Investigating the Agility Bias in DNS Graph Mining
The concept of agile domain name system (DNS) refers to dynamic and rapidly changing mappings between domain names and their Internet protocol (IP) addresses. This empirical paper evaluates the bias from this kind of agility for DNS-based graph theoretical data mining applications. By building on two conventional metrics for observing malicious DNS agility, the agility bias is observed by comparing bipartite DNS graphs to different subgraphs from which vertices and edges are removed according to two criteria. According to an empirical experiment with two longitudinal DNS datasets, irrespective of the criterion, the agility bias is observed to be severe particularly regarding the effect of outlying domains hosted and delivered via content delivery networks and cloud computing services. With these observations, the paper contributes to the research domains of cyber security and DNS mining. In a larger context of applied graph mining, the paper further elaborates the practical concerns related to the learning of large and dynamic bipartite graphs.
💡 Research Summary
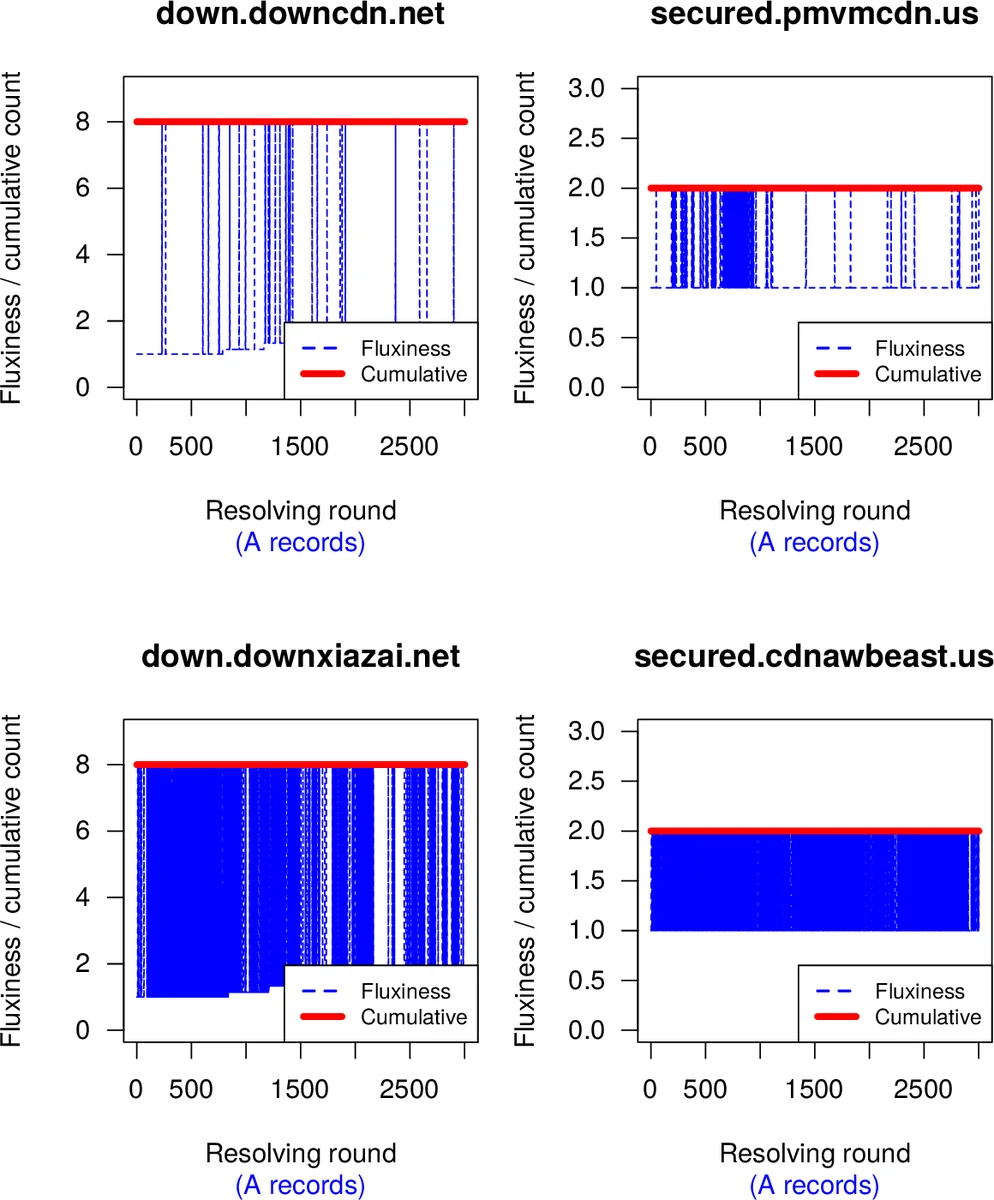
The paper investigates how the rapid and frequent changes in domain‑to‑IP mappings—referred to as “agile DNS”—affect the construction and analysis of bipartite DNS graphs used in security‑oriented data mining. Two well‑known fast‑flux metrics are adopted: (i) fluxiness, defined as the ratio of the total number of unique IP addresses observed over a learning period to the number returned in a single DNS query, and (ii) cumulative address count, which records the growth of unique IPs across successive query rounds. The authors formulate two sources of bias. The first, “learning bias,” asks how many DNS resolution rounds (q) are required before the graph stabilizes; insufficient rounds lead to many false‑negative vertices and edges. The second, “sampling bias,” examines the impact of extremely agile domains—especially those served by content‑delivery networks (CDNs) and cloud platforms—on the statistical properties of already learned graphs.
To answer these questions, the authors conduct an empirical study on two longitudinal DNS datasets. Each dataset contains thousands of fully qualified domain names (FQDNs) queried up to 3 000 times from a local resolver, capturing both IPv4 (A) and IPv6 (AAAA) records. For each round a bipartite graph is built linking domains to the IPs returned, and standard network metrics (vertex/edge counts, degree distribution, clustering coefficient, component size) are recorded.
The results reveal a stark contrast between ordinary domains and those backed by CDNs or cloud services. Ordinary domains typically expose most of their IP addresses within the first 10–20 rounds; after that the graph changes little, indicating that a modest number of queries suffices for a representative static graph. In contrast, CDN‑related domains continue to acquire new IPs throughout the entire 3 000‑round period, showing high fluxiness values that never converge to 1. Approximately 30 % of all vertices belong to this “high‑agility” group. When these vertices are removed, the graph’s average path length increases by about 15 % and the number of connected components more than doubles, demonstrating severe sampling bias. Moreover, even with 3 000 rounds, some CDN‑driven address pools are not fully captured, implying that static graphs—even with many queries—remain incomplete and prone to false negatives.
Based on these observations, the authors argue that DNS graph mining must move beyond static snapshots toward dynamic, time‑aware models. They recommend incorporating fluxiness and cumulative count as preprocessing filters: highly agile vertices can be assigned special weights, modeled as separate “IP‑pool” clusters, or excluded from certain analyses to reduce bias. Additionally, streaming or incremental graph construction techniques are suggested to keep pace with the continual address churn observed in modern CDN and cloud environments.
The paper contributes to both cybersecurity and graph‑mining literature by quantifying the agility bias, highlighting the disproportionate influence of CDN‑driven domains on graph topology, and proposing practical mitigation strategies. It underscores that any security analytics relying on DNS graphs—such as botnet detection, malicious domain identification, or threat‑intelligence enrichment—must account for the dynamic nature of DNS to avoid misleading conclusions and maintain detection efficacy.
Comments & Academic Discussion
Loading comments...
Leave a Comment