi‑numeric, non‑numeric algorithms or generic operations, and edge weights encode data volume and communication frequency. By specifying probability distributions for C1‑C4, the system can synthesize workloads with desired characteristics, including intentional “surges” in computation or communication to stress‑test specific architectural components. An algorithm repository called ALGOBANK supplies a repertoire of algorithms and operations with associated complexity measures, allowing the workload engine to produce graphs that are statistically similar to the original applications yet structurally distinct, thereby supporting both benchmarking and application cloning while preserving IP confidentiality.
The authors critique existing benchmark suites (SPEC, LINPACK, SPLASH‑2, PARSEC, Rodinia) as being static, limited in scope, and insufficient for evaluating emerging heterogeneous many‑core architectures. Their customizable model, they claim, overcomes these limitations by providing fine‑grained control over workload characteristics and enabling the generation of bespoke benchmark suites tailored to evaluate individual subsystems such as caches, memory hierarchies, network‑on‑chip (NoC), schedulers, and functional units, as well as overall system performance.
Implementation details are sketched: the workload design engine queries ALGOBANK, assembles a weighted directed graph according to the user‑specified distributions, and feeds the resulting workload into the XYZ simulator. The simulator evaluates the generated many‑core architecture, reporting metrics such as power consumption, cycles‑per‑instruction (CPI), cache hit rates, and network latency under both steady‑state and surge conditions. A case study demonstrates the end‑to‑end flow: multiple applications are co‑designed, a heterogeneous core mix is automatically derived, a customized workload is generated, and the architecture’s performance is benchmarked. Results are presented as evidence that the automated approach yields a power‑performance efficient architecture and that the workload generator can expose performance bottlenecks not visible with traditional benchmarks.
Despite its ambitious scope, the paper suffers from several shortcomings. The description of ALGOBANK and the workload generation algorithms lacks concrete pseudocode, data structures, or parameter settings, making reproducibility difficult. The XYZ simulator is not described in sufficient detail; simulation configurations (core counts, cache sizes, NoC topology, memory technology) and the exact measurement methodology are omitted, preventing independent verification of the reported gains. Moreover, quantitative validation of the synthetic workloads against real applications—e.g., similarity in instruction mix, memory access patterns, or communication traces—is absent, leaving open the question of how faithfully the generated workloads emulate real‑world behavior. The writing is also marred by numerous typographical errors, fragmented sentences, and repetitive phrasing, which hampers readability and obscures key contributions.
In summary, the paper introduces a novel vision of integrating multiple design spaces through co‑design automation and provides an innovative, graph‑based customizable workload model that promises greater flexibility than existing benchmark suites. However, the lack of detailed algorithmic exposition, insufficient experimental validation, and poor presentation quality limit the current impact of the work. Future research should focus on delivering a fully specified implementation, rigorous statistical comparison between synthetic and native workloads, and comprehensive performance evaluations across a range of heterogeneous many‑core platforms to substantiate the claimed advantages.
Comments & Academic Discussion
Loading comments...
Leave a Comment