An empirical study on the effectiveness of images in Multimodal Neural Machine Translation
In state-of-the-art Neural Machine Translation (NMT), an attention mechanism is used during decoding to enhance the translation. At every step, the decoder uses this mechanism to focus on different parts of the source sentence to gather the most useful information before outputting its target word. Recently, the effectiveness of the attention mechanism has also been explored for multimodal tasks, where it becomes possible to focus both on sentence parts and image regions that they describe. In this paper, we compare several attention mechanism on the multimodal translation task (English, image to German) and evaluate the ability of the model to make use of images to improve translation. We surpass state-of-the-art scores on the Multi30k data set, we nevertheless identify and report different misbehavior of the machine while translating.
💡 Research Summary
The paper presents a systematic empirical study on how visual information can be integrated into neural machine translation (NMT) to improve translation quality. Starting from a standard attention‑based encoder‑decoder architecture (Bahdanau et al., 2014) with a bidirectional GRU encoder and a conditional GRU (cGRU) decoder, the authors extend the model to a multimodal setting by adding image features. Image annotations are extracted from a pre‑trained ResNet‑50 (He et al., 2016) at the res4f layer, yielding a 14 × 14 × 1024 tensor that is flattened into 196 spatial vectors (a₁…a_L).
Three distinct image‑attention mechanisms are investigated:
-
Soft Attention – a deterministic, fully differentiable approach that computes a compatibility score e_{t,l}=vᵀtanh(U_a s₀_t + W_a a_l) for every annotation, normalises the scores with a softmax to obtain α_{t,l}, and forms the image context i_t=∑α_{t,l} a_l.
-
Hard Stochastic Attention – a sampling‑based method that draws a single annotation according to the multinoulli distribution defined by α_t. The model is trained by maximising a variational lower bound on the marginal log‑likelihood, approximated with Monte‑Carlo samples and a moving‑average baseline to reduce variance.
-
Local Attention – a hybrid that predicts an aligned position p_t = S·sigmoid(vᵀtanh(U_a s₀_t)) and restricts attention to a fixed window of size 2D+1 around p_t (D≈|I|/4). A Gaussian mask centred on p_t further sharpens the focus.
Beyond the basic mechanisms, the authors propose three optimisations to increase the usefulness of visual cues:
-
Gating – a scalar β_t = σ(W_β s_{t‑1}+b_β) computed from the previous decoder state modulates the image context (i_t = β_t ∑α_{t,l} a_l), allowing the model to dynamically decide how much visual information to incorporate at each step.
-
Parameter Expansion – the weight matrices involved in computing e_{t,l} (U_a, W_a, v) are doubled in dimensionality, giving the network more capacity to model complex visual‑text interactions.
-
Grounded Attention – each annotation a_i is combined with the initial decoder state s₀ (f(a_i + s₀) with tanh), L2‑normalised, passed through two 1×1 convolutions (D→512, 512→1), and soft‑maxed to produce a second set of attention weights. This “grounded image” representation is applied before decoding, effectively filtering out image regions that are irrelevant to the source sentence.
Experiments are conducted on the Multi30K dataset (Elliott et al., 2016), which pairs English captions with professional German translations. The training set contains 29 k triples, the validation set 1 014, and the test set 1 k. All models are built with the Nematus toolkit; the encoder uses a single‑layer 1024‑dimensional forward GRU and a 1024‑dimensional backward GRU, while word embeddings are 620‑dimensional and jointly trained. Dropout (p=0.5) is applied to embeddings, encoder hidden states, and decoder states.
Results show that the Soft Attention model achieves the highest BLEU scores, surpassing previously reported state‑of‑the‑art multimodal NMT results on Multi30K. Hard Stochastic Attention suffers from training instability due to sampling variance, yielding lower scores despite its theoretical appeal. Local Attention performs competitively on examples where a single salient object dominates the image, but overall it lags behind Soft Attention. The three optimisation techniques consistently improve all three attention variants, adding roughly 0.5–0.8 BLEU points on average.
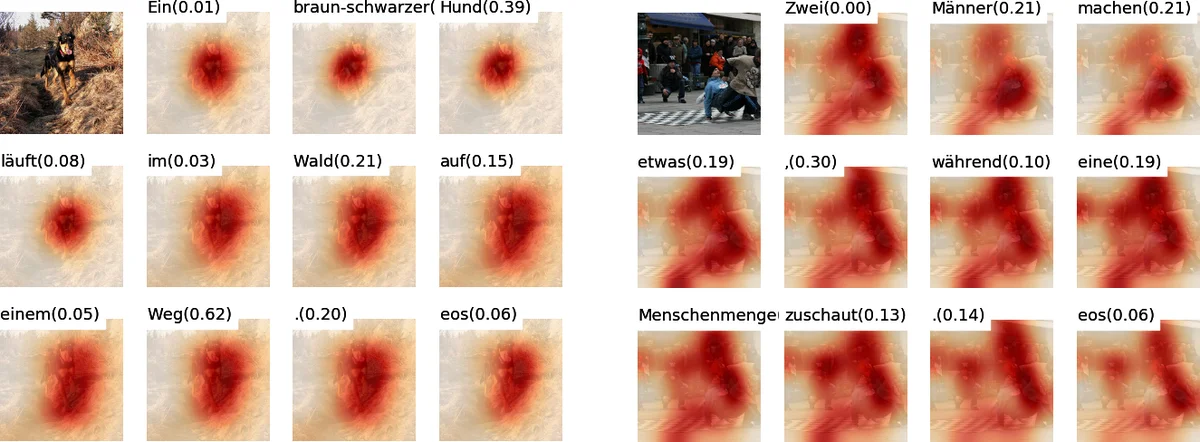
The authors also conduct a qualitative error analysis, highlighting cases where visual information helps disambiguate polysemous words, and cases where the model over‑relies on visual cues, leading to hallucinations or mistranslations. Their findings suggest that while images can provide valuable grounding for NMT, the choice of attention mechanism and the incorporation of gating/grounding strategies are crucial for realizing these benefits. The paper thus contributes both a thorough empirical benchmark of image‑attention designs and practical recommendations for building more robust multimodal translation systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment