On the importance of single directions for generalization
Despite their ability to memorize large datasets, deep neural networks often achieve good generalization performance. However, the differences between the learned solutions of networks which generalize and those which do not remain unclear. Additionally, the tuning properties of single directions (defined as the activation of a single unit or some linear combination of units in response to some input) have been highlighted, but their importance has not been evaluated. Here, we connect these lines of inquiry to demonstrate that a network’s reliance on single directions is a good predictor of its generalization performance, across networks trained on datasets with different fractions of corrupted labels, across ensembles of networks trained on datasets with unmodified labels, across different hyperparameters, and over the course of training. While dropout only regularizes this quantity up to a point, batch normalization implicitly discourages single direction reliance, in part by decreasing the class selectivity of individual units. Finally, we find that class selectivity is a poor predictor of task importance, suggesting not only that networks which generalize well minimize their dependence on individual units by reducing their selectivity, but also that individually selective units may not be necessary for strong network performance.
💡 Research Summary
The paper investigates how much modern deep neural networks rely on “single directions” – defined as the activation of a single unit, a feature map, or any linear combination of units – and demonstrates that this reliance is a strong predictor of generalization performance. The authors introduce two complementary perturbation methods to quantify single‑direction dependence: (1) cumulative ablation, where the activation of a chosen direction is clamped to a fixed value (typically zero) and the drop in accuracy is measured as more directions are removed; and (2) random‑direction noise injection, where zero‑mean Gaussian noise scaled by each unit’s empirical variance is added progressively. Both methods operate directly in activation space, avoiding weight‑space manipulations.
Experiments span three canonical architectures: a 2‑layer MLP on MNIST, an 11‑layer convolutional network on CIFAR‑10, and a 50‑layer ResNet on ImageNet. To create a spectrum of memorization versus structure‑learning, the authors corrupt training labels at varying fractions (0 % to 100 %). Networks forced to memorize (high label corruption) exhibit dramatically steeper accuracy declines under both ablation and noise, indicating a heavy reliance on low‑dimensional subspaces. Conversely, networks trained on clean data retain performance longer as directions are removed, suggesting a more distributed representation.
A crucial question is whether this phenomenon persists among models trained on identical, uncorrupted data but differing in random seed, learning rate, or data ordering. The authors train 200 CIFAR‑10 ConvNets with identical architecture and data, varying only initialization and hyper‑parameters. They find that the five best‑generalizing models are markedly more robust to cumulative ablations than the five worst‑generalizing ones. The area under the ablation curve (AUC) correlates negatively with test error, revealing a discrete regime shift in single‑direction reliance that mirrors generalization quality.
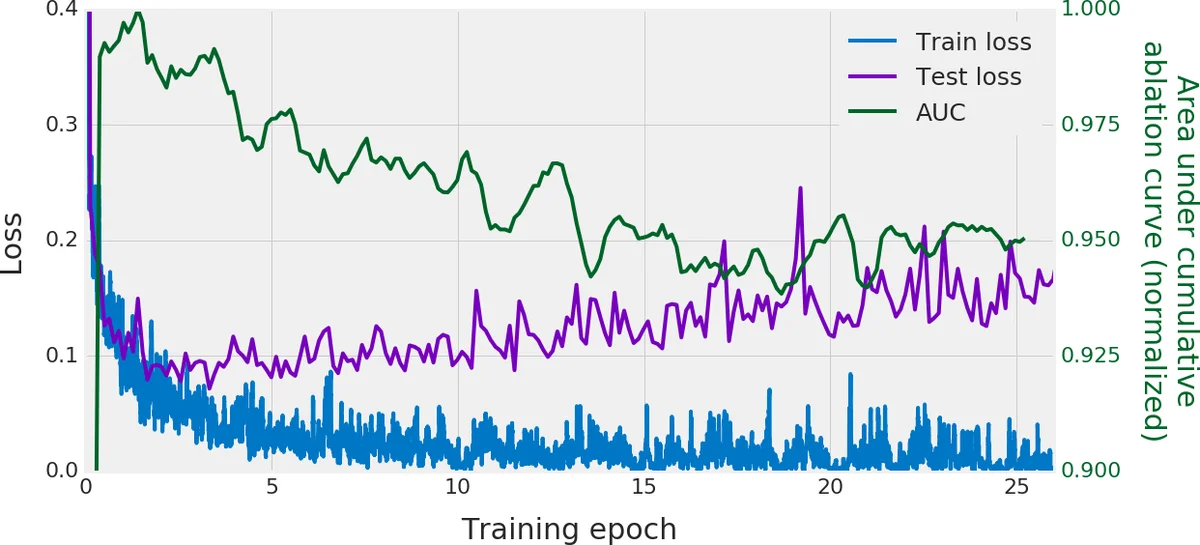
The paper further explores practical uses of this metric. During training of an MNIST MLP, the AUC begins to drop precisely when training loss diverges from validation loss, providing a potential early‑stopping signal. In a large hyper‑parameter sweep (96 settings, each repeated twice) on CIFAR‑10, AUC correlates strongly (Spearman ρ = 0.914) with final test accuracy. Selecting models based on highest AUC recovers top‑performing hyper‑parameter configurations with high probability (13 % for the single best, 83 % for top‑5, 98 % for top‑10) and incurs only ~1 % average accuracy loss relative to the true optimum.
Regularization effects are examined next. Dropout, which randomly silences units during training, protects networks only up to the dropout rate: models remain robust to ablations up to the fraction of units dropped, but beyond that they become as sensitive as non‑dropout networks, especially when trained on corrupted labels. This suggests dropout merely forces a minimal amount of redundancy rather than eliminating single‑direction dependence altogether. Batch normalization, by contrast, implicitly discourages reliance on single directions. Networks with batch norm exhibit flatter ablation curves and reduced class selectivity – a metric measuring how strongly a unit’s activation is tied to a single class. Importantly, the authors show that high class selectivity does not predict a unit’s importance: ablating highly selective units often causes little performance loss, indicating that selective units are not essential for strong overall performance.
In sum, the study provides a clear methodological framework for measuring single‑direction dependence, establishes its tight link to generalization across datasets, architectures, and training regimes, and demonstrates that batch normalization naturally mitigates this dependence while dropout offers only limited protection. The AUC of cumulative ablation curves emerges as a practical, test‑free proxy for model quality, useful for early stopping and hyper‑parameter selection. These insights deepen our understanding of why deep networks generalize despite massive capacity and suggest new avenues for designing regularizers that explicitly promote distributed, low‑single‑direction reliance.
Comments & Academic Discussion
Loading comments...
Leave a Comment