Voice Imitating Text-to-Speech Neural Networks
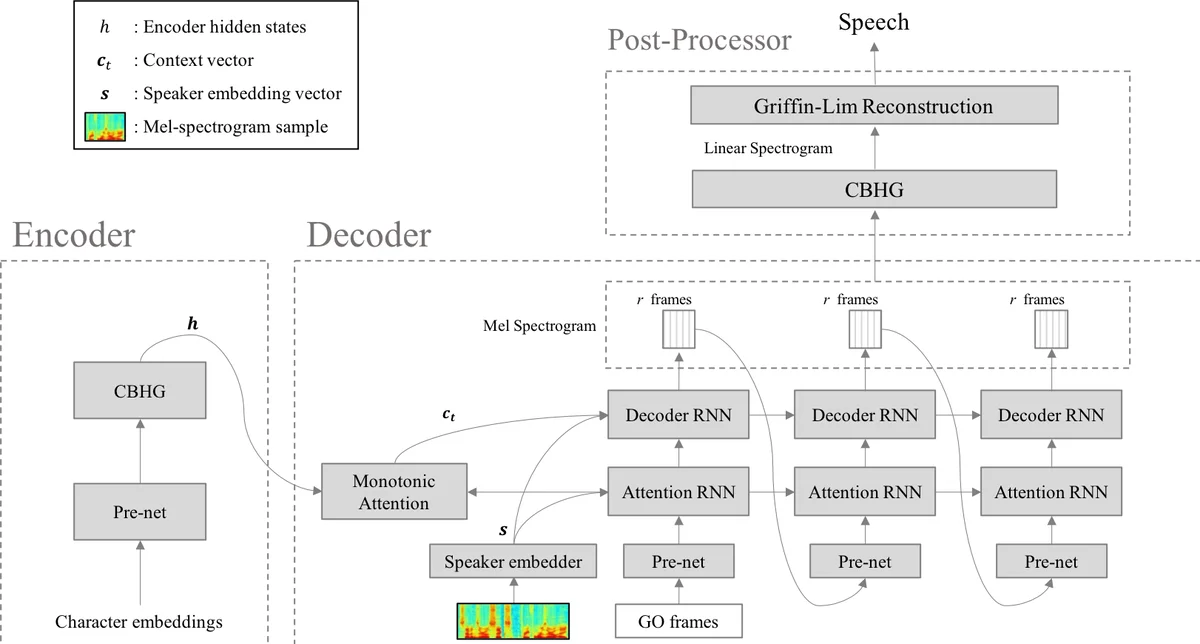
We propose a neural text-to-speech (TTS) model that can imitate a new speaker’s voice using only a small amount of speech sample. We demonstrate voice imitation using only a 6-seconds long speech sample without any other information such as transcripts. Our model also enables voice imitation instantly without additional training of the model. We implemented the voice imitating TTS model by combining a speaker embedder network with a state-of-the-art TTS model, Tacotron. The speaker embedder network takes a new speaker’s speech sample and returns a speaker embedding. The speaker embedding with a target sentence are fed to Tacotron, and speech is generated with the new speaker’s voice. We show that the speaker embeddings extracted by the speaker embedder network can represent the latent structure in different voices. The generated speech samples from our model have comparable voice quality to the ones from existing multi-speaker TTS models.
💡 Research Summary
The paper introduces a novel text‑to‑speech (TTS) system capable of instantly imitating a previously unseen speaker’s voice using only a six‑second audio snippet, without requiring any transcription or additional model training. The core architecture builds upon the well‑known Tacotron sequence‑to‑sequence model, which already supports multi‑speaker synthesis by conditioning on a speaker embedding. The authors replace the traditional one‑hot speaker ID lookup table with a “speaker embedder” network that predicts a fixed‑dimensional embedding directly from a log‑Mel spectrogram of a short speech sample.
The speaker embedder consists of five 1‑D convolutional layers (128 channels, kernel size 3) followed by two fully‑connected layers (128 units each) and a final linear projection. A max‑over‑time pooling layer after the convolutions collapses variable‑length inputs into a single time‑step vector, allowing the system to handle speech samples of arbitrary length. During training, the embedder and the Tacotron decoder are optimized jointly using the same L1 loss on both mel‑scale and linear‑scale spectrograms as in the original Tacotron; there is no explicit supervision for the embedding vectors, which are therefore learned indirectly to minimize the TTS reconstruction error.
Experiments were conducted on the VCTK corpus (109 English speakers, ~400 utterances each). After trimming silence and extracting log‑Mel and log‑linear spectrograms, the authors used 99 speakers for training and held out 10 speakers for testing, ensuring a balanced distribution of gender, age, and accent. For each training speaker, a sliding window of approximately six seconds was applied to the concatenated audio to generate many short samples; these samples were randomly paired with text inputs (not aligned) to prevent the model from simply copying the input audio.
Key findings include: (1) PCA visualisation of the learned embeddings shows clear clustering by gender and accent, indicating that the embedder captures meaningful speaker characteristics; (2) subjective listening tests comparing the proposed “voice‑imitating TTS” with a baseline multi‑speaker Tacotron reveal no statistically significant difference in mean opinion score (MOS) for overall speech quality; (3) a separate speaker‑identification test shows that listeners can correctly attribute synthesized speech to the target speaker at a rate comparable to, or slightly higher than, the baseline model. Importantly, the system can generate speech for a held‑out speaker after a single forward pass through the embedder, using only a six‑second sample, demonstrating true zero‑shot voice imitation.
The authors highlight several advantages: immediate voice cloning without any extra training, the ability to swap the embedder’s input modality (e.g., images, text) for future multimodal control, and compatibility with existing Tacotron pipelines. Limitations are acknowledged: the embedder’s performance degrades with very short samples (<2 s), robustness to noisy real‑world recordings has not been evaluated, and the approach still relies on a reasonably sized training set to learn a rich embedding space.
In conclusion, the work presents a practical and efficient method for few‑shot voice cloning, achieving comparable audio quality and speaker similarity to conventional multi‑speaker TTS while eliminating the need for transcription or model fine‑tuning. Future directions include reducing the required sample length, enhancing noise robustness, exploring multimodal embeddings, and optimizing the system for real‑time deployment.
Comments & Academic Discussion
Loading comments...
Leave a Comment