Phocas: dimensional Byzantine-resilient stochastic gradient descent
We propose a novel robust aggregation rule for distributed synchronous Stochastic Gradient Descent~(SGD) under a general Byzantine failure model. The attackers can arbitrarily manipulate the data transferred between the servers and the workers in the parameter server~(PS) architecture. We prove the Byzantine resilience of the proposed aggregation rules. Empirical analysis shows that the proposed techniques outperform current approaches for realistic use cases and Byzantine attack scenarios.
💡 Research Summary
The paper addresses the problem of Byzantine‑resilient distributed training in the parameter‑server (PS) architecture, focusing on synchronous stochastic gradient descent (SGD). Existing Byzantine‑resilient aggregation methods (simple averaging, Krum, Multi‑Krum) assume a classic failure model where all corrupted values belong to a limited set of workers. In practice, however, communication errors, hardware faults, or sophisticated attacks can corrupt individual gradient components independently, leading to a more general “dimensional” Byzantine model: for each coordinate (dimension) of the gradient matrix, up to q out of m values may be arbitrarily altered, with no restriction on which workers supply the corrupted entries.
The authors formalize this model (Definition 4) and introduce the notion of dimensional Δ‑Byzantine resilience (Definition 5), which requires that the expected squared error between the aggregated gradient and the true gradient be bounded by a constant Δ that depends only on m and q. They prove that the classic aggregation rules fail this property: averaging can be driven arbitrarily far from the true gradient, and Krum/Multi‑Krum, which rely on Euclidean distances, also become unbounded when Byzantine values are scattered across dimensions (Propositions 1‑3).
To overcome these limitations, the paper proposes two coordinate‑wise trimmed‑mean based aggregators:
-
Trimmed‑Mean (Trmean) – For each dimension, discard the b smallest and b largest values and average the remaining m − 2b entries. Theorem 1 shows that if 2q < m, Trmean is dimensional Δ‑Byzantine resilient with variance bound
Δ₁ = 2(b + 1)(m − q) / (m − b − q)² · V,
where V is the variance of the honest gradients. -
Phocas – Compute the trimmed‑mean as a reference point, then select the m − b values closest to this reference (in absolute distance) and average them. This “trimmed‑average centered at the trimmed mean” retains more information than Trmean while still discarding outliers. Theorem 2 proves that Phocas also satisfies dimensional Δ‑Byzantine resilience under the same 2q < m condition, with a slightly larger bound Δ₂ that adds a constant term to Δ₁.
Both methods have linear time complexity O(dm) (or O(dm log m) when sorting is used), substantially better than the O(dm²) cost of Krum‑type algorithms.
The convergence analysis covers two settings:
- Strongly convex & L‑smooth losses – Using any Δ‑resilient aggregator, synchronous SGD converges linearly to a neighborhood of the optimum, with the final error scaling as √Δ (Theorem 3).
- Non‑convex smooth losses – The average squared gradient norm after T iterations is bounded by O(Δ) plus the usual smoothness term (Theorem 4).
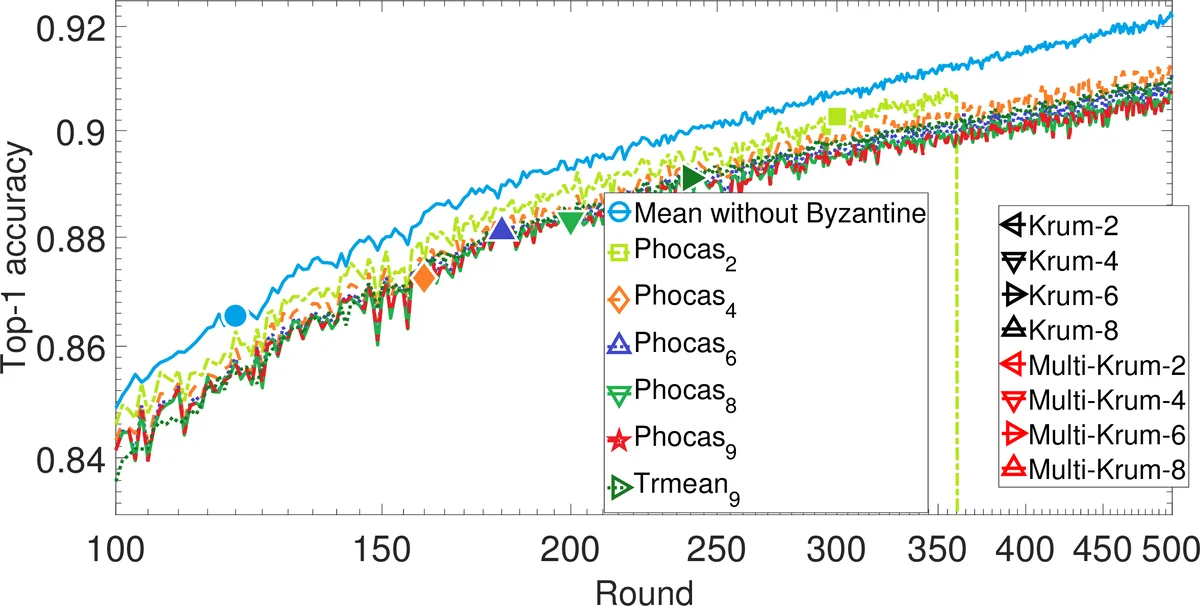
Empirical evaluation uses 20 workers training an MLP on MNIST and a CNN on CIFAR‑10. Four attack scenarios are examined:
- Gaussian attack – Replace 6 workers’ gradients with high‑variance Gaussian noise.
- Omniscient attack – Replace 6 workers’ gradients with the negative sum of all honest gradients scaled by 1e20.
- Bit‑flip attack – Flip specific bits in the first 1000 dimensions of each gradient.
- Gambler attack – Randomly multiply an entire worker’s gradient by –1e20 with a tiny probability.
Across all attacks, Trmean and Phocas maintain high top‑1 (or top‑3) accuracy, significantly outperforming Mean, Krum, and Multi‑Krum, especially as the Byzantine fraction q increases toward 30 %. Sensitivity studies show that smaller trimming parameter b and lower q improve performance, confirming the theoretical bounds.
In summary, the paper introduces a realistic, dimension‑wise Byzantine failure model and provides two efficient, provably robust aggregation rules—Trimmed‑Mean and Phocas—that achieve both theoretical resilience and practical superiority in large‑scale distributed deep learning. This work advances the state of Byzantine‑resilient optimization by eliminating the curse of dimensionality and offering near‑linear computational overhead, making it highly relevant for real‑world federated and distributed AI systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment