Neural Coreference Resolution with Deep Biaffine Attention by Joint Mention Detection and Mention Clustering
Coreference resolution aims to identify in a text all mentions that refer to the same real-world entity. The state-of-the-art end-to-end neural coreference model considers all text spans in a document as potential mentions and learns to link an antecedent for each possible mention. In this paper, we propose to improve the end-to-end coreference resolution system by (1) using a biaffine attention model to get antecedent scores for each possible mention, and (2) jointly optimizing the mention detection accuracy and the mention clustering log-likelihood given the mention cluster labels. Our model achieves the state-of-the-art performance on the CoNLL-2012 Shared Task English test set.
💡 Research Summary
The paper tackles the classic NLP task of coreference resolution, which requires identifying all textual mentions that refer to the same real‑world entity and grouping them into clusters. Traditional pipelines separate the problem into (1) a mention detector that proposes candidate mentions and (2) a coreference resolver that clusters those mentions. Such pipelines rely heavily on hand‑crafted features, syntactic parsers, and suffer from error propagation and poor cross‑domain generalization.
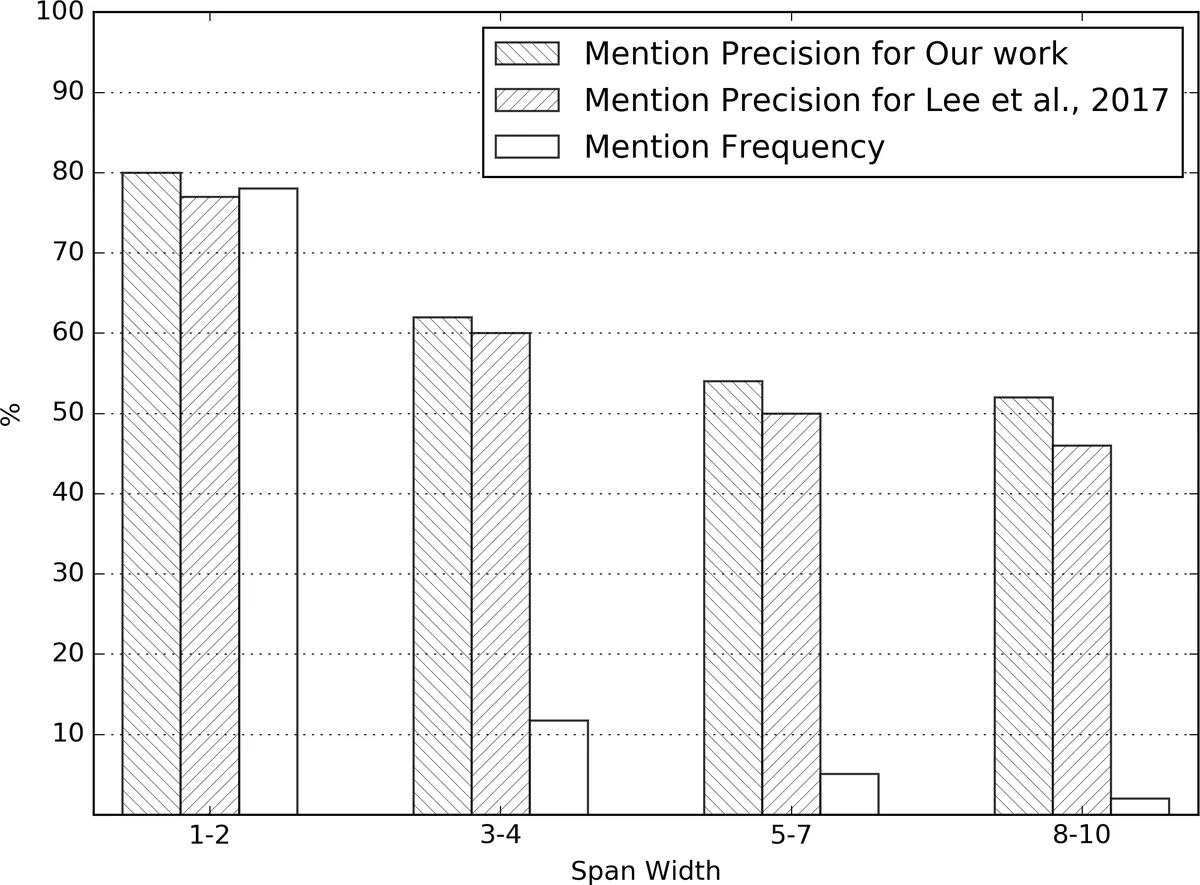
Lee et al. (2017) introduced the first end‑to‑end neural coreference system that treats every possible text span (up to a fixed length) as a potential mention, thereby eliminating the need for an external mention detector. Their model uses bidirectional LSTMs with a head‑finding attention to obtain span representations, a feed‑forward network (FFNN) to score each span as a mention, and another FFNN to compute antecedent scores for each pair of spans. Training maximizes the marginal likelihood of gold antecedent links; mention detection is only indirectly supervised.
The current work proposes two complementary improvements to this architecture.
- Biaffine Attention for Antecedent Scoring
Instead of a simple FFNN that concatenates the current span and a candidate antecedent, the authors adopt the deep biaffine attention mechanism (Dozat & Manning, 2017). Each span representation is first projected through two separate FFNNs (one for “anaphora” and one for “antecedent”) to obtain low‑dimensional vectors (\hat{s}_i) and (\hat{s}_j). The antecedent score is then computed as
\
Comments & Academic Discussion
Loading comments...
Leave a Comment