Automatic context window composition for distant speech recognition
Distant speech recognition is being revolutionized by deep learning, that has contributed to significantly outperform previous HMM-GMM systems. A key aspect behind the rapid rise and success of DNNs is their ability to better manage large time contex…
Authors: Mirco Ravanelli, Maurizio Omologo
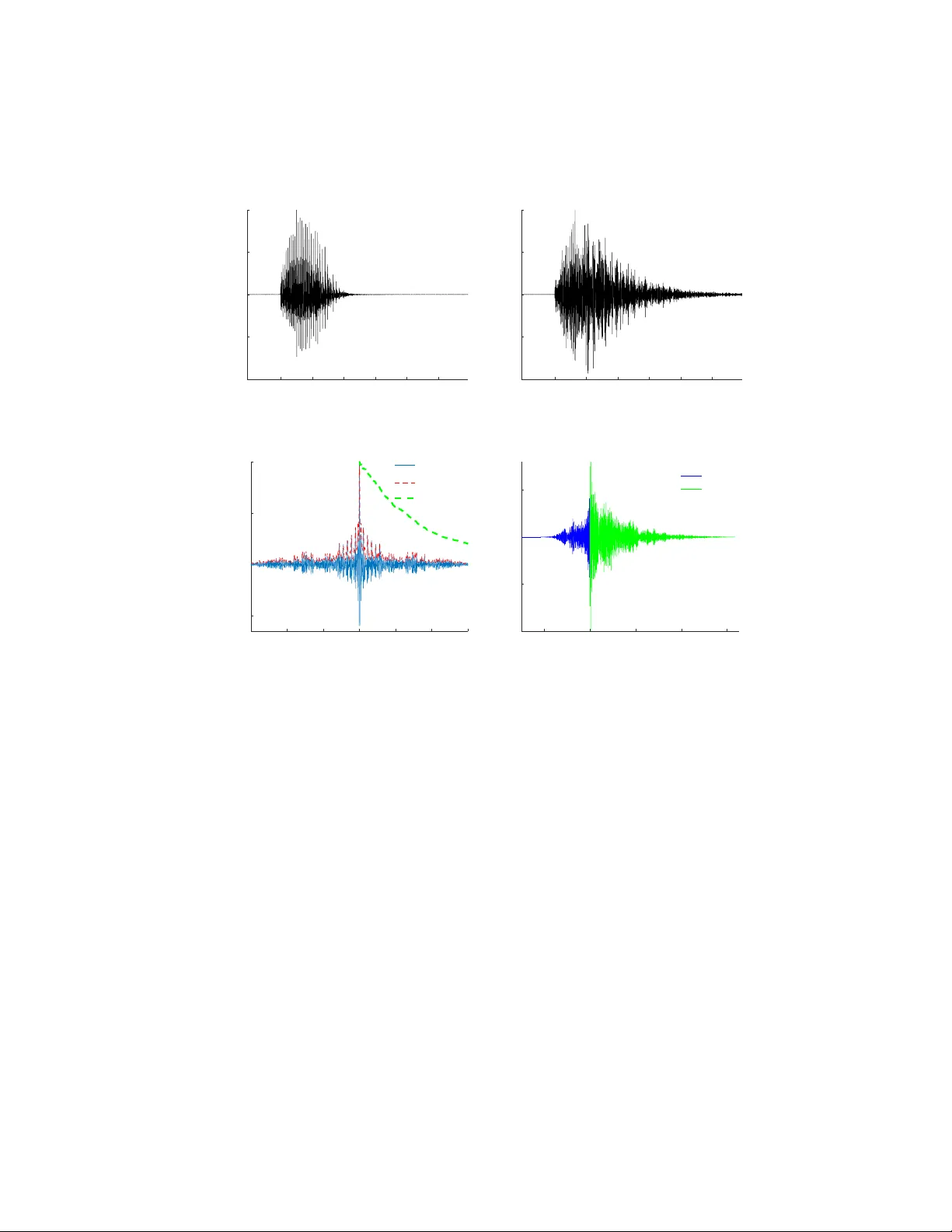
Automatic con text windo w comp osition for distan t sp eec h recognition Mirco Ra v anelli, Maurizio Omologo F ondazione Bruno Kessler, T r ento, Italy Abstract Distan t sp eec h recognition is b eing revolutionized by deep learning, that has con tributed to significan tly outp erform previous HMM-GMM systems. A key asp ect b ehind the rapid rise and success of DNNs is their abilit y to b etter manage large time contexts. With this regard, asymmetric context windows that em b ed more past than future frames hav e b een recently used with feed- forw ard neural netw orks. This context configuration turns out to b e useful not only to address lo w-latency sp eec h recognition, but also to bo ost the recognition p erformance under reverberant conditions. This pap er inv estigates on the mechanisms o ccurring inside DNNs, which lead to an effective application of asymmetric con texts. In particular, w e pro- p ose a nov el metho d for automatic context window comp osition based on a gradien t analysis. The exp erimen ts, performed with different acoustic environ- men ts, features, DNN architectures, microphone settings, and recognition tasks sho w that our simple and efficient strategy leads to a less redundant frame con- figuration, whic h makes DNN training more effective in reverberant scenarios. Keywor ds: Distan t Sp eec h Recognition, Deep Learning, Context Window, Rev erb eration 1. In tro duction Distan t Sp eech Recognition (DSR) represents a fundamental technology to- w ards flexible human-mac hine in terfaces. There are indeed v arious real-life sit- uations where DSR is more natural, conv enient and attractive than traditional Pr eprint submitted to Journal of Sp e ech Communic ation May 29, 2018 close-talking sp eec h recognition [1]. F or instance, applications such as meet- ing transcriptions and smart TVs hav e been studied ov er the past decade in the con text of the AMI/AMIDA [2] and the DICIT [3] pro jects, resp ectiv ely . More recently , sp eec h-based domestic control gained a lot of attention [4, 5]. T o this end, the EU DIRHA pro ject developed v oice-enabled automated home en vironments based on distan t-sp eech in teraction in different languages [6, 7]. Concerning this application, innov ative commercial pro ducts, suc h as Amazon Ec ho and Google Home, hav e recently been in tro duced in the mark et. Robotics, finally , represen ts another emerging scenario, where users can freely talk with distan t mobile platforms. Sev eral efforts hav e b een dev oted in the last y ears to improv e DSR technol- ogy , as witnessed by the great success of some in ternational c hallenges suc h as CHiME [8], REVERB [9], and ASpIRE [10]. A ma jor role in improving this tec hnology is b eing play ed by deep learning [11, 12, 13], which has contributed to significan tly outp erform HMM-GMM speech recognizers. Deep learning, in effect, has b een rapidly ev olving during the last years, progressiv ely offering more pow erful and robust tec hniques, including effectiv e regularization methods [14, 15], impro ved optimization algorithms [16], as well as b etter arc hitectures [17, 18, 19, 20]. A key aspect b ehind the success of deep learning in sp eec h recognition is the abilit y of mo dern DNNs to p erform predictions based on a large time con text. A v alid arc hitecture able to learn long and short-term dep endencies is represented b y Recurrent Neural Netw orks (RNNs) as Long Short-T erm Memory (LSTM) [21] or Gated Recurrent Units (GR Us) [20, 22]. In order to simultaneously manage b oth past and future time contexts, the most suitable solution would b e bidirectional RNNs [23], that turned out to automatically learn (through their recurren t connections) ho w to prop erly exploit the con textual information. The price to b e paid for automatically learning contexts from sp eech data is an increased computational complexity . LSTMs, for instance, are based on a rather complex cell design based on three m ultiplicative gates, which normally require muc h more computations at each time steps if compared to a simpler 2 feed-forw ard NN. Bidirectional RNNs, moreo ver, can generate a sequence of p osterior probabilities only after processing the en tire sen tence. Both of these features often impair their use in real-time/lo w-latency applications. T o circum ven t this drawbac k, unidirectional RNNs or feed-forward DNNs can b e used. F or lo w-latency applications, feed-forward DNNs still represent the most preferable choice for many practical applications, as witnessed by the n umerous studies in the recen t literature on real-time ASR systems op erating on devices with lo w computational p o w er [24, 25, 26, 27, 28, 29]. In line with these recent efforts, this w ork considers the aforementioned scenario, targeting standard feed-forw ard DNNs. In the case of feed-forward DNNs, the input features are typically gath- ered into a symmetric context window (SCW), that observes the current frame along with the same num b er of surrounding past and future ones. Nev erthe- less, an asymmetric context window (A CW) that integrates more past than future frames has gained popularity for real-time/lo w-latency recognition of close-talking sp eec h [29, 24, 30, 18]. Interestingly , some recent pap ers hav e also evidenced the effectiv eness of its application with distant speech recogni- tion [31, 32], though a deep analysis is missing concerning the conditions under whic h this approach b ecomes con venien t with reverberated sp eech. The goal of this w ork is to b etter understand these asp ects, and to pro- p ose a metho dology to derive an optimal context window (CW) according to the c haracteristics of the DSR task. The prop osed AutoC W algorithm, tested on different tasks, datasets, microphone configurations as well as on different acoustic environmen ts, exploits a gradient analysis p erformed at an early stage of the DNN training. Its application significan tly reduces the efforts needed to find an optimal context, while improving ASR p erformance pro vided by the use of standard SCWs. The rest of the paper is organized as follo ws. Sec. 2 analyzes the effects of A CW on sp eec h signals, input features, and DNN gradients. Sec. 3 describ es the prop osed AutoC W algorithm for automatic context window comp osition. In Sec. 4, an ov erview of the adopted exp erimen tal setup is provided, while the 3 0 100 200 300 400 500 600 Time (ms) -1 -0.5 0 0.5 1 h[n] (a) Impulse Resp onse h [ n ] 0 200 400 600 800 1000 Time (ms) -60 -40 -20 0 Log-energy (dB) T 60 =780 (ms) (b) Log-energy decay of h [ n ] Figure 1: An impulse resp onse measured in a domestic en vironment with a rev erb eration time of about 780 ms. ASR results are rep orted in Sec. 5. Finally , Sec. 6 draws our conclusions. 2. Asymmetric Context Windo w for Counteracting Rev erb eration T o b etter introduce the motiv ations b ehind the use of the ACW, it is useful to recall the effect of reverberation on a sp eech signal. Let us describ e a distan t sp eec h signal y [ n ] by the following equation: y [ n ] = x [ n ] ∗ h [ n ] + v [ n ] (1) where x [ n ] is the close-talking signal (i.e, the speech signal b efore its propaga- tion in the acoustic environmen t, whic h is assumed to b e a latent v ariable not directly observed), h [ n ] is the acoustic impulse resp onse (IR) betw een source and microphone, and v [ n ] is the additiv e noise in tro duced by the environmen t. The sp eec h signal x [ n ] is reflected many times b y walls, flo or, and ceiling as well as by ob jects within the acoustic environmen t. Such a multi-path propagation, kno wn as reverberation [33], is summarized by the IR h [ n ], that can b e mo deled as a causal FIR filter (i.e., h [ n ] = 0 ∀ n < 0). Fig. 1a sho ws an IR measured in a living-ro om, whose log-energy deca y (reported in Fig. 1b) indicates that the rev erb eration time T 60 [33] is ab out 780 ms. 4 Figure 2: HMM-DNN pip eline used for h ybrid sp eec h recognition with feed-forw ard neural netw orks. In a DSR system, the distan t-talking signal y [ n ] is pro cessed by a feature extraction function f ( · ) that computes a sequence of feature frames f ( y [ n ]) = { y 1 , ..., y k , ..., y N fr } , where eac h frame y k is a vector consisting of N f ea features, and N f r is the total n umber of frames. F eature extraction is normally carried out by splitting the signal into small c h unks (lasting 20-25 ms with an o verlap of 10 ms), and by applying a transformation to eac h ch unk. T o broaden the time con text the DSR system is not only fed with the current frame y k , but also with some surrounding ones. The set of frames feeding the system, i.e. the con text window, is defined in the following wa y: C W k = { y k + p } ∀ − N p ≤ p ≤ N f (2) where N p and N f are the num b er of past and future frames, resp ectively . In standard SCWs N p = N f , while ACWs correspond to N p 6 = N f . T o account for differen t balance factors b etw een past and future frames, let us introduce the co efficien t ρ cw defined as follo ws: ρ cw (%) = N p N p + N f · 100 (3) 5 It results that ρ cw > 50% for an asymmetric context embedding more past than future frames, ρ cw = 50% for a symmetric con text, and ρ cw < 50% when em b edding more future frames. The con text window C W k then feeds a DNN, as depicted in Fig. 2. The DNN pro cesses the input features with sev eral non-linear hidden la y ers and estimates a set of p osterior probabilities P k ( q | C W k ). The cost function C ( ˆ l, P k ( q | C W k )) optimized during training (e.g., cross-en tropy) is computed from the reference lab els ˆ l and the aforementioned predictions. 2.1. Corr elation A nalysis A function that helps study the redundancy introduced by reverberation is the cross-correlation. In particular, it is in teresting to compute the cross- correlation R xy b et w een the close-talking sp eec h x [ n ] and the corresp onding distan t-talking sequence y [ n ]. Let us assume that the additive noise v [ n ] re- p orted in Eq. 1 is omitted here, to fo cus on rev erb eration only . It can b e easily sho wn that: R xy [ n ] = M − 1 X m =0 h [ m ] · R xx [ n − m ] (4) where M and R xx [ n ] denote the finite length of the IR h [ n ], and the auto corre- lation of the close-talking signal, resp ectiv ely . The auto correlation R xx [ n ] v aries significantly according to the particular phoneme and the signal c haracteristics that are considered. Fig. 3c, for instance, sho ws the auto correlation R xx [ n ] of a v o wel /a/ , while Fig. 4c illustrates R xx [ n ] for a fricativ e /f / . One can easily observ e that differen t autocorrelation patterns are obtained: for the vo wel sound /a/ , R xx [ n ] is based on several p eaks due to pitc h and formants, while for /f / a more impulse-like pattern is observed. The spread of the autocorrelation function around its center t = 0 also dep ends on the sp ecific phoneme. If we consider, for instance, the time instan t where the energy of R xx [ n ] decays to 99.9% of its initial v alue, the auto correlation length is 104 ms with the vo wel /a/, and ab out 25 ms with the fricativ e /f/. In both cases, ho wev er, the duration of the auto correlation is significantly shorter than 6 0 100 200 300 400 500 Time (ms) -1 -0.5 0 0.5 1 x[n] /a/ (a) Close-talking signal x [ n ] 0 100 200 300 400 500 Time (ms) -1 -0.5 0 0.5 1 y[n] (b) Reverberated signal y [ n ] -150 -100 -50 0 50 100 150 Time (ms) -0.5 0 0.5 1 R xx [n] R xx [n] R xx [n]-env h[n]-env (c) Auto correlation R xx [ n ] -200 0 200 400 600 Time (ms) -1 -0.5 0 0.5 R xy [n] n<0 n>0 (d) Cross-correlation R xy [ n ] Figure 3: Cross- and auto-correlation analysis for the vo wel /a/. the IR length (see green dashed line of Fig. 3c and Fig. 4c), except in the case of a v ery lo w rev erb eration time. This characteristic, together with the causality of the impulse response ( h [ n ] = 0 ∀ n < 0), originates an asymmetric trend in the cross-correlation R xy [ n ], which can b e clearly appreciated from b oth Fig. 3d and Fig. 4d. As sho wn by the latter examples, corresp onding to a medium- high T 60 of 780 ms, the right side of this function is influenced by the IR decay . The future samples ( n > 0) are thus, on av erage, more redundant than previous ones ( n < 0), and this effect is amplified when reverberation increases, and in corresp ondence of high-energy portions of speech signals (e.g., the cen tral part of a stressed v ow el). 7 0 100 200 300 400 500 Time (ms) -1 -0.5 0 0.5 1 x[n] /f/ (a) Close-talking signal x [ n ] 0 100 200 300 400 500 Time (ms) -1 -0.5 0 0.5 1 y[n] (b) Reverberated signal y [ n ] -150 -100 -50 0 50 100 150 Time (ms) -0.2 0 0.2 0.4 0.6 0.8 1 R xx [n] R xx [n] R xx [n]-env h[n]-env (c) Auto correlation R xx [ n ] -200 0 200 400 600 Time (ms) -1 -0.5 0 0.5 R xy [n] n<0 n>0 (d) Cross-correlation R xy [ n ] Figure 4: Cross- and auto-correlation correlation analysis for the fricative /f/. A CWs are therefore more appropriate than traditional symmetric ones, since they lead to a frame configuration less affe cted by the aforementioned forward correlation effects of reverberation. In other w ords, with an asymmetric context w e can feed the DSR system with information which is, on av erage, more com- plemen tary than that considered in a standard symmetric frame configuration, allo wing the DNN to p erform more robust predictions. As emerged from Fig. 3 and 4, the b est asymmetric con text windo w would dep end on the sp ecific phoneme. Ho wev er, this is also tightly related to the degree of distortion in tro duced b y rev erb eration in the related phonetic con text, whic h can also depend on other factors (e.g., the ratio betw een the energies of 8 -200 -100 0 100 200 Time (ms) 0 0.2 0.4 0.6 0.8 1 |R xy [n]| n<0 n>0 Figure 5: En velope of the cross-correlation R xy [ n ] computed betw een clean and rev erb erated speech sentences using symmetric windo ws of 200 ms. The envelope | R xy [ n ] | is av eraged ov er all the utterances of the TIMIT dataset. the direct input sp eec h and of the reverberation comp onen t). As a matter of fact, a simple and practical solution, as outlined in the follo wing of this w ork, consists in feeding the DNN with a fixed asymmetric con text configuration that, on av erage, w orks reasonably well for any phonetic contexts in the input sp eec h signal, and for differen t environmen tal conditions. This approac h is often adopted within standard DNN-HMM sp eec h recog- nizers, where the sp eech signal is progressiv ely processed using a fixed con text windo w that might contain different sounds. T o extend our cross-correlation analysis to a more realistic setting, Fig. 5 shows the env elop e | R x,y | of the cross-correlation function av eraged ov er all the sentences of the TIMIT dataset [34]. In particular, this result is obtained considering con text windows of 200 ms and 10 ms of time shift, which resem bles the t ypical configuration used to feed DNNs under reverberated acoustic conditions, as shown in the following of the pap er. Consisten tly with what emerged from previous exp erimen ts, Fig. 5 confirms the high redundancy in tro duced by reverberation on the future sam- ples. 9 -10 -5 0 5 10 p 0.6 0.7 0.8 0.9 1 ||g p || Clean-Ep1 (a) Gradient norms at ep och 1 -10 -5 0 5 10 p 0.6 0.7 0.8 0.9 1 ||g p || Clean-Ep21 (b) Gradient norms at ep och 21 Figure 6: Gradien t norm of the various frames in a close-talking scenario ov er various training epo chs. -10 -5 0 5 10 p 0.7 0.8 0.9 1 ||g p || Rev-Ep1 (a) Gradient norms at ep och 1 -10 -5 0 5 10 p 0.7 0.8 0.9 1 ||g p || Rev-Ep21 (b) Gradient norms at ep och 21 Figure 7: Gradient norm of the v arious frames in a distan t-talking rev erb erated scenario ov er v arious training epo chs. A similar exp erimental evidence can be repro duced using other methods to analyze the correlation that holds among frames inside the CW. F or instance, the Pearson correlation coefficient [35, 36] could b e used to highlight the redun- dancy inside sequences of mel-frequency cepstral co efficien ts (MFCC) vectors that represen t reverberated sp eec h signals. 10 2.2. Gr adient A nalysis As far as DNN pro cessing is concerned, it is also of great interest to un- derstand if the netw ork is able to automatically assign different imp ortance to the different frames of the CW. Useful insights can b e gained by analyzing the gradien t norm o ver the v arious inputs of the CW, which can be defined in this w ay: k g p k = ∂ C ∂ y p ∀ p ∈ {− N p , ..., 0 , ..., N f } (5) where C is the cost function used for DNN training and y p is the p -th feature frame em b edded in the CW. In the case of cross-en tropy cost, the gradien t norm can b e written as: k g p k = 1 N tr N tr X i =1 ∂ P N e k =1 P N o j =1 ˆ l i,k,j · l og P i,k,j ( q j |{ y i,k,p } ) ∂ y p (6) where N tr is the n umber of training mini-batches, N e is the n umber of train- ing samples in each mini-batc h, N o is the num b er of phone-states, while ˆ l i,k,j and P i,k,j are the label and the DNN output of eac h training example, resp ec- tiv ely . The DNN output P i,k,j dep ends on the con text windows C W i,k that is written here as { y i,k,p } to highlight its dependency on the p -th frame. Note also that the gradien t norm is av eraged ov er all the training mini-batches in order to pro vide a more reliable estimation Fig. 6 and 7 shows k g p k for a close-talking and a distant-talking case, re- sp ectiv ely , whic h was computed by considering the first and the last training ep ochs. The results are derived from sequences of MF CC feature v ectors, and using the DIRHA-WSJ dataset [7] with the DNN setup that will be describ ed in Sec. 5. The tw o figures highlight that the netw ork is able to automatically assign more imp ortance to the current frame (p=0). In b oth cases, the gradient norm k g p k clearly decreases when progressively moving far aw ay from the curren t frame. How ever, a symmetric behavior is observ ed in the close-talking case only , 11 Algorithm 1 Automatic context window comp osition using gradien t analysis. 1: T rain a DNN with a large symmetric context windo w C W max for one ep o c h. 2: Compute the gradient norm || g p || , ∀ p ∈ [ − ( C W max − 1) / 2 , ( C W max − 1) / 2]. 3: for C W len in range ( C W min , C W max ) do 4: N p = 0, N f = 0 5: for i in range ( C W len -1) do 6: if || g − N p − 1 || > || g N f +1 || then N p = N p + 1 7: else N f = N f + 1 8: T rain the DNN with N p past frames and N f future frames. 9: Ev aluate the WER p erformance on the dev-set. 10: Store { N p , N f ,WER } for the giv en C W len . 11: Choose the context window with the b est p erformance whic h means that the netw ork has no preference for past or future information. On the other hand, the net work learns to place more imp ortance to past ( p < 0) rather than to future frames ( p > 0) for rev erb erated speech. This can b e readily appreciated from the asymmetric trend achiev ed in Fig. 7, which is a further indication of the p ossible b enefits deriving from the use of ACWs. In terestingly , the netw ork learns which frames are more imp ortan t since the first training ep o c h, as evidenced by the similar trends rep orted in Fig. 6a and 7a. This is an imp ortant exp erimen tal evidence, whic h suggested us to dev elop the algorithm introduced in the next section, to effectiv ely optimize the h yp erparameters of the A CW. 3. Automatic context windo w comp osition The c haracteristics of the context window are of paramoun t importance to impro ve the ASR p erformance. Particular attention should th us be devoted to deriv e a prop er frame configuration, carefully optimizing (on the developmen t set) the main features of the con text window (i.e., N p , N f ). A ma jor limitation of the A CW is that it in tro duces t wo h yp erparameters 12 (i.e., N p and N f ), while only one (i.e, the total length of the context C W len ) is needed for standard symmetric con texts. The introduction of an additional h yp erparameter has a dramatic impact on the num b er of combinations to test during the optimization step. A grid search ov er a single hyperparameter, in fact, has a linear complexity O ( C W len ), while the joint optimization of both N p and N f has a quadratic complexity O ( C W 2 len ). F or instance, if we consider a SCW, with a total length C W len that v aries from 11 to 25 frames, only 15 DNN training exp eriments are necessary , against the 270 required with an exhaustiv e grid search. It is thus of great interest to develop a metho dology to optimize more efficien tly the hyperparameters of the ACW. The approach prop osed in this pap er is based on the gradient norm analysis in tro duced in the previous section. The norm of the gradient o ver the v arious frames, in fact, giv es quickly an idea ab out what frames are considered im- p ortan t b y the net work. Based on this observ ation, we propose the algorithm referred to as AutoC W (Alg. 1), to automatically compose the CW. The idea is to first train a DNN with a very large SCW (e.g. 25 frames) for a single ep och. After the first ep o c h, the gradient norm k g p k ov er the v arious input frames is computed. The CW is comp osed by progressively embedding, at each iteration, the past or future frame that maximizes the gradien t norm. The cy- cle is stopped when the predefined num b er of con text frames C W len has been reac hed. A new DNN can then be trained with the CW { N p , N f } determined b y the proposed procedure, and the corresp onding ASR p erformance is ev aluated on a dev elopment data set. This operation is repeated for all the CW lengths within a predefined range ( C W min ≤ C W len ≤ C W max ), and, after that, the frame configuration { N p , N f } pro viding the b est ASR p erformance is selected. Note that this algorithm allows one to optimize the frame configuration of the asymmetric con text window with a linear computational complexity , that is comparable to that required for standard symmetric windows. F or each con text windo w length C W len , in fact, the optimal configuration { N p , N f } is automat- ically inferred from the gradient norm profile, allo wing one to av oid exploring the full set of con text configurations. Similarly to SCW, if w e consider a con text 13 Acoustic Condition T raining T est Close-talking (Clean) WSJ-clean DIRHA-WSJ-clean Close-talking (Clean) LibriSp eec h LibriSp eec h Distan t-talking (Rev) WSJ-rev DIRHA-WSJ-rev Distan t-talking (Rev) Rev-LibriSp eec h Rev-LibriSp eec h Distan t-talking (Rev&Noise) WSJ-rev DIRHA-WSJ-rev&noise T able 1: List of the exp erimental tasks considered in this work with the related training and test datasets. windo w length ranging from C W min =11 to C W max =25 frames, only 15 DNN training exp erimen ts are necessary to find a prop er context window. 4. Exp erimen tal Setup The experimental framework dev elop ed in this work is based on the use of b oth WSJ-5k and LibriSp eec h tasks. T o pro vide an accurate analysis of the prop osed approach, the exp erimen ts are p erformed under three differen t acous- tic conditions of increasing complexity: close-talking ( Cle an ), distant-talking with rev erb eration ( R ev ), and distan t-talking with both noise and reverberation ( R ev&Noise ). The corp ora used for each exp erimental condition are summa- rized in T able 1 and describ ed in the t wo follo wing sections. The adopted ASR setup will b e describ ed in Sec. 4.3. 4.1. Close-talking exp eriments F or close-talking exp erimen ts, we consider the standard WSJ dataset (i.e., WSJ-clean) for training, and the close-talking p ortion of the DIRHA English WSJ Dataset (i.e., DIRHA-WSJ-clean) for test purp oses. The latter dataset w as acquired during the DIRHA pro ject in a recording studio of FBK, using professional equipmen t to obtain high-quality sp eech material [7]. In this work, w e used a subset of the corpus, consisting of 409 WSJ sentences (with the same 14 text used for the CHiME [8] challenge) uttered by six US sp eak ers (three males and three females). T o ev aluate the prop osed metho d on a larger scale ASR task, additional exp erimen ts w ere p erformed with the LibriSp eech dataset [37], that is based on sp eec h material deriv ed from read audio-b ooks. In particular, we used a training subset consisting of 460 hours of sp eec h uttered by 1172 sp eak ers. 4.2. Distant-talking exp eriments The reference environmen t for sev eral exp erimen ts conducted in this study is the living-ro om of a real apartment (a v ailable under the DIRHA pro ject) with a rev erb eration time T 60 of ab out 780 ms. The living-ro om w as equipp ed with a microphone netw ork comp osed of 40 microphones. An IR measurement session, exploring a large n umber of p ositions and orientations of the sound source, w as conducted in the aforemen tioned targeted en vironment with the purp ose of generating realistic simulated data. More information on the adopted IR estimation pro cedure can b e found in [38, 39]. A set of exp eriments is carried out to study distant-talking conditions where only rev erb eration acts as a source of disturbance (Rev). In this case, training is p erformed using a contaminated dataset (i.e., WSJ-rev), which is generated by con volving the original WSJ-clean data set with a set of three IRs chosen from the aforemen tioned collection. The corresp onding test data set, i.e. DIRHA- WSJ-rev, is based on a con taminated version of DIRHA-WSJ-clean. In order to simulate several sp eak er p ositions and orien tations, a set of 36 IRs (different from those used for training) is used for the latter dataset. T o explore more challenging conditions characterized b y b oth noise and re- v erb eration (Rev&Noise), real recordings hav e also b een p erformed. The real recordings, referred to as DIRHA-WSJ-rev&noise, are part of the recen tly- released DIRHA English WSJ corpus [7] and are comp osed of 409 WSJ sen- tences (with the same texts used to record DIRHA-WSJ-clean) uttered by six US sp eak ers. Eac h sub ject reads a set of WSJ sen tences from a tablet, standing still or sitting on a chair. Ev ery 11-12 sen tences, he/she was asked to mo ve 15 to a new p osition and take another orientation. Different typologies of non- stationary domestic noises affect the signals (e.g., v acuum cleaner, microw av e noise, interfering speakers talking in other ro oms, kitchen tools, op en window noises,etc.), resulting in an av erage SNR of ab out 10 dB (for more details see [7] 1 ). T o test our approach in different contexts, other contaminated v ersions of the training and test data are generated with differen t IRs (either measured in other real en vironmen ts, or computed with the image method [40]), as discussed in Sec. 5.2 and Sec. 5.3. Other exp erimen ts are p erformed with a rev erb erated version of the Lib- riSp eec h dataset [37]. The original close-talking sen tences are conv olved with 2145 IRs, that are measured in v arious p ositions and with different microphone configuration of the aforemen tioned living-room. The tw o test sets (here denoted as T est1 and T est2 ), are comp osed of 2620 sentences uttered by 40 sp eak ers, and 2939 sentences uttered by 33 sp eak ers, respectively . The test sentences are conv olved with ab out 2000 IRs, corresp onding to sp eaker positions and mi- crophones different from those used for training. Note that the test data of the Librisp eech corpus are originally clustered so that low er-WER sp eakers are gathered in to T est1 , while the others are in T est2 . 4.3. DNN and ASR setup In this work, we use a context-dependent DNN-HMM sp eech recognizer, where ev ery unit is mo deled b y a three state left-to-righ t HMM, and the tied- state observ ation probabilities are estimated through a DNN. F eature extraction is based on splitting the signal into frames of 25 ms with an o verlap of 10 ms. The exp erimental activit y is conducted considering differen t acoustic features, i.e., 39 MFCCs (13 static+∆+∆∆), 40 log-mel filter- bank features (FBANKS), as well as 40 fMLLR features (extracted as rep orted in the s5 recip e of Kaldi [41]). F eatures of consecutive frames are gathered in to 1 This dataset is distributed by the Linguistic Data Consortium (LDC). 16 b oth symmetric and asymmetric observ ation windows. As for MF CCs, it is w orth mentioning that one could conduct this study without using deriv ativ es. In the latter case, the exp erimental results would b e quite similar at qualitative lev el. In other words, w e w ould obtain a trend that reflects what rep orted in the following section, though with a more prominent relative decrease of p erformance when adopting a non-optimal context length settings, b ecause of a less effectiv e wa y the contextual information is exploited. F or this reason, here we prefer to rep ort results related to the use of the first and second order deriv atives. WSJ exp eriments are based on DNNs comp osed of six sigmoid-based hid- den lay ers of 2048 neurons, that are trained with the Kaldi to olkit [41] (Karel’s recip e). W eigh ts are initialized with the standard Glorot initialization [42], while biases are initialized to zero. T raining is p erformed with Sto chastic Gradient Descend (SGD) that optimizes the cross-entrop y loss function. The training ev olution is monitored using a small v alidation set (10% of the training data) that is randomly extracted from the training corpus. The performance on the v alidation set is monitored after each ep o c h to p erform learning rate annealing as w ell as for c hecking the stopping condition. In particular, the initial learn- ing rate is kept fixed at 0.008 as long as the incremen t of the frame accuracy on the v alidation is higher than 0.5%. F or the following ep o c hs, the learning rate is halved un til the increment of frame accuracy is less than the stopping threshold of 0.1%. The labels for DNN training are deriv ed from an alignmen t on the tied states, whic h is p erformed with a previously-trained HMM-GMM acoustic mo del [41]. F or Conv olutional Neural Netw ork (CNNs) exp erimen ts, w e replace the first t wo fully-connected la yers of the abov e-mentioned DNN with t wo conv olutional lay ers based on 128 and 256 filters, resp ectiv ely . Librisp eec h experiments rely on the standard nnet 2 implementation of Kaldi, whic h emplo ys a generalized maxout netw ork (p-norm). In particular, our ex- p erimen ts are based on a four hidden la yer p-norm arc hitecture trained for 10 ep ochs with minibatches of size 128. The initial learning rate is set to 0.01, while the final one is 0.001. See [43] and the k aldi recip e in Libr ispeech/s 5 for 17 more details. 5. ASR Results In the follo wing, w e rep ort the exp erimen tal results obtained on the ad- dressed ASR tasks. In Sec. 5.1, a comparison b etw een SCWs and ACWs is conducted considering different context configurations, input features as well as DNN architectures. In Sec. 5.2, w e test the p erformance of the prop osed AutoC W algorithm with different recognition tasks and real acoustic en viron- men ts, while in Sec. 5.3 we extend the sp eec h recognition v alidation by simu- lating differen t reverberation times. 5.1. R everb er ant sp e e ch r e c o gnition with asymmetric c ontext windows F rom the preliminary study on ACWs, carried out in the previous sections, w e found that the training of distant-talking DNNs tends to naturally attribute more importance to past rather than future frames. In this section, we take a step forw ard by v erifying whether this fact is also observed in terms of recog- nition p erformance. With this purp ose, Fig. 8 shows the W ord Error Rate (WER) results obtained in close-talking (Clean) and rev erb erant (Rev) condi- tions, when using fully asymmetric (i.e., single side) con text windo ws of differ- en t lengths. Negativ e x-axis refers to the progressive in tegration of past frames only ( ρ cw =100%), while p ositive x-axis refers to future frames ( ρ cw =0%). In this set of exp erimen ts, fMLLR features were used as input to the DNN, for b oth DIRHA-WSJ-clean and DIRHA-WSJ-rev tasks. Note that similar trends ha ve b een obtained with b oth MFCCs and FBANK features. Results highlight that a rather symmetric b ehavior is attained in the close- talking case (Fig. 8a), reiterating that in such contexts past and future in- formation pro vides a similar con tribution to impro ve the system p erformance. Differen tly , the role of past information is significantly more important in the distan t-talking case, since a faster decrease of the WER(%) is observed when past frames are progressively concatenated (Fig. 8b). This result is in line with 18 -10 -5 0 5 10 CW Length 3.7 3.9 4.1 4.3 4.5 WER (%) Clean (a) Close-talking scenario (Clean) -20 -10 0 10 20 CW Length 16 18 20 22 24 WER (%) Rev (b) Distant-talking scenario (Rev) Figure 8: WER(%) obtained with DNN context windows that progressively integrate only past or future frames (using fMLLR features). Results refer to the use of DIRHA-WSJ-clean (a), and DIRHA-WSJ-rev (b), tasks. the findings emerged in the previous sections, and it confirms that an A CW is more suitable than a traditional symmetric one when reverberation arises. In the previous exp erimen t, w e tested only fully asymmetric windows with ρ cw =0% (future frames) or ρ cw = 100% (past frames). Ho wev er, it is worth addressing hybrid configurations, where b oth past and future frames are con- sidered. With this purp ose, Fig. 9 compares this kind of asymmetric windo w under b oth close-talking and distan t-talking conditions, using contexts of differ- en t durations. F or each CW length, the asymmetric CW curve represents the b est ASR p erformance among all the configurations that derive from v arying the balance factor ρ cw . Fig. 10 shows the results obtained with the Librisp eech task, by adopting the CW lengths that turned to b e optimal in the case of DIRHA-WSJ task (i.e., 11 in the close-talking condition and 19 for the rever- b erated case). F rom the close-talking exp erimen ts, it emerges that the standard SCW sligh tly outp erforms the b est asymmetric one, as clearly highlighted by Fig. 9a. This trend is also confirmed in Fig. 10a, where different context windo ws of length 11 ha ve b een tested on the close-talking version of Librisp eech. In 19 5 10 15 20 CW Length 3.6 3.9 4.1 4.3 4.5 WER (%) Symmetric CW Asymmetric CW Clean (a) Close-talking scenario 5 10 15 20 CW Length 15 16 17 18 19 WER (%) Symmetric CW Asymmetric CW Rev (b) Reverberated Scenario Figure 9: Comparison b et ween SCW and ACW under both a close-talking and distant-talking reverberated conditions (using fMLLR features). Results refer to the used of DIRHA-WSJ- clean (a), and DIRHA-WSJ-rev (b) tasks. 7-1-3 6-1-4 5-1-5 4-1-6 3-1-7 5 5.1 5.2 5.3 5.4 5.5 5.6 5.7 WER(\%) Clean (a) Close-talking scenario 12-1-6 11-1-7 10-1-8 9-1-9 8-1-10 21.2 21.4 21.6 21.8 22 22.2 22.4 WER(\%) Rev (b) Reverberated Scenario Figure 10: WER(%) obtained with different context configurations for the close-talking and reverberated version of Librispeech (T est1, fmllr features). b oth cases, the gap b et w een symmetric and asymmetric contexts is not so large (on a verage less than 2% relative decrease), but it suggests to use an ACW in close-talking scenarios only when real-time/lo w-latency constraints arise. Differen tly , Fig. 9b shows that the asymmetric window consisten tly out- p erforms the standard symmetric one in the distan t-talking case, for all the considered context durations. On a v erage, about 5% relative WER decrease is 20 Arc hitecture F eatures SCW (9-1-9) A CW (11-1-7) DNN fMLLR 15.2 14.8 DNN MF CC 21.8 20.8 DNN FBANK 20.7 20.2 CNN FBANK 18.5 18.1 T able 2: Comparison b etw een the WERs(%) achiev ed with SCWs and ACWs, when differen t features and DNN architectures are used. obtained with, essentially , no additional computational cost. This result is also confirmed b y Fig. 10b, that rep orts the p erformance obtained on the rev er- b erated Librispeech for v arious CW settings. This figure not only shows that an asymmetric windo w that embeds more past than future frames is a proper c hoice when rev erb eration arises, but it also highlights that the opp osite setting (i.e., embedding more future than past frames) leads to a rather significant loss of p erformance. Previous exp erimen ts were based on fMLLR features. In T able 2 w e ex- tend the exp erimental v alidation to other acoustic features, suc h as FBANK and MF CC coefficients. W e also consider CNNs as an alternative to the fully- connected DNNs used so far. Results confirm that the A CW outp erforms the symmetric one in all the considered settings. The last row of T able 2 also high- ligh ts an interesting p erformance improv ement achiev ed with CNNs. CNNs are based on local connectivit y , weigh t sharing, and p ooling op erations that allow them to exhibit some inv ariance to small feature shifts along the frequency axis, with well-kno wn b enefits against sp eaker and environmen t v ariations [17]. Hence, they represen t a v alid alternative to fully-connected DNNs, also jointly used with A CW under reverberant conditions. T o study the effectiveness of asymmetric con texts under mismatc hing condi- tions (that often arise in real applications), we no w train the DSR system with rev erb erated data (Rev) and test it on real signals (DIRHA-WSJ-rev&noise) affected b y b oth noise and reverberation. Fig. 11a sho ws the results obtained 21 -20 -10 0 10 20 CW Length 27 29 31 33 35 37 WER (%) Rev&Noise (a) F ully asymmetric context 5 10 15 20 CW Length 27 28 29 30 31 32 33 WER (%) Symmetric CW Asymmetric CW Rev&Noise (b) Symmetric vs asymmetric CW. Figure 11: Comparison between SCW and ACW under mismatched conditions. T raining is performed using reverberated data (using WSJ-rev), while test material is corrupted by both noise and reverberation (DIRHA-WSJ-rev&noise). fMLLR features are used in this experiment. when fully ACWs are adopted. Fig. 11b, instead, compares symmetric and optimal asymmetric windows, with differen t CW lengths. Due to the more c hallenging conditions characterizing this test, WER(%) is significantly worse than that highlighted in Fig. 8b and Fig. 9. How ev er, it is worth noting that the b enefits deriving from the use of ACWs are maintained even under the addressed mismatc hing case. 5.2. ASR exp eriments with automatic c ontext window c omp osition As discussed in Sec. 3, the hyperparameters N p and N f of the ACW can b e deriv ed by applying AutoC W (Alg. 1). In this section, we conduct a set of ex- p erimen ts to ev aluate the loss of p erformance introduced by it, when compared to the ideal (and computational exp ensiv e) conditions under which previous ex- p erimen ts (in Fig. 11b) w ere performed. Let us recall that, in the latter cases, a grid optimization w as done ov er all the p ossible CW combinations. The first ro w of T able 3 shows the results obtained with the aforementioned mismatc hing condition. The b est p erformance, 27.2 % WER, is obtained using an optimal CW 11-1-7, that is an ov erall length of 19 frames. It is ho wev er 22 T 60 (ms) SCW A CW (opt) AutoCW DIRHA-WSJ-rev&noise CW 8-1-8 11-1-7 12-1-6 WER 27.9 27.2 27.3 Rev-LibriSp eec h (T est1) CW 9-1-9 11-1-7 11-1-7 WER 22.1 21.4 21.4 Rev-LibriSp eec h (T est2) CW 9-1-9 11-1-7 11-1-7 WER 51.3 50.1 50.1 T able 3: Comparison b et ween WER(%) obtained with SCW, the optimal asymmetric one (ACW opt), and with the context configuration deriv ed b y our algorithm ( AutoC W ). The experiments are p erformed with fMLLR features. w orth noting that applying AutoC W leads to a v ery similar combination, i.e., 12-1-6, is obtained, whic h corresponds to a comparable recognition performance, i.e., 27.3% WER. The last t wo ro ws, instead, rep ort the results ac hieved with the reverberated v ersion of Librisp eech. In this case, the prop osed AutoC W algorithm provides a CW setting that corresp onds to the optimal choice. F or b oth recognition tasks, we can also observe that applying AutoC W leads to 2-3% relativ e reduction of WER provided by the SCW. Another set of experiments concerns a differen t kind of mismatc h that o ccurs when training and test are p erformed in different acoustic environmen ts. As re- p orted in T able 4, training w as carried out in the DIRHA living-room, using the WSJ-rev corpus, while test is p erformed in three different con texts, i.e., an of- fice, a surgery ro om, as well as a ro om of another apartment. The test data were generated following the approac h described in Sec. 4.2 for DIRHA-WSJ-rev, but using real IRs that were measured in the aforementioned en vironments. Results sho w that the use of ACW introduces adv an tages in terms of ASR p erformance under all the tested conditions, ev en when training and test are p erformed in differen t acoustic en vironments. Moreo ver, the application of AutoC W provides a CW composition 12-1-6, very similar to the optimal one, which corresponds to a 2-3% relativ e WER reduction, if compared to the p erformance obtained 23 X X X X X X X X X X X X X X X Env. Context Wind. SCW (opt) ACW (opt) AutoCW 9-1-9 11-1-7 12-1-6 Office ( T 60 = 650 ms) 16.6 16.2 16.2 Home ( T 60 = 700 ms) 19.5 19.1 19.3 Surgery Ro om ( T 60 = 850 ms) 21.4 20.3 20.5 T able 4: WER(%) obtained with SCWs and ACWs, in different acoustic environments and under mismatc hed conditions. T raining is p erformed in the DIRHA livingro om ( T 60 =750ms) using WSJ-rev, while test is p erformed in different acoustic environmen ts with different re- verberation times. using SCW. 5.3. Performanc e analysis with differ ent r everb er ation times As p ointed out abov e, the application of AutoC W can ha ve a differen t im- pact according to the rev erb eran t conditions under which training and test are p erformed. Concerning this, w e further extended our v alidation b y sim ulating acoustic environmen ts with increasing reverberation times T 60 . F or this study , a set of IRs simulated with the image method [40] w ere used to contaminate b oth training (WSJ-clean) and testing corp ora (DIRHA-WSJ-clean). T able 5 summarizes the results obtained with T 60 ranging from 250 ms to 1000 ms. As exp ected, results show that the p erformance progressively degrades as T 60 increases. More in terestingly , the asymmetric window is able to o v ertake stan- dard symmetric ones in all the explored reverberant conditions. It is also w orth noting that larger contexts are needed when increasing the rev erb eration time, as highlighted in Fig. 12a. F or instance, when T 60 =250 ms the optimal window in tegrates only 11 frames, while 25 frames are necessary when T 60 =1000 ms. In terestingly enough, the co efficien t ρ cw , that measures the amoun t of asym- metricit y in the CW, increases as the rev erb eration time increases (see Fig. 12b). This means that the rev erb eration effects significantly reduce the use- fulness of future frames in the case of large T 60 s, which mak es conv enient the use of more asymmetric context windows. It is worth noting that the prop osed 24 T 60 (ms) SCW ACW (opt) AutoCW 0 ms CW 5-1-5 6-1-4 5-1-5 WER 3.6 3.7 3.6 250 ms CW 5-1-5 6-1-4 6-1-4 WER 5.5 5.1 5.1 500 ms CW 6-1-6 7-1-5 8-1-4 WER 9.1 8.5 8.7 750 ms CW 9-1-9 12-1-6 11-1-7 WER 15.2 14.8 14.9 1000 ms CW 12-1-12 18-1-6 19-1-5 WER 20.5 20.1 20.1 T able 5: Comparison b etw een WER(%) obtained with SCW and A CW under different rever- beration conditions. The last column rep orts the results obtained with the proposed AutoC W algorithm. AutoC W algorithm pro vides nearly optimal con texts, that lead to a negligible p erformance reduction ov er the b est CW for all the considered rev erb eration times. Under close-talking conditions ( T 60 =0 ms), AutoC W correctly derives a symmetric context window of 11 frames. Similarly to the optimal case, the pro- p osed metho d correctly provides longer and more asymmetric context windows when rev erb eration increases. 6. Conclusions In this pap er, we extensiv ely studied the role pla yed b y ACWs to coun teract the adverse effects of reverberation in a distant sp eec h recognizer. Under these en vironmental conditions, this windowing mechanism has pro ven to b e a viable alternativ e to a more standard symmetric context. The asymmetric window, in fact, feeds the DNN with a more conv enient frame configuration whic h carries, on a verage, information that is less redundant and less affected by the correlation effects in tro duced b y reverberation. 25 0 250 500 750 1000 T60 (ms) 10 15 20 25 CW Length (a) Length of the context window vs T 60 . 0 250 500 750 1000 T60 (ms) 0.5 0.55 0.6 0.65 0.7 0.75 ρ cw (b) ρ cw vs T 60 . Figure 12: Main features of the optimal context window for different rev erb eration times. T o optimize the characteristics of the asymmetric context windo w, this work prop osed a nov el algorithm that analyzes the norm of the DNN gradients ov er the v arious input frames. The AutoC W algorithm, tested on different tasks, datasets, and environmen ts turned out to derive nearly optimal windows under differen t acoustic conditions. Our metho d, that is characterized by a linear computational complexity , is significantly more efficient than the traditional grid search optimization ov er all the p ossible frame configurations, whic h has a quadratic complexit y . As previously mentioned, an op en issue is represented by the flexibility of the proposed approach to tackle p ossible c hanges of the reverberant conditions. This issue can b e addressed in several p ossible wa ys, for instance by combining the current solution with a pre-pro cessing step that realizes a preliminary envi- ronmen tal classification, which aims at selecting in real-time the most suitable asymmetric con text as well as the related neural netw ork. Ov erall, the use of A CW and of AutoC W turns out to represen t a simple and effectiv e approac h to impro ve DSR p erformance under noisy and rev erb eran t conditions, in particular with medium-high reverberation times, and for the dev elopment of real-time low-complexit y applications. 26 References References [1] M. W¨ olfel, J. McDonough, Distan t Sp eec h Recognition, Wiley , 2009. [2] S. Renals, T. Hain, H. Bourlard, Interpretation of Multipart y Meetings the AMI and Amida Pro jects, in: Pro c. of HSCMA, 2008, pp. 115–118. [3] M. Omologo, A protot yp e of distan t-talking interface for control of in ter- activ e TV, in: Pro c. of ASILOMAR, 2010, pp. 1711–1715. [4] B. Lecouteux, M. V acher, F. P ortet, Distan t Speech Recognition in a Smart Home: Comparison of Several Multisource ASRs in Realistic Conditions, in: Pro c. of Interspeech, 2013, pp. 2273–2276. [5] I. Ro domagoulakis, P . Giannoulis, Z. I. Sk ordilis, P . Maragos, G. Potami- anos, Exp eriments on far-field multic hannel speech pro cessing in smart homes, in: Pro c. of DSP , 2013, pp. 1–6. [6] L. Cristoforetti, M. Rav anelli, M. Omologo, A. Sosi, A. Abad, M. Hag- m ueller, P . Maragos, The DIRHA simulated corpus, in: Pro c. of LREC, 2014, pp. 2629–2634. [7] M. Rav anelli, L. Cristoforetti, R. Gretter, M. Pellin, A. Sosi, M. Omologo, The DIRHA-English corpus and related tasks for distant-speech recognition in domestic en vironments, in: Pro c. of ASRU, 2015, pp. 275–282. [8] J. Bark er, R. Marxer, E. Vincent, S. W atanab e, The third CHiME Sp eec h Separation and Recognition Challenge: Dataset, task and baselines, in: Pro c. of ASRU, 2015, pp. 504–511. [9] K. Kinoshita, et al., The rev erb c hallenge: A Common Ev aluation F rame- w ork for Derev erb eration and Recognition of Rev erb eran t Speech, in: Pro c. of W ASP AA 2013, pp. 1–4. 27 [10] M. Harper, The Automatic Sp eec h recognition In Reverberant Environ- men ts (ASpIRE) challenge, in: Pro c. of ASRU, 2015, pp. 547–554. [11] I. Goo dfello w, Y. Bengio, A. Courville, Deep Learning, MIT Press, 2016, http://www.deeplearningbook.org . [12] D. Y u, L. Deng, Automatic Sp eec h Recognition - A Deep Learning Ap- proac h, Springer, 2015. [13] G. Hinton, L. Deng, D. Y u, G. Dahl, A. Mohamed, N. Jaitly , A. Senior, V. V anhouck e, P . Nguyen, T. Sainath, B. Kingsbury , Deep neural net works for acoustic mo deling in sp eech recognition, Signal Pro cessing Magazine. [14] N. Sriv astav a, G. Hinton, A. Krizhevsky , I. Sutskev er, R. Salakhutdino v, Drop out: A simple wa y to prev ent neural netw orks from ov erfitting, Journal of Mac hine Learning Research 15 (2014) 1929–1958. [15] S. Ioffe, C. Szegedy , Batch normalization: Accelerating deep net work train- ing by reducing internal cov ariate shift, in: Pro c. of ICML, 2015, pp. 448– 456. [16] D. Kingma, J. Ba, Adam: A metho d for sto chastic optimization, in: Pro c. of ICLR, 2015. [17] O. Ab del-Hamid, A. R. Mohamed, H. Jiang, L. Deng, G. Penn, D. Y u, Con volutional neural net works for speech recognition, IEEE/A CM T rans- actions on Audio, Sp eec h, and Language Pro cessing 22 (10) (2014) 1533– 1545. [18] V. P eddinti, D. Po vey , S. Kh udanpur, A time delay neural net work ar- c hitecture for efficien t modeling of long temp oral con texts, in: Pro c of In tersp eec h, 2015, pp. 3214–3218. [19] Y. Zhang, G. Chen, D. Y u, K. Y ao, S. Khudanpur, J. R. Glass, High wa y long short-term memory RNNS for distant sp eec h recognition, in: Pro c. of ICASSP , 2016, pp. 5755–5759. 28 [20] K. Cho, B. v an Merrien b oer, D. Bahdanau, Y. Bengio, On the properties of neural machine translation: Encoder-deco der approaches, in: Proc. of SSST, 2014. [21] S. Ho chreiter, J. Sc hmidhuber, Long short-term memory , Neural Compu- tation 9 (8) (1997) 1735–1780. [22] M. Rav anelli, P . Brakel, M. Omologo, Y. Bengio, Improving sp eech recog- nition b y revising gated recurrent units, in: Pro c. of Interspeech, 2017. [23] A. Grav es, N. Jaitly , A. Mohamed., Hybrid sp eec h recognition with Deep Bidirectional LSTM, in: Pro c of ASRU, 2013. [24] G. Chen, C. Parada, G. Heigold, Small-footprint keyw ord sp otting using deep neural net works, in: Pro c. of ICASSP , 2014, pp. 4087–4091. [25] Y. W ang, J. Li, Y. Gong, Small-fo otprin t high-p erformance deep neural net work-based sp eec h recognition using split-VQ, in: Pro c. of ICASSP , 2015, pp. 4984–4988. [26] G. Chen, C. Parada, G. Heigold, Small-footprint keyw ord sp otting using deep neural net works, in: Pro c. of ICASSP , 2014, pp. 4087–4091. [27] T. N. Sainath, C. Parada, Con volutional neural net works for small-footprint k eyword sp otting, in: Pro c. of Interspeech, 2015, pp. 4087–4091. [28] T. Hori, S. Araki, T. Y oshiok a, M. F ujimoto, S. W atanab e, T. Oba, A. Ogaw a, K. Otsuk a, D. Mik ami, K. Kinoshita, T. Nak atani, A. Nak a- m ura, J. Y amato, Lo w-latency real-time meeting recognition and under- standing using distan t microphones and omni-directional camera, IEEE T ransactions on Audio, Speech, and Language Pro cessing 20 (2) (2012) 499–513. [29] X. Lei, A. Senior, A. Gruenstein, J. Sorensen, Accurate and compact large v o cabulary sp eec h recognition on mobile devices., in: Pro c. of In tersp eec h, 2013, pp. 662–665. 29 [30] A. K. Dhak a, G. Salvi, Semi-sup ervised learning with sparse auto encoders in phone classification, CoRR. URL [31] V. P eddinti, G. Chen, D. Po vey , S. Khudanpur, Reverberation robust acoustic modeling using i-v ectors with time delay neural net works., in: Pro c. of Interspeech, 2015, pp. 2440–2444. [32] M. Rav anelli, M. Omologo, Contaminated sp eec h training metho ds for ro- bust DNN-HMM distan t sp eec h recognition, in: Pro c. of In tersp eec h, 2015, pp. 756–760. [33] H. Kuttruff, Ro om acoustic, 5th Edition, Spon Press, 2009. [34] J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, D. S. Pallett, N. L. Dahlgren, DARP A TIMIT Acoustic Phonetic Contin uous Sp eech Corpus CDR OM (1993). [35] K. P earson, Mathematical Contributions to the Theory of Ev olution. I I I. Regression, Heredity , and Panmixia, Pro ceedings of the Roy al So ciet y of London, Philosophical T ransactions of the Roy al So ciet y 187 (1886) 253– 318. [36] J. Benest y , J. Chen, Y. Huang, On the Imp ortance of the Pearson Correla- tion Co efficient in Noise Reduction, IEEE T ransactions on Audio, Sp eec h, and Language Pro cessing 16 (4) (2008) 757–765. [37] V. Pana yoto v, G. Chen, D. P ov ey , S. Khudanpur, Librispeech: An asr corpus based on public domain audio b o oks, in: Proc. of ICASSP , 2015, pp. 5206–5210. [38] M. Ra v anelli, P . Sv aize r, M. Omologo, Realistic multi-microphone data sim ulation for distan t sp eech recognition, in: Pro c. of In tersp eec h, 2016, pp. 2786–2790. 30 [39] M. Ra v anelli, A. Sosi, P . Sv aizer, M. Omologo, Impulse resp onse estimation for robust sp eec h recognition in a reverberant environmen t, in: Pro c. of EUSIPCO, 2012, pp. 1668–1672. [40] J. Allen, D. Berkley , Image metho d for efficiently sim ulating smallro om acoustics, in: J. Acoust. So c. Am, 1979, pp. 2425–2428. [41] D. Po vey , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Go el, M. Hannemann, P . Motlicek, Y. Qian, P . Sc hw arz, J. Silo vsky , G. Stemmer, K. V esely , The Kaldi Sp eec h Recognition T o olkit, in: Pro c. of ASR U, 2011. [42] X. Glorot, Y. Bengio, Understanding the difficulty of training deep feed- forw ard neural netw orks, in: Proc. of AIST A TS, 2010, pp. 249–256. [43] X. Zhang, J. T rmal, D. P ov ey , S. Khudanpur, Improving deep neural net- w ork acoustic mo dels using generalized maxout net w orks, in: Pro c. of ICASSP , 2014, pp. 215–219. 31
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment