Loom: Exploiting Weight and Activation Precisions to Accelerate Convolutional Neural Networks
Loom (LM), a hardware inference accelerator for Convolutional Neural Networks (CNNs) is presented. In LM every bit of data precision that can be saved translates to proportional performance gains. Specifically, for convolutional layers LM’s execution time scales inversely proportionally with the precisions of both weights and activations. For fully-connected layers LM’s performance scales inversely proportionally with the precision of the weights. LM targets area- and bandwidth-constrained System-on-a-Chip designs such as those found on mobile devices that cannot afford the multi-megabyte buffers that would be needed to store each layer on-chip. Accordingly, given a data bandwidth budget, LM boosts energy efficiency and performance over an equivalent bit-parallel accelerator. For both weights and activations LM can exploit profile-derived perlayer precisions. However, at runtime LM further trims activation precisions at a much smaller than a layer granularity. Moreover, it can naturally exploit weight precision variability at a smaller granularity than a layer. On average, across several image classification CNNs and for a configuration that can perform the equivalent of 128 16b x 16b multiply-accumulate operations per cycle LM outperforms a state-of-the-art bit-parallel accelerator [1] by 4.38x without any loss in accuracy while being 3.54x more energy efficient. LM can trade-off accuracy for additional improvements in execution performance and energy efficiency and compares favorably to an accelerator that targeted only activation precisions. We also study 2- and 4-bit LM variants and find the the 2-bit per cycle variant is the most energy efficient.
💡 Research Summary
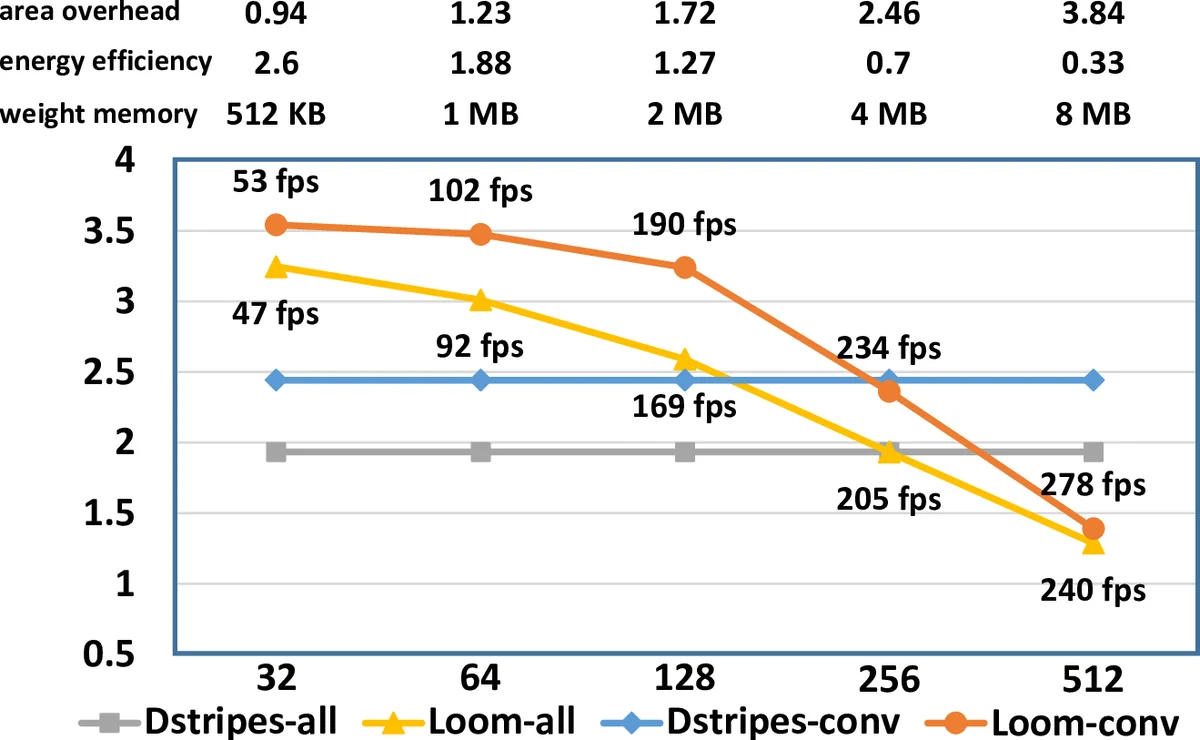
Loom (LM) is a hardware inference accelerator designed for convolutional neural networks (CNNs) that targets area‑ and bandwidth‑constrained system‑on‑chip (SoC) environments typical of mobile devices. The key innovation is to process both weights and activations bit‑serially, thereby allowing the accelerator to consume only as many bits as are actually required for each layer. For convolutional layers, LM’s execution time scales inversely with the product of weight precision (P_w) and activation precision (P_a); for fully‑connected layers it scales inversely with weight precision alone. By matching the peak compute bandwidth of a conventional 128 × 16‑bit multiply‑accumulate (MAC) engine, LM can achieve up to 256/(P_a·P_w) speed‑up for convolutions and 16/P_w speed‑up for fully‑connected layers when precisions are below 16 bits.
The architecture consists of a 2 K × 16 grid of Serial Inner‑Product (SIP) units. Each SIP holds 16 one‑bit weight registers and receives 16 one‑bit activation inputs each cycle, performing 16 parallel 1‑bit AND operations followed by a 16‑input adder tree to produce a partial output. SIPs in the same row share a 16‑bit weight bus, while those in the same column share a 256‑bit activation bus, ensuring that total input bandwidth equals that of the baseline bit‑parallel design. Because weights and activations are streamed bit‑by‑bit, they can be stored in a bit‑interleaved fashion, reducing memory footprint by up to a factor of 16 compared with a fixed‑16‑bit representation.
Precision profiling is performed offline per layer to determine the minimum number of bits required for each weight and activation tensor without sacrificing accuracy. At runtime, LM further trims activation precision at a granularity finer than a layer using the dynamic trimming technique of Lascorz et al., while weight precision can vary even within a filter. This fine‑grained adaptability yields both bandwidth savings and energy reductions.
Evaluation on seven image‑classification networks (including AlexNet, NiN, GoogLeNet, VGG‑19) shows that, for a configuration matching the 128 × 16‑bit MAC bandwidth, LM delivers on average 3.25× speed‑up on convolutional layers, 1.74× on fully‑connected layers, and 3.19× overall, with corresponding energy‑efficiency improvements of 2.63×, 1.41×, and 2.59×. Importantly, these gains are achieved with no loss in top‑1 accuracy; the average speed‑up over a state‑of‑the‑art bit‑parallel accelerator (DPNN) is 4.38× while being 3.54× more energy‑efficient. Allowing a modest 1 % relative accuracy loss can push performance to 3.57× and energy efficiency to 2.87× beyond DPNN. A study of 2‑bit and 4‑bit variants reveals that a 2‑bit‑per‑cycle design offers the best energy efficiency, albeit with lower raw performance.
In summary, Loom demonstrates that bit‑serial processing combined with dynamic precision scaling can dramatically reduce memory traffic and compute cycles, delivering substantial performance and energy benefits for CNN inference on resource‑constrained platforms without compromising model accuracy.
Comments & Academic Discussion
Loading comments...
Leave a Comment