Adversarial Learning of Task-Oriented Neural Dialog Models
In this work, we propose an adversarial learning method for reward estimation in reinforcement learning (RL) based task-oriented dialog models. Most of the current RL based task-oriented dialog systems require the access to a reward signal from either user feedback or user ratings. Such user ratings, however, may not always be consistent or available in practice. Furthermore, online dialog policy learning with RL typically requires a large number of queries to users, suffering from sample efficiency problem. To address these challenges, we propose an adversarial learning method to learn dialog rewards directly from dialog samples. Such rewards are further used to optimize the dialog policy with policy gradient based RL. In the evaluation in a restaurant search domain, we show that the proposed adversarial dialog learning method achieves advanced dialog success rate comparing to strong baseline methods. We further discuss the covariate shift problem in online adversarial dialog learning and show how we can address that with partial access to user feedback.
💡 Research Summary
The paper introduces an adversarial learning framework for reward estimation in reinforcement‑learning (RL) based task‑oriented dialog systems, aiming to reduce reliance on explicit user feedback and improve sample efficiency. Two neural networks are trained jointly: a generator (dialog policy) and a discriminator (reward estimator). The generator is an LSTM‑based dialog agent that maintains a continuous dialog state, performs belief tracking over slot‑value pairs, and selects system actions using a policy network that conditions on the current state, estimated slot distributions, and a summary of external query results. The discriminator is a bidirectional LSTM that encodes the entire dialog sequence; at each turn it receives the user act, system act, and query‑result summary. Four pooling strategies (last‑state, max‑pool, average‑pool, attention‑pool) are explored to obtain a fixed‑size dialog representation, which is passed through a sigmoid layer to output the probability that the dialog is successful.
Training proceeds in several stages. First, the generator is pretrained on a human‑human dialog corpus using maximum likelihood estimation (MLE). Then a user simulator interacts with the generator to produce simulated dialogs. Successful human dialogs and simulated dialogs are used to pretrain the discriminator as a binary classifier. In the adversarial loop, the generator receives a scalar reward equal to the discriminator’s success probability at the end of each dialog. This reward is discounted and used in a REINFORCE policy‑gradient update, with a learned state‑value baseline to reduce variance. Simultaneously, the discriminator is updated to better distinguish human‑generated successful dialogs from those produced by the current generator.
A key challenge identified is covariate shift during online learning: as the generator improves, the distribution of generated dialogs diverges from the training data, potentially degrading the discriminator. The authors mitigate this by mixing a small proportion of real user feedback (partial labels) into the discriminator’s training set, which stabilizes learning without requiring extensive annotation.
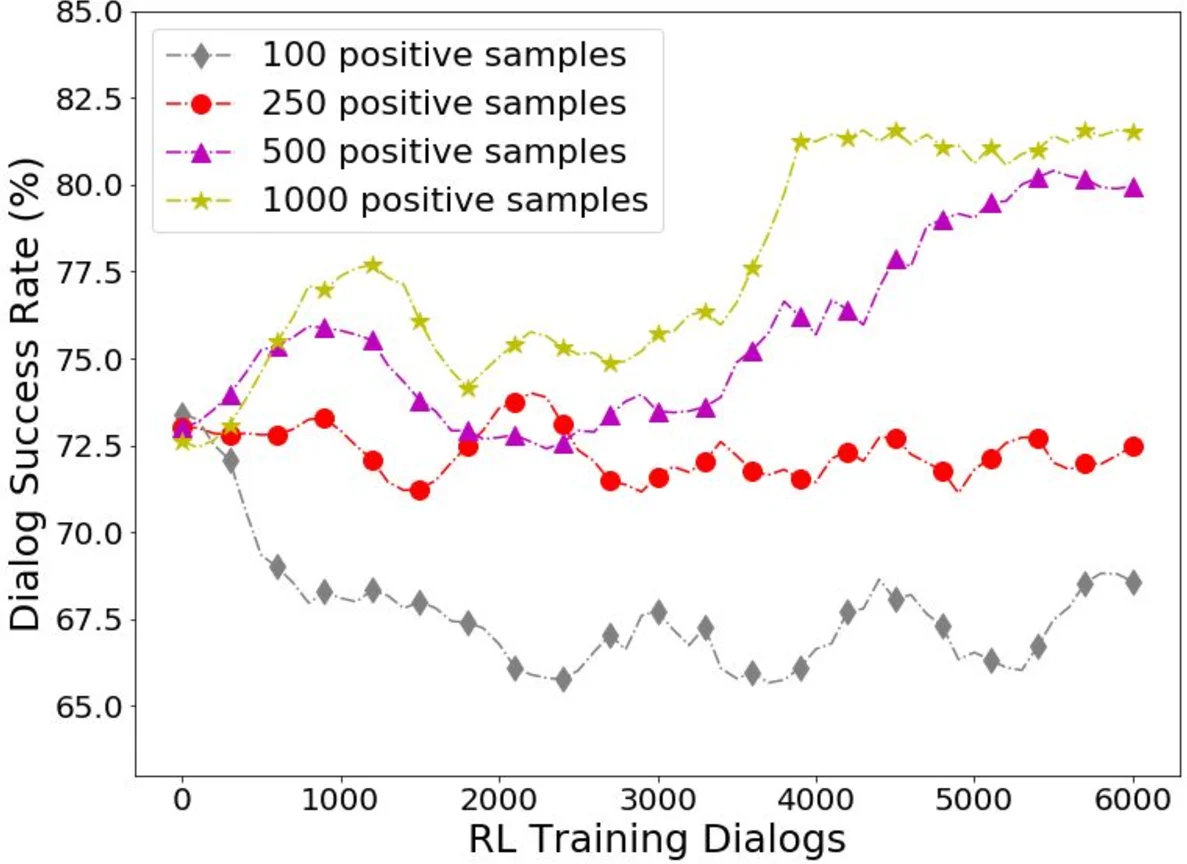
Experiments are conducted on the DSTC2 restaurant‑search dataset, augmented with entity information. The proposed adversarial method is compared against several baselines: a pure MLE end‑to‑end model, a hybrid supervised‑RL model with handcrafted reward functions, and prior GAN‑based dialog approaches. Evaluation metrics include dialog success rate, average turn count, and simulated user satisfaction. Results show that the adversarially trained agent achieves a significantly higher success rate (approximately 8–12% absolute improvement) than all baselines, even when only a small fraction of successful dialogs are labeled for discriminator pretraining. Among pooling methods, attention‑pooling yields the best discriminator accuracy, while max‑pooling also performs competitively. The partial‑feedback strategy effectively curbs performance degradation caused by covariate shift.
The analysis discusses potential mode collapse of the generator if the discriminator becomes overly dominant, suggesting techniques such as limiting discriminator update frequency or mixing a small handcrafted reward term. Limitations include evaluation confined to a single domain and dependence on the quality of the user simulator; future work should test the approach on more complex domains (e.g., travel booking, customer support) and conduct long‑term online experiments with real users.
In conclusion, the paper demonstrates that adversarially learned reward functions can replace explicit user ratings, enabling more sample‑efficient policy learning for task‑oriented dialog systems. By addressing covariate shift with limited user feedback, the method shows promise for practical deployment where consistent user ratings are unavailable.
Comments & Academic Discussion
Loading comments...
Leave a Comment