A Cross-Layer Solution in Scientific Workflow System for Tackling Data Movement Challenge
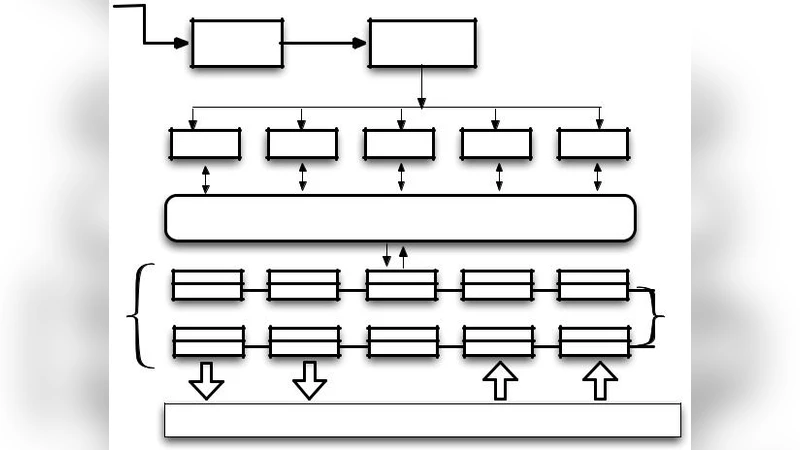
Scientific applications in HPC environment are more com-plex and more data-intensive nowadays. Scientists usually rely on workflow system to manage the complexity: simply define multiple processing steps into a single script and let the work-flow systems compile it and schedule all tasks accordingly. Numerous workflow systems have been proposed and widely used, like Galaxy, Pegasus, Taverna, Kepler, Swift, AWE, etc., to name a few examples. Traditionally, scientific workflow systems work with parallel file systems, like Lustre, PVFS, Ceph, or other forms of remote shared storage systems. As such, the data (including the intermediate data generated during workflow execution) need to be transferred back and forth between compute nodes and storage systems, which introduces a significant performance bottleneck on I/O operations. Along with the enlarging perfor-mance gap between CPU and storage devices, this bottleneck is expected to be worse. Recently, we have introduced a new concept of Compute-on-Data-Path to allow tasks and data binding to be more efficient to reduce the data movement cost. To workflow systems, the key is to exploit the data locality in HPC storage hierarchy: if the datasets are stored in compute nodes, near the workflow tasks, then the task can directly access them with better performance with less network usage. Several recent studies have been done regarding building such a shared storage system, utilizing compute node resources, to serve HPC workflows with locality, such as Hercules [1] and WOSS [2] etc. In this research, we further argue that providing a compute-node side storage system is not sufficient to fully exploit data locality. A cross-layer solution combining storage system, compiler, and runtime is necessary. We take Swift/T [3], a workflow system for data-intensive applications, as a prototype platform to demonstrate such a cross-layer solution
💡 Research Summary
**
The paper addresses a critical performance bottleneck in high‑performance computing (HPC) scientific workflows: excessive data movement between compute nodes and remote parallel file systems (e.g., Lustre, PVFS, Ceph). As modern scientific applications become increasingly data‑intensive, the gap between CPU speed and storage/network bandwidth widens, causing I/O latency to dominate overall execution time.
To mitigate this, the authors propose a cross‑layer solution that simultaneously modifies three components of a workflow system— the storage layer, the compiler, and the runtime scheduler—using Swift/T as a prototype platform.
1. Storage Layer Extension (Location‑Aware File System)
The underlying storage, Hercules (a distributed in‑memory store built on Memcached), is extended with location‑aware APIs. A new flag S_LOC can be passed to the POSIX open call to request creation of a file on a specific compute node. If omitted, the system falls back to its default placement algorithm. File location metadata is stored as extended attributes (xattr) and can be queried via standard POSIX calls. A distributed location service maintains a global map of files to nodes, enabling both users and the runtime to explicitly control where data resides.
2. Compiler Hints (Hint‑Assist Workflow Compiler)
Swift/T’s language model is enriched with four new annotations:
@size– declares the size of an existing file.@task– provides task‑level parameters such as required process count.@compute‑complexity– expresses the computational cost as a function of input size (e.g., linear).@input‑output‑ratio– estimates output size relative to inputs.
During compilation, these hints are attached to the generated task DAG, producing a “rich” metadata set that describes both data and computation. This enables static analysis to estimate earliest start times, predict intermediate data volumes, and guide later scheduling decisions.
3. Locality‑Aware Runtime Scheduler
The traditional first‑come‑first‑served (FCFS) scheduler is replaced by a heuristic that computes a priority score for each ready task. The score combines:
- Length of the longest path from the current task to any final task (longer paths receive higher priority).
- Current availability of workers.
- Estimated data movement cost for executing the task on a particular node.
In addition, a proactive scheduling component pre‑assigns tasks whose inputs are not yet fully available. By informing the storage layer of the intended execution node, the file system can begin pipelining required data ahead of time. Consequently, when the task finally becomes runnable, its inputs are already resident on the target node, dramatically reducing I/O wait time.
Architecture Overview
The system flow is: Swift/T source → Swift compiler → intermediate Turbine code → multiple script engines → load balancer (enhanced scheduler) → workers on compute nodes → Hercules (compute‑node‑resident storage) plus optional remote parallel file systems. The new APIs and annotations bridge the compiler and runtime with the storage layer, allowing bidirectional feedback: the scheduler can request data placement, and the storage can inform the scheduler about data locality.
Expected Benefits and Limitations
By explicitly controlling data placement and providing detailed task metadata, the proposed framework can:
- Reduce network traffic and I/O latency through data locality.
- Make more informed scheduling decisions that balance computation and communication costs.
- Overlap data transfer with computation via proactive scheduling, effectively pipelining data movement.
The paper acknowledges that experimental validation is limited to a prototype; large‑scale evaluations, automatic hint generation, and integration with emerging storage technologies (e.g., NVMe‑over‑Fabric) remain future work.
Conclusion
Data movement is a dominant factor limiting the scalability of scientific workflows on HPC systems. A single‑layer optimization (either storage‑only or scheduler‑only) cannot fully exploit locality. The authors demonstrate that a coordinated, cross‑layer approach—extending the file system with location awareness, enriching the compiler with expressive hints, and employing a locality‑aware, proactive scheduler—can substantially alleviate I/O bottlenecks and improve overall workflow performance. This work paves the way for more holistic optimizations in next‑generation HPC workflow environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment