Real-valued parametric conditioning of an RNN for interactive sound synthesis
A Recurrent Neural Network (RNN) for audio synthesis is trained by augmenting the audio input with information about signal characteristics such as pitch, amplitude, and instrument. The result after training is an audio synthesizer that is played lik…
Authors: Lonce Wyse
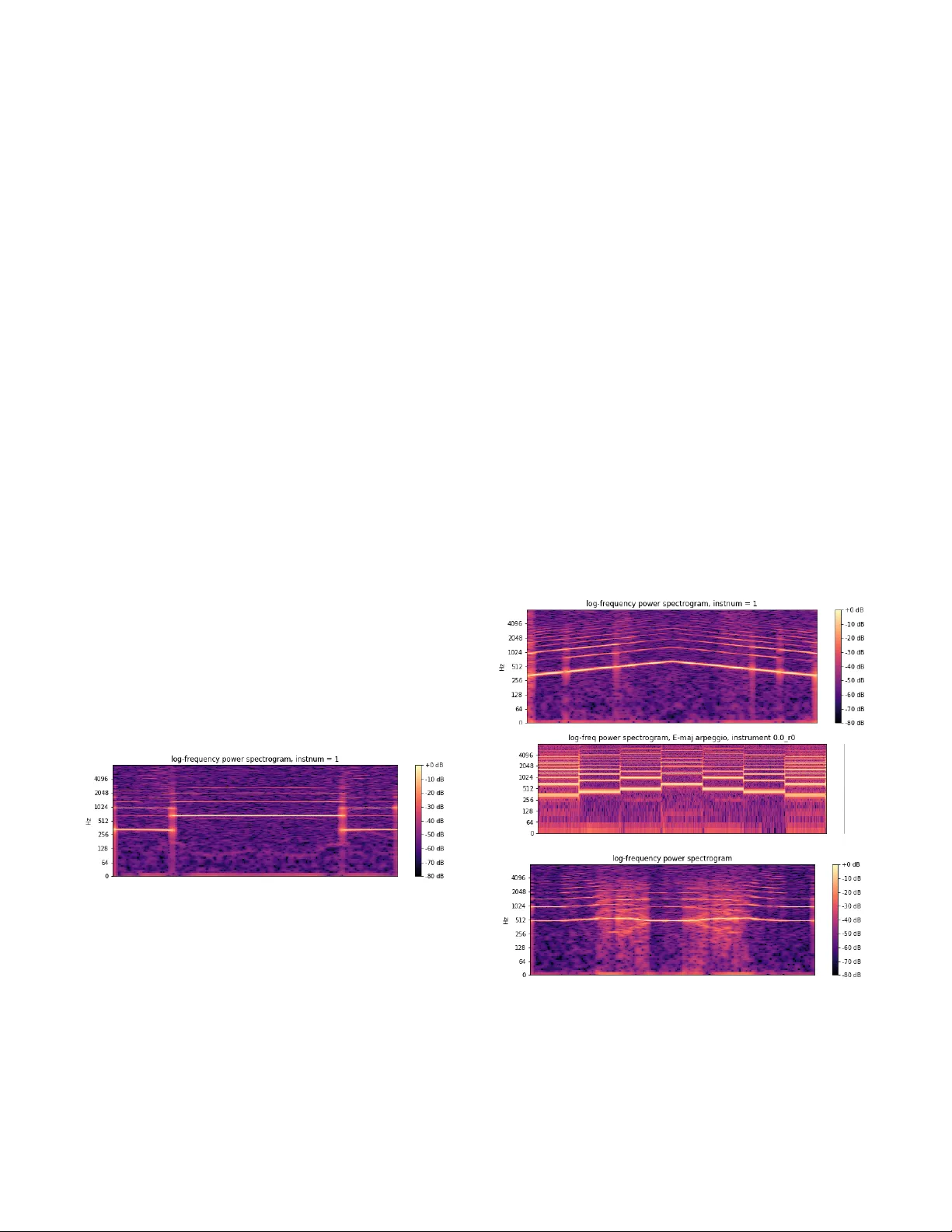
Real - valued parame tric conditioning of an RNN for intera ctive soun d synthesis Lonce Wyse Communication s and New Media Depar tment National Univer sity o f Singa pore Singapore lonce .acad @ zwhome.org Abstrac t A Recurren t Neural Ne twork (RNN) for audi o syn thesis is trained by augmenting the audio input with information about signal cha racteristics such as pitch , amplitude , and i n- strument . The result after training is an audio synthesizer that is played lik e a musical in strument with the desired m u- sical char acteristics provided as continuous parametric con- trol. The focus of this paper is on conditionin g data - driven synthesis models with real - valued parameters, and in parti c- ular, on the ability of the system a) to g eneralize and b) to be responsive to paramete r values and sequences not seen during training. Introduction Creati ng synthesi zers that model sound sources is a labor i- ous and time consuming process that involves capturing the comple xities of physica l s ounding bo dies or abstract processes in so ftwar e and/or circuits. F or ex ample, it is not enough to capture the acoustics of a single piano note to model a p iano be cause the ti mbral charac teri sti cs chan ge in nonli n ear ways with both the particular note struck and the force with w hich it is struck . Sound modeling a lso i n volves capturing or d e signing some kind of interface tha t maps input control signals such as physical gest ures to soni c qualities. For example, clarinets have keys for co ntrolling the e f fective len gth of a conically bored tube, and a singl e- reed mouth piece that is articu lated with the lip s, tongue, and breath, all of which effect the resulting sound. W riting down the equations and impl e menting models of these processes in software or har dware has been an ongoing challenge for researchers a nd comm ercial manufacturers for many de c ades. This work is licensed under the Creativ e Commons “Attribution 4.0 International” license. In recent years, deep lea rning neu ral network s have been used for data - drive n modeling across a wide variet y of domains . Th ey have pr oven adept at l earning for the m- selves w hat features of the input data are relevant for achieving their specified ta sks. “End - to - end” training re- lieves th e need to manually engineer every stage of the system and generally r e sults in improve d performance. For sound modeling, we would like the system to learn the association be t ween paramet ric control valu es provide d as input and target sound as output . The model must gene r- ate a continuous stream of audio (in the form of a sequence of sound samples), responding with minimal delay to con- tinuous parametric co ntrol. A recurre nt ne ur al network ( RNN) is developed herein since the sequence - oriented architecture is an e xcellent fit for an interactive sound sy n- thesizer . D uring train ing of the RNN , input consists of a u- dio “augmented” with p arameter values , and the system learns to p redict the n ext audio sample conditioned on the input audio and parameters . T he input parameters consist of musical pitch, vo l ume, and an instrument identifier, and the targe t output consists o f a sequence of sam ples co m- prising a musical instr ument tone character ized by the three input p a rameters. The focus of this paper is not on the details o f the archi- tecture, but o n designing and training the control interface for sound sy nthesizers . Various strate gies for co n diti oning generative RNN s using augmente d input have been deve l- oped previously under a variet y of names including “si de info r mation , ” “auxiliary feat ures,” and “context” ( Mikol ov & Zweig, 2012; Hoang, Cohn, and Haffari, 2016) . For e x- ample, phonemes and letters are frequently used for cond i- tioning the out put of sp eech systems . Ho w ever, phonemes and letters are discrete and nominal (uno r dered) while the control parameters for sy n thesizers are typically ordered and continuously valued. Some previous research has me n- tioned co nditioning with pitc h, but real - va lued conditio n- ing p a ramete rs for generative control have not received much a ttent ion in e xperi ments or documen t a tion. In this paper, the fo llo w ing qu estions w ill be add ressed: If a continuously valued parameter is chosen as an inte r- face, then how d ensely must the parameter space be sam- pled during training? How reasonable (for the sound m o d- eling task) is th e synthesis o utput during the generativ e phase using control parameter values not seen during trai n- ing? Is it adequ ate to train mo dels on unchan ging pa r ame t- ric configurations , or must training include every seque n- tial c ombinatio n o f p arameter value s th at w ill b e u sed du r- ing synthesis ? How respon sive is the system to continuou s and discrete (sudden) changes to p a rameter values during synth e sis? Previous Wo rk Mappi ng ge stu res to s ound has long bee n at the hear t of sound and musical interface design. Fels and Hinton (1993) d escribed a neural network for mapping hand ge s- tures to param eters of a speech synth esizer. Fiebrink (2011) developed the Wekinator for m apping arbitrary gestures to parameters of sound synthesis algorithms. Fried and Fiebrink (2013) use d stacked autoencoders for redu c- ing the dimensionality of physical ge stures, images, and audio clips, and then used the compressed representation s to map b etween d omains. Françoise et al . (2014) dev e l oped a “mapping - by - demonstration” approach taking ge s tures to parameters of synthesizers. Fasciani and Wyse (2012) used machin e learning to map vocal gestures to sound and sep a- rately to map from sound to synth esi zer parameters for generating sound. Gabrielli et al . ( 2017) used a con vol u- tional neural netw ork to learn upwa rds of 50 “micro - parameters ” of a physical model of a pipe organ. However, all of the techniques described above use predefined sy n- thesis sy stems for sound generation, and are thus limited by the capabilities of the available synth e sis algorithm s. They do not suppo rt the learning of ma ppings between gestures and arbitrary sound sequences that would const i- tute “end to end” learning including t he synt hesis algo- rithms the m selves. Recent advances in neural networks hold the promise of learning end - to - end model s from data. WaveNet (Van den Oord et al ., 201 6) is a co nvolutiona l network , and Sa m- pleRNN (Mehri et al . , 2016) is a rec urrent neural network that b oth learn to predict the "next" sample in a stream conditioned on what we will refer to as a “recency” wi n- dow of pr e ceding sam ples. Both can be cond i tion ed with external input supplem enting the sam ple window to infl u- ence sound generation. For example, a co ded represent a- tion of phonem es can be presen ted along with audio sa m- ples during training in order to generate desired kinds of sounds during synthesis. Eng el et al . (2017) address parametric control of a u dio generation for musical instrum ent modeling . They trained an autoe ncoder on instrument tones, and then used the a c- tivations in the low - dimensional layer connecting the en- coder to the decoder as sequential parametric “em be d ding” code s for the instrument tones. Each instrument is thus represented as tempor al sequence of low - dimensional ve c- tors. The temporal embed dings learned in the autoe n coder ne t work are then used to augment audio input for training the convolu tional WaveNet (Van den Oo rd et al ., 201 6) network to p redict au dio sequ ences. D uring s ynthesis, it is possible to interpolate between the time - varying augm en t- ed vector sequences representing different instruments in order to generate novel instrument tones under user co n- trol. The current work is als o aimed at d ata - driven learning of musica l instr ument synth e sis with interactive control over pitch and timbre. It differs from Engel et al . in th at all lear n ing and s ynthesis is done with a single network, and the n etwork is a sequential R NN, small, and oriented sp e- cif i cally to study properties of conti nuous parameter cond i- tioning relev ant for soun d sy n thesis. Architecture The synthesizer is trained as an RNN that predicts one a u- dio sample at the output for each audio sample at the input (Figure 1) . P arameter values for pitch, volum e, and instr u- ment are concatenated with the input and pr e sented to the system as a vector with four real - valued components no r- maliz ed to the ran ge [0 ,1]. Figure 1. The RNN unfolded in time. During training , a u- dio (x) is presented one sample per time step with the fo l- lowing sam ple as output. The conditioning parameters associated with the data such as pitch (p) are concatena t- ed with the audio samp le as input. D uring generation, the output at each time step (e.g. y1) becomes the input (e.g. x2) at the next time step, while the pa rameters are pr o- vided at each time step by the user. To manage the length of the sequences used for training, a sa m pling rate of 16kHz for audio is used which, with a Nyquist fre que n cy of 8kHz, is adequate to capture the pitch and ti mbral f eatures o f the i nstruments and note ranges use d for training. Audio s amples are mu - law enc oded which provid es a more effect ive resolu tion/ dynami c range trade - off than lin e ar coding. Each sample is thus coded as one of 256 different values, and then normalized to provide t he audio input component. The target values for trai ning are represented as one - hot vectors, with each node repr e- senting one of the 256 pos sible sample value s . The network consists of a linear input layer ma p ping the four - component inpu t vector (audio, pi tch, volu me, an d in strument ) to the hidden layer size of 40. T his is followed by a 4 -l ayer RNN with 40 gated recur rent unit (GRU) (Cho et al ., 2014) nodes each and fe edback from each hidden la y er to itself . A final linear layer m aps th e deepest GRU layer a ctivations to the one - hot audio output repr e sentation (see Figure 2 ). An Adam op ti mizer (Ki ngma and Ba , 2015) was use d for tra ining , with w eight changes dri v en by cross - entropy error and the standard back propagation through time algorith m (Werbos , 1995) . Un i form nois e was added at 10% of the vo lume scaling for each sequence , and no additional regularization (drop - out, normalization) tech- niques were used. During genera tion, the maximum - valued output sa m ple is chosen , mu - law e ncoded , and then fed back as in pu t for the n ext time step . Figure 2. The network consists of 4 layers of 40 GRU units each. A four - dimensional vector is passed through a linear layer as input and the output is a one - hot encoded audio sample. For training data , two synthetic and two n atu ral mu s i cal instrumen ts were used (see Table 1 ). For the synthetic i n- struments , one was comprised of a fundamental frequency at the nominal pitch value and even num bered harmo nics (multiples of the fundam e n tal), and th e other com prised of the fundam ental a nd odd ha r monics. The two natural instruments are a trumpet and a clar i net from the NSynth database (Engel et al . , 2017 ) . Thirteen si n gle recordings of notes in a one - octave note range (E4 to E5) were used for each of the instruments for trai n ing (see Fi g ure 3). “Steady state” audio segments were extracted from the NSynth files by removing the onset (0 - .5 sec ond s) and decay (3 - 4 seconds ) segments from the original recor d- ings. The sounds were then no r mali zed so that all had the same root - mean - square (rms ) v alue . Labe ls f or the pitch parameters used for inpu t were taken from the N Synth d a- tabase (one for e ach no te, desp ite any natural var iation in the r e cording), while different volum e levels for training were generate d by multipl icat ively sca ling the sounds a nd taking the sca ling values as the training parameter . S e- quences of length 256 were the n randomly drawn from these file s for tra ining. A t the 16kHz sam ple rate , 256 samples covers 5 periods of the fundamental frequency o f the lo w est pitch used . Sequen c es were trained in batche s of 256. 1. Synth even 2. Synth odd 3. Trumpet 4. Clarinet Table 1. Waveform samples for the fou r ins truments used for trainin g on the note E4 (fundamental frequency ~ 330). The first two instruments are synthetically g enera t- ed w ith even and odd harmonics respectively ; the Tru m- pet and Clarinet are recordings of physical instr um ents fr o m t h e NSyn t h d a t a b a s e . Pitch a nd the learnin g task M usical tones have a “pitch ” which is identified w ith a fundamental frequency . Howeve r , pitch is a perceptual phenomenon , and phys ical vib rations are rarely exac tly pe riodic . I nstead , p itch is perceived despite a rich var i ety of different types o f signa ls and “ noise .” Even the s e- quence of digital samples that represent the synthetic tones d o not generally have a period equal to their nominal pitch value unless the frequency components of the signal hap- pen to be exact integer submultiples o f the sa m pling rate. Figure 3. A chromatic scal e of 13 notes spanning one octave, E4 (with a fundamental frequency of ~ 333 Hz) to E5 (~660 Hz) used for t raining t he network. The goal o f trai ning is to creat e a syst em that s ynthesiz es sound with the pitch, volume, and instrum ental quality that are provided as parametric input during generation. Ho w- ever, t he system is not trained explicitly to produ ce a target pitch, but rather to produce single samples conditi oned on pitch (and other) parameter value s and a recency wi n dow of audio samples. Since the perception of pitch is esta b- lished over a large num ber o f samp les ( at least on the order of the number of samples in a pitch peri od), the network will have the task of lear ning dis tribu tions of samples at each time step , and must learn to dep end on long - term d e- p endencies to prevent pitch “er rors” from accum u lati ng. Generalization For synthesizer usability , we r equire that continuous co n- trol p arameters map to con tinuous acoustic characte r istics. This implies the need for generalization in the space of the conditioning parameters. For exam ple, the pitch p a rameter is continu ously valu ed, but if training is conducted only on a discrete set of pitch values, we desire that during gener a- tion, interpola ted p a ramete r v alues produce pitche s that are interpolated b etween the trained pitch v alues. This is simi- lar to what is expected in regression tasks (except that re- gre s sion outputs are explicit ly traine d, and sound m odel pitch is onl y implicitl y trained, a s di s cussed above). Training : Synt hetic instru ment, pi tch e ndpoints only In order to address the question o f how dense ly the real - valued musical parame ter sp aces, part icula rly pi tch, must be sampled, the network was first trained with synthetica l- ly ge n erated tones with pitches only at the tw o extreme ends of the scale for the training data and p a rameter range. After t raining only the endpoints, the generative phase is tested with param etric in put. Figure 4 sh ows a spectr o gram of the synthesizer output, as the pitch parameter is swept linearly across its range of values from its lo west to highest and back . T he pitch is smo othly interpolated across the entire range of untrained values . The outpu t is clearly not linear in the parame ter value space. Rathe r, t here is a “sticky” bias in the dire c tion of the trained pitches, an d a faster than linear transitio n in betw een the e xtreme param e- ter values. Al so vi sible is a transi tion region half way b e- tween the trained value s where the synthesi zed sound is not as clear (visibly and auditor i ly) as it is at the extrem i- ties . T his interpolation behavior is perfectly acceptable for the g oal of synthesizer d e sign. Figure 4. A network was trained only on the extreme low and high pitches a t the end points of the one - octave parameter value range. During generation, the p a rameter value was swept through untrain ed values betwe en its lowest and its h ighest and back ag ain over 3 s e conds . The result is this continuously, al though non - linea rly varying pitch. Responsiveness Another feature require d of an inte ract ive musical sound synthesizer is that it must quickly respond to control p a- rameter ch ang es so that they have immediate effect on the output produced. We would like to be free of any con- straints on param eter changes (e.g. smoothness). Thus the question arises as to whe ther the system will hav e to be trained on all possible sequential parameter value combin a- tions in order to respon d appropriate ly to such sequenc es during synthesis. It wou ld consu me fa r less time to train on individual pitches than on every sequential pitch combina- tion that might be en countered during synthesis. Howe v er, this wou ld me an that at any time step where a parameter is changed during synth e sis, the system would be confronted not only with an input configuration not seen during train- ing, but with a parameter v alue represen ting a pitch in “conflict” with the pitch of the a udio in the recency win- dow respo n sible for the current network acti vation. To explore this question of responsiveness , the mode l was trained only on individua l pitches. Then for th e gene r- a tive phase , it w as presented w ith a parameter seque nce of notes values spaced out over the parameter rang e, specifi- cally an E - major cho rd (E4, G#4, B4, E5) played fo r ward and backward as a 7 - note sequence over a total duration of 5 s e conds . As can be seen in F igure 5 , the system was ab le to r e- spond to the param eter values to make the de sired c hanges to sample seq uence s for the new pitch es . The pitches pro- duces in r e sponse to each particular p arameter value are the same as those produced during the sweep through the sam e values. Figure 5. The trained “Synth even” instrum ent co n- trolled with an arpeggio ov er the pitch ra nge illu strates the model’s ability to respon d quickly to pitch changes. This image also shows that the untrained middle pitch values are not synthesized as clearly as the trained values at the extremities . Furthermore, th e middle values contain both even and odd harmonics, thus combining timbre from each of the two trained instr uments. It can also be seen in F igure 5 that the respon se to u n- trained pitch pa rameters are les s c lear than those at th e extreme. T hey are also richer in harmonics, including some of the odd harmonics present only in the other trained in- strument ( Synth odd ). There is also a non - zero transition time between note s ind icated by the v ertical lines v isible in the spectrogra m. The y have a d uration of approximately 10ms and actually add to the realistic quality of the trans i- tion. A related issue to resp onsivenes s is drift. Previous w ork (Glover , 20 15 ) trained networks to gen erate musical pitch, but controlled the pitch production at the star t of the gen e r- ative phase by “priming” the network with trained data at the d esired pitch. Howe ver, th e sm all e rrors in eac h sa mple accumulate in this kind of autoregressive model, so that the result is a sound that drifts in pitch. W hen u sing the au g- mente d input described here which supplies continuous info r mation about the desir ed pitch to the network , there was never any evidence of drift ing pitch . For the same re a- son that new pitch parameter values “override” the audio hist o ry as the control param eter c hanges in the sweep and the arpeggio, the pitch parameter plays the role of preven t- ing drift aw ay from its spec i fied value. Physical inst rument dat a Training : Natur al in struments , pit ch endpo ints only When th e sys tem was tr aine d on re al da ta fr om th e tru m pet and clarinet recordings in the NSynth dat a base, the pitch interpolation under the 2 - pitch extreme endpoint training condition was less prono unced tha n for the s ynthetic i n- strument data . Th e smoo th but nonlinear pitch sweep was p resent for the tru mpet, bu t for the clarinet, the “stickiness” of the trained values extended almost across the entire un- trained reg ion, mak ing a fast tran sition in the m iddle b e- tween th e trained values (F igure 6) . One potentia l explan a- tion for this contrastin g behav ior is that real instrum ents exhibit quite different waveforms at different pitches, while for the synthet ic data, the wav e form w as exactly the same at all pitc hes, changing only in frequency with corre- spondingly less demanding inte rpolation r e quirements. Fig ure 6. When the network was trained on real data with only two extreme values of pitc h, pitch had a more pronounced “sti c kiness” to extreme trained pitch va lues showing a transition region without a gl ide as the pitch parameter moves smoothly from low to h igh and back. The “stickiness” bias toward trained pitches is also quite ac ceptable for synthesizers driven with sparse data in the parameter space. However, the 2- endpoint pitch training regime n wa s far more extreme than the samp ling that would be typi c al for synthesizer training. In fact, w hen the system is trained on notes in the chromatic sc ale (each no te spaced in frequency from its neighbor by approximately 6%), the interpolation of pitch is still seen for physical in- strument data (see below). Knowing the te ndency of the system to gener ate interp o- lated pitch output in response t o untrai ned conditi oning parameter values , and knowing that is not nece s sary to train on comb inatorial p arameter sequences in order to get re sponsiveness to p arameter changes during the generative phase , w e ca n now be confident about choosing a trai n ing regimen for mu sical instrument mo d els . Training : Natur al in struments , 13 pitches per octave When thi s RNN model is trained with 2 instrument s , 24 volume l evels, and a 13 - not e chromatic scale across an octave , thereby augmenting the audio sam ple stream with 3 real - valued conditioning parameters, then the behavior of the trained model is what we would expect from a musical instrumen t synthesizer . Stable and accurate pitches are pr o duced for trained parameter values, and interpolated pitc h es w ith th e proper instrum ent timbre are produced for in - between va l ues (Figure 7a). The system is immediately sensitive and r e spo nsive to parameter changes (Figure 7b), and as the instrument pa ram eter changes smoothly across the u n train ed space betw een the tw o trained end points, the timbre change s while holding pitch and volume fairly st a- ble (Fi g ure 7c). Figure 7. a. The clarinet, trained on 13 chromatic notes across an octave, generating a swe ep with the pitch p a- rameter sw ept from low to high and back. b. The tru m pet playing the arpeggio pattern. c. A continuous forth - and - back sweep across the instrument parameter trained with the natural trumpet and clarinet at its endpoint values. a. b. c. Future Wo rk Several directions are suggested for future work. Range and sound quality w ill have to be improved for the system to be a perfo rmance instrument. Extending the pitch range beyond one octave, and in particular to notes in lower reg- isters, would require m ore training and a network capable of learning longer time depende n cies, especially if a higher sampling rate were used to improv e quality. Th e archite c- ture wo uld see m to lend its elf to unpitched sound “te x- tures” that vary in p erceptual dimens ions other th an pitch, as well. However, b ased on preliminary experiments, trai n- ing will b e more difficult tha n for the semi - period ic pitched sounds explored here, and interpolation in dime n- sions su ch as “roughness” se em more challe nging than pitch. Finally, t he synthe sis phase, even w ith m odest size of the current system, is still slower than real time. How ev- er, given the one sa m ple in / one sample out architecture, and with only a few layers in be twe en, th ere a re n o i n- principle obstacl es to a low latenc y system so im portant for musica l pe rfo r manc e . Conclusions An RNN was trai ned to function as a musical sound sy n- th esizer capable of responding continuously to real - valued control va l ues for pitch, volume, and instrument type. The audio input sequence data w as augm ented with the desired parameters to be used for contr ol during synt h e sis. Key usability characteristics for generative synthesizers were shown to hold for the trained RNN mo d el: the a bility to p roduce reason able pitch output for u n trained pa rameter values, and the ability to respond quickly and appropriately to parameter cha nges. T he training data can be quite sp arse in th e sp ace defined by the conditioning pa rameters, and still generate sample se quences ap propr i ate for m usical sound synthesis . We al so showed that a classic “drifting” pitch problem is addressed with the augm ented input stra t- egy, even though pit ch is only implicitly trained in this autoregressive audio sample prediction model. This bodes will fo r the use of RNNs for deve loping general data - driv en sound synth e sis models. Supplementary Media Audio referenced in this pap er , as well as links to open - source code for reproducing this data can be found online at: http:// lonce.org/rese arch/ RNNAudioCond ition ing/ Acknowledgements This researc h was suppor ted in part by an NVidia Acade m- ic Pr o grams GPU grant. References K. Cho, B. van Merrienbo er, D. Bahdanau, and Y. Bengio. (2014). On the properties of neural machine translati on: Encoder - decoder approaches. arXiv preprint arXiv:1409.125 . Engel, J., Resnick , C., R oberts, A., D ieleman, S., Ec k, D., Sim o- nyan, K., & Norouzi, M . (2017). Neural audio synthesis of mus i- cal notes with wavenet autoencoders. arXiv preprint arXiv :1704.01279. Fasciani, S. and Wyse, L. ( 2012 ) . A voice inte rface for soun d generators: adap tive and au tomatic mapp ing of ge s ture s to sound. In Proceedings of the Conference on New Interfaces for Musical Expression . Hoang, C. D. V., Cohn, T., & Haffari, G. (2016). Inco rp o rating side information into recurrent neural network la n guage models. In P roceedings of the 2016 Conference of the North American Chapter of the Associat ion for Computational Linguistics: H u- man Langua ge Techn ologies (pp. 1250 - 1255). Fels , S. an d Hinton , G. ( 1993 ) . Glov e - talk II: A neural netw ork interface between a data - glove and a speech sy n thesizer. IEEE Transactions on Neural Networks , 4( 1):2 – 8. Fiebrink , R . (2011). Real - time human interaction w ith s u pervised learning algorithms for mu sic c omposition and pe r fo rmance. PhD thesis, Fa culty of Princeton University. Françoise, J., Schnell, N., Borghesi, R., & Bevilacqua, F. (2014 ). Probabilisti c models for designing motion a nd sound relatio n- ships. In Proceedings of the 2014 intern a tional conference on new interfaces for musical expre s sion (pp. 287 - 292). Fried , O. an d Fiebrink , R. (2 013). Cross - modal Sound Mapping Using Deep Learning. In New Interfaces for M usical E x pression (NIME 2013), Seou l, Korea. Gabriell i, L., Tomassetti , S., Squartini, S., & Zinato, C. (2017). Introducing D eep Mach ine Learning for Parameter E s timation in Physic al M odelling . In Proceedi ngs of the 20th Inte r national Conference on Digit al Audio Effects (DAFx - 17), Ed inburgh, U K Glover, J. (2015). Generating sound with recu rrent ne t works. http://www.johnglover.net/bl og/generating - sound - with - rnns.html , Last access ed 2018.02.11 Mehri, S., Kumar, K., Gulra jani , I., Kumar , R., Jain , S., Sote lo, J ., Courville , A. and Bengio, Y., (2016). SampleRNN: An uncond i- tional end - to - end neural audio ge n era tion mo del. arXiv preprint arXiv :1612.07837. Mikolo v, T., & Zweig , G. (20 12). Contex t depen dent r e current neural network language model. SLT, 12, 234 - 239. Werbos , P. J. (199 0). Bac kprop agat ion thr ough time: what it does and how to do it. Proceedings of the IEEE , 78(10). Van Den Oord , A., Di eleman, S., Zen , H., Si monyan, K., Vinya ls, O., Graves, A., Kalchbr enner, N., Senior, A. and Kavukcuoglu, K., (2016). Wavenet: A generative model for raw audio. arXiv preprint arXiv :1609.03499.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment