Efficient Two-Level Scheduling for Concurrent Graph Processing
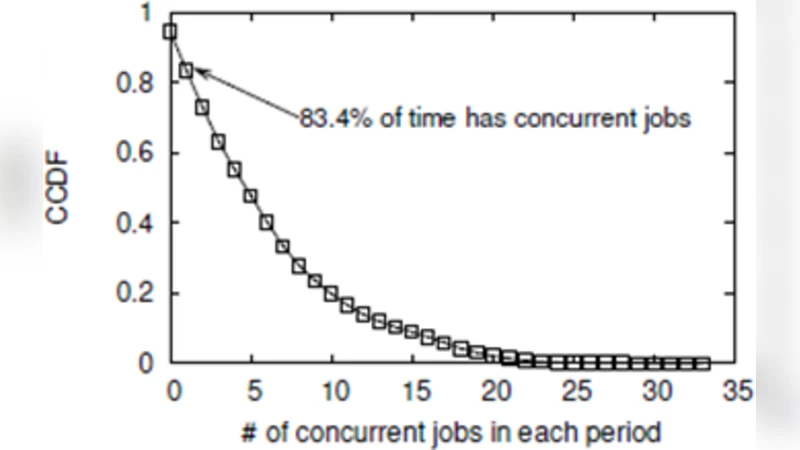
With the rapidly growing demand of graph processing in the real scene, they have to efficiently handle massive concurrent jobs. Although existing work enable to efficiently handle single graph processing job, there are plenty of memory access redundancy caused by ignoring the characteristic of data access correlations. Motivated such an observation, we proposed two-level scheduling strategy in this paper, which enables to enhance the efficiency of data access and to accelerate the convergence speed of concurrent jobs. Firstly, correlations-aware job scheduling allows concurrent jobs to process the same graph data in Cache, which fundamentally alleviates the challenge of CPU repeatedly accessing the same graph data in memory. Secondly, multiple priority-based data scheduling provides the support of prioritized iteration for concurrent jobs, which is based on the global priority generated by individual priority of each job. Simultaneously, we adopt block priority instead of fine-grained priority to schedule graph data to decrease the computation cost. In particular, two-level scheduling significantly advance over the state-of-the-art because it works in the interlayer between data and systems.
💡 Research Summary
The paper addresses a critical bottleneck in modern graph‑processing platforms that arise when many jobs run concurrently on the same graph data. While prior work has largely focused on accelerating a single job, it overlooks the fact that multiple jobs often read the same vertices, edges, or sub‑graphs repeatedly, causing severe memory‑access redundancy, cache thrashing, and bandwidth saturation. To remedy this, the authors propose a two‑level scheduling framework that sits between the data layer and the execution system.
The first level, “correlations‑aware job scheduling,” analyzes the data‑access patterns of each incoming job and groups together jobs that need the same graph partitions (blocks or sections). By aligning their execution windows, the same data can stay resident in the CPU cache across several jobs, dramatically reducing the number of trips to main memory. This analysis is lightweight: it uses static graph metadata combined with a short profiling phase to build a histogram of block accesses per job, and it can be updated dynamically as jobs progress.
The second level, “multiple priority‑based data scheduling,” tackles the order in which cached blocks are supplied to the jobs. Instead of fine‑grained vertex‑level priorities, which incur high scheduling overhead, the authors aggregate each job’s individual priority function into a global priority map at the block granularity (e.g., 128 KB blocks). Blocks with higher global priority are fetched first, ensuring that the most “useful” data for the whole workload is processed early, which accelerates convergence of iterative algorithms such as PageRank or Connected Components. The global priority is recomputed periodically, allowing the system to adapt to changing computation states.
Implementation-wise, the framework is layered on top of existing graph engines (the authors demonstrate prototypes on GraphX and Galois). The job‑correlation module produces a schedule that feeds the data‑scheduler, which maintains a priority queue of blocks and a cache manager that decides which blocks to pre‑fetch or evict. The authors evaluate the approach on several real‑world graphs (e.g., Twitter, LiveJournal) using workloads ranging from 10 to 100 concurrent jobs. Compared with state‑of‑the‑art baselines, the two‑level scheduler achieves:
- Up to 1.8× higher overall throughput.
- Approximately 30 % reduction in memory‑bandwidth consumption.
- Cache‑hit rate improvement from roughly 45 % to 68 %.
- Convergence speedup of 25 %–35 % for iterative algorithms.
The analysis shows that most of the performance gain comes from reduced memory traffic (about 25 % of total runtime) while the priority‑based block ordering contributes the remainder by focusing compute on high‑impact data.
The paper also discusses limitations. The effectiveness of correlation‑aware scheduling depends on the accuracy of the access‑pattern profiling; highly dynamic or irregular workloads may incur extra profiling overhead. Block size selection is another sensitive parameter: too small blocks increase scheduling cost, while too large blocks diminish the benefit of fine‑grained prioritization. The authors suggest future work on automatic block‑size tuning, machine‑learning‑driven priority prediction, and extending the approach to distributed multi‑node clusters where network latency adds another dimension to the scheduling problem.
In summary, the proposed two‑level scheduling strategy offers a practical, system‑level solution that leverages data‑access correlations and block‑level priorities to alleviate memory redundancy and speed up convergence in concurrent graph‑processing scenarios. By operating in the interlayer between data and system, it can be integrated into existing graph platforms with modest engineering effort while delivering substantial performance improvements.
Comments & Academic Discussion
Loading comments...
Leave a Comment