Phase Transitions and a Model Order Selection Criterion for Spectral Graph Clustering
One of the longstanding open problems in spectral graph clustering (SGC) is the so-called model order selection problem: automated selection of the correct number of clusters. This is equivalent to the problem of finding the number of connected compo…
Authors: Pin-Yu Chen, Alfred O. Hero
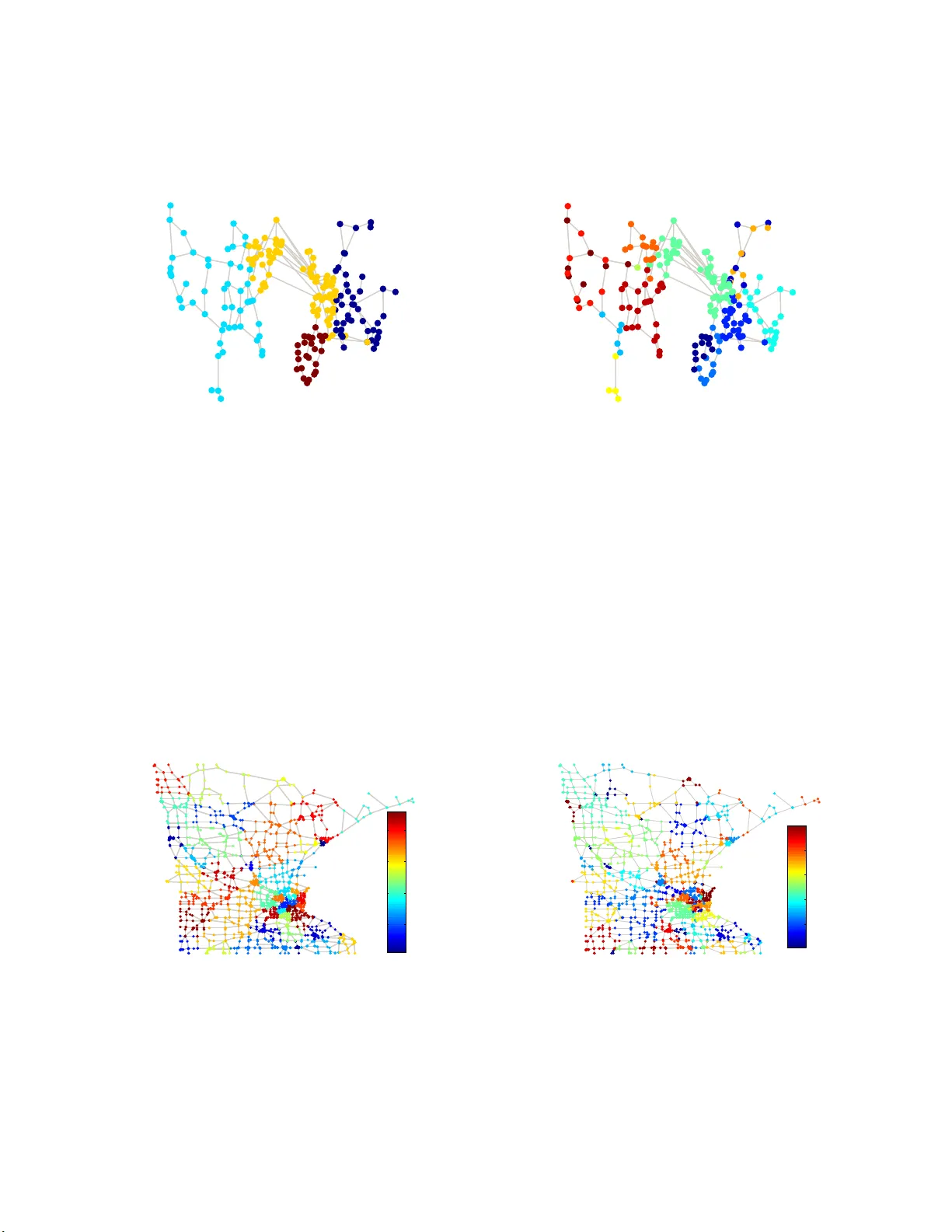
0 , where I is the identity matrix of infinite d imension and d iag ( 1 n i ) = I n i → I a s n i → ∞ . T he con vergence resu lt in (15) can b e p roved u sing the fact that each entry of the vector C ij 1 n j is the sum of i.i.d. Bern oulli rand om variables an d k D ij n j − p ij I n i k 2 = max z ∈{ 1 , 2 ,...,n i } | [ D ij n j − p ij I n i ] z z | . Specifically , by Bernstein’ s concentr a tion ine quality [64], | [ D ij n j − p ij I n i ] z z | h as an ex- ponen tially decaying tail and hen ce by th e u nion bound , k D ij n j − p ij I n i k 2 a.s. − → 0 as n i , n j → ∞ . Using ( 15) and left multiplying (14) by 1 T n k n giv es 1 n K X j =1 ,j 6 = k n j p kj 1 T n k Y k − K X j =1 ,j 6 = k n k p kj 1 T n j Y j − 1 T n k Y k U a.s. − → 0 T K − 1 , ∀ k. (16) Using th e relation 1 T n K Y K = − P K − 1 j =1 1 T n j Y j , (16) can be represented as an asymptotic form of Sylvester’ s equatio n 1 n e AZ − ZΛ a.s. − → O , (17) where Z = [ Y T 1 1 n 1 , Y T 2 1 n 2 , . . . , Y T K − 1 1 n K − 1 ] T ∈ R ( K − 1) × ( K − 1) , e A is the ma trix specified in Theor e m 1, and we use the relation U = Λ = diag ( λ 2 ( L ) , λ 3 ( L ) , . . . , λ K ( L )) from (11). Let ⊗ denote the Kronecker pr oduct and let vec ( Z ) den ote the vectorization operation o f Z by stacking the columns of Z into a vector . (17) can be rep r esented as 1 n ( I K − 1 ⊗ e A − Λ ⊗ I K − 1 ) vec ( Z ) a.s. − → 0 , (18) where the matrix I K − 1 ⊗ e A − Λ ⊗ I K − 1 is the Kronecker sum, denoted by e A ⊕ − Λ . Observe that vec ( Z ) a.s. − → 0 is always a trivial solution to ( 18), an d if e A ⊕ − Λ is non- singular (i.e., its determinan t is nonzero), vec ( Z ) a.s. − → 0 is th e unique solution to (18). Sinc e vec ( Z ) a.s. − → 0 and P K k =1 1 T n k Y k = 0 T K − 1 imply 1 T n k Y k a.s. − → 0 T K − 1 for all k = 1 , 2 , . . . , K , the centroid 1 T n k Y k n k of each cluster in the eig e nspace is asymp to tically cen tered at the o rigin such that the clu sters are n ot pe r fectly separable, and hence accurate clustering is impo ssible. Therefore , a sufficient condition fo r SGC u nder the RIM to fail is that th e matrix I K − 1 ⊗ e A − Λ ⊗ I K − 1 be non-singu lar . Moreover, using the proper ty of the Kro necker sum that the eigenv a lu es of e A ⊕ − Λ satisfy { λ ℓ ( e A ⊕ − Λ ) } ( K − 1) 2 ℓ =1 = { λ i ( e A ) − λ j ( Λ ) } K − 1 i,j =1 , the sufficient con d ition on the failure of SGC under th e RIM is lim inf n →∞ 1 n min i,j | λ i ( e A ) − λ j ( L ) | > 0 for all i = 1 , 2 , . . . , K − 1 and j = 2 , 3 , . . . , K . B. Pr oo f of Theor em 2 Follo win g the deriv ation s in Appen d ix-A, since 1 T n k Y k = − P K j =1 ,j 6 = k 1 T n j Y j , und er the homogen eous RIM (i.e., p ij = p ), equation (16) can be simplified to p I K − 1 − U n Y T k 1 n k a.s. − → 0 K − 1 , ∀ k. (19) Below we fur ther di vid e the optimality c ondition in (19) into two cases b ased on wh ether Y T k 1 n k a.s. − → 0 n k for all k or not: Case 1: p I K − 1 − U n Y T k 1 n k a.s. − → 0 K − 1 , ∀ k and ∃ k s.t. lim n →∞ k Y T k 1 n k k 2 > 0; (20) Case 2: Y T k 1 n k a.s. − → 0 K − 1 , ∀ k. (21) Note that Case 1 immediately im plies U n a.s. − → p I K − 1 , which is proved a s follows. In Case 1, take a k such that p I K − 1 − U n Y T k 1 n k a.s. − → 0 K − 1 and lim n →∞ k Y T k 1 n k k 2 > 0 . Left multiplying p I K − 1 − U n Y T k 1 n k by ( Y T k 1 n k ) T giv es p k Y T k 1 n k k 2 2 − 1 n ( Y T k 1 n k ) T UY T k 1 n k a.s. − → 0 . Since lim n →∞ k Y T k 1 n k k 2 > 0 and lim n →∞ 1 n ( Y T k 1 n k ) T UY T k 1 n k ≥ 0 u sing (1 1), we obtain λ j +1 ( L ) n a.s. − → p if lim n →∞ | [ Y T k 1 n k ] j | > 0 for j ∈ { 1 , 2 , . . . , K − 1 } . M oreover , to sh ow U n a.s. − → p I K − 1 , it suffices to show λ 2 ( L ) n a.s. − → p and λ K ( L ) n a.s. − → p since fr om (11) U is a diagona l matrix and its main d iagonal are the second to the K - th smallest eigenv alue of L . Using the fact that P K k =1 Y T k 1 n k = 0 K − 1 , un der Case 1 there m ust exist at least two asymptotically non zero vectors in { Y T k 1 n k } K k =1 . Furthermo re, the fact that P K k =1 Y T k Y k = I K − 1 ensures that for each c olumn j ∈ { 1 , 2 , . . . , K − 1 } of Y , there must exist some k such that th e j -th colu mn of Y k has some nonzer o entries and hence lim n →∞ | [ Y T k 1 n k ] j | > 0 , which then implies U n a.s. − → p I K − 1 . As a result, we also obtain S 2: K ( L ) n = trace ( U ) n a.s. − → ( K − 1) p. (2 2 ) In Case 1, left mu ltiplying (1 4) b y Y T k n , using the fact [2] k C ij − C ij k 2 √ n i n j a.s. − → 0 as n i , n j → ∞ an d n min n max → c > 0 , where C ij = p 1 n i 1 T n j when p ij = p , and using (15) gives 1 n Y T k L k Y k + K X j =1 ,j 6 = k n j p Y T k Y k − K X j =1 ,j 6 = k p Y T k 1 n k 1 T n j Y j − Y T k Y k U a.s. − → O , ∀ k . (23) Since 1 T n k Y k = − P K j =1 ,j 6 = k 1 T n j Y j , (23) can b e simplified as 1 n Y T k L k Y k + ( n − n k ) p Y T k Y k + p Y T k 1 n k 1 T n k Y k − Y T k Y k U a.s. − → O , ∀ k . (24) T aking the trace of (24) and using (20), we have 1 n trace ( Y T k L k Y k ) + p n trace ( Y T k 1 n k 1 T n k Y k ) − n k trace ( Y T k Y k ) a.s. − → 0 , ∀ k . (25) Rearrangin g (25), we obtain 1 n trace ( Y T k [ L k + p 1 n k 1 T n k − pn k I n k ] Y k ) a.s. − → 0 , ∀ k. (26) The optimality co ndition in (2 6) implies that every column of Y k is a constant vector , whic h is p roved a s follo w s. Let z be a column of Y k and deco mpose z as z = a n 1 n k + b n ¯ 1 n k , where a n , b n ∈ R and ¯ 1 n k 6 = 0 n k is a linear comb ination of all eigenvectors of Y k except 1 n k . Since L k 1 n k = 0 n k , 1 n z T [ L k + p 1 n k 1 T n k − pn k I n k ] z a.s. − → 0 implies 1 n b 2 n ¯ 1 T n k L k ¯ 1 n k + pa 2 n n 2 k − pa 2 n n 2 k − pb 2 n n k ¯ 1 T n k ¯ 1 n k = 1 n b 2 n ¯ 1 T n k ( L k − pn k I n k ) ¯ 1 n k a.s. − → 0 . (27) Using ¯ 1 T n k L k ¯ 1 n k = k ¯ 1 n k k 2 2 · ¯ 1 T n k k ¯ 1 n k k 2 L k ¯ 1 n k k ¯ 1 n k k 2 ≥ k ¯ 1 n k k 2 2 · min x ∈ R n k : x T x =1 , x T 1 n k =0 x T L k x = k ¯ 1 n k k 2 2 · λ 2 ( L k ) a n d the assumption th at c ∗ 2 = lim n →∞ 1 n min k ∈{ 1 , 2 ,.. .,K } λ 2 ( L k ) > 0 , we obtain lim n →∞ 1 n ¯ 1 T n k L k ¯ 1 n k > 0 . Fu rthermor e, since L k 6 = pn k I n k (the graph Laplacian matrix of a connected graph cannot be a diagonal matrix ) and ¯ 1 n k 6 = 0 n k , we o btain lim n →∞ 1 n | ¯ 1 T n k ( L k − pn k I n k ) ¯ 1 n k | > 0 . Theref ore, ( 27) implies lim n →∞ β n a.s. − → 0 , suggesting z is indeed a constant vector . The p roof is comp lete by exten ding the an alysis to 1 n trace ( Y T k [ L k + p 1 n k 1 T n k − pn k I n k ] Y k ) , a sum of K − 1 terms in the form of 1 n z T [ L k + p 1 n k 1 T n k − pn k I n k ] z . Moreover , th e condition in (26) implies that in Case 1, √ n k Y k a.s. − → 11 T K − 1 V k = v k 1 1 , v k 2 1 , . . . , v k K − 1 1 , (28) where V k = diag ( v k 1 , v k 2 , . . . , v k K − 1 ) is a diago nal matrix of constants. The scaling ter m √ n k is n e cessary because each column in the eigenv ec to r matrix Y has unit length. Let S = { X ∈ R n × ( K − 1) : X T X = I K − 1 , X T 1 n = 0 K − 1 } . In Case 2, since Y T k 1 n k a.s. − → 0 K − 1 ∀ k , we have S 2: K ( L ) n a.s. − → lim n k →∞ , c> 0 1 n · min X ∈S ( K X k =1 trace ( X T k L k X k ) + p K X k =1 ( n − n k ) trace ( X T k X k ) ) (29) ≥ lim n k →∞ , c> 0 1 n · min X ∈S ( K X k =1 trace ( X T k L k X k ) ) + lim n k →∞ , c> 0 1 n · min X ∈S ( p K X k =1 ( n − n k ) trace ( X T k X k ) ) (30) = lim n k →∞ , c> 0 1 n · min k ∈{ 1 , 2 ,.. .,K } S 2: K ( L k ) + ( K − 1) p min k ∈{ 1 , 2 ,.. .,K } (1 − ρ k ) (31) = c ∗ + ( K − 1)(1 − ρ max ) p, (32) where ρ max = max k ∈{ 1 , 2 ,.. . ,K } ρ k . Let S k = { X ∈ R n × ( K − 1) : X T k X k = I K − 1 , X j = O ∀ j 6 = k, X T 1 n = 0 K − 1 } . Since S k ⊆ S , in Case 2, we have S 2: K ( L ) n a.s. − → lim n k →∞ , c> 0 1 n · min X ∈S ( K X k =1 trace ( X T k L k X k ) + p K X k =1 ( n − n k ) trace ( X T k X k ) ) (33) ≤ min k ∈{ 1 , 2 ,.. . ,K } lim n k →∞ , c> 0 1 n · min X ∈S k ( K X k =1 trace ( X T k L k X k ) + p K X k =1 ( n − n k ) trace ( X T k X k ) ) (34) = lim n k →∞ , c> 0 1 n · min k ∈{ 1 , 2 ,.. .,K } { S 2: K ( L k ) + ( K − 1) p ( n − n k ) } (35) ≤ lim n k →∞ , c> 0 1 n · min k ∈{ 1 , 2 ,.. .,K } { S 2: K ( L k ) + ( K − 1) p ( n − n min ) } (36) = lim n k →∞ , c> 0 1 n · min k ∈{ 1 , 2 ,.. .,K } S 2: K ( L k ) + ( K − 1)(1 − ρ min ) p (37) = c ∗ + ( K − 1)(1 − ρ min ) p, (38) where ρ min = min k ∈{ 1 , 2 ,.. .,K } ρ k . Comparing (22) with (32) and (38), as a fun ction of p the slope of S 2: K ( L ) n changes at som e c r itical value p ∗ that separates Case 1 and Case 2 , and by the contin uity of S 2: K ( L ) n a lower b ound on p ∗ is p LB = lim n k →∞ , c> 0 min k ∈{ 1 , 2 ,.. . ,K } S 2: K ( L k ) ( K − 1) n max (39) = c ∗ ( K − 1) ρ max , (40) and an upper bound on p ∗ is p UB = lim n k →∞ , c> 0 min k ∈{ 1 , 2 ,.. .,K } S 2: K ( L k ) ( K − 1) n min (41) = c ∗ ( K − 1) ρ min . (42) C. Pr o o f of Theor em 3 Applying the Davis-Kahan sin θ th e o rem [46], [4 7] to the eigenv e c tor matrices Y an d e Y associated with the gr aph Laplacian matrices L n and e L n , respectively , we obtain an upper bound on the distance of column spaces s panned by Y and e Y , which is k sin Θ ( Y , e Y ) k F ≤ k L − e L k F nδ , where δ = inf { | x − y | : x ∈ { 0 } ∪ [ λ K +1 ( L ) n , ∞ ) , y ∈ [ λ 2 ( e L ) n , λ K ( e L ) n ] } . If p < p ∗ , using the fact fro m (20) th at λ j ( e L ) n a.s. − → p for all j ∈ { 2 , 3 , . . . , K } as n k → ∞ and n min n max → c > 0 , the interval [ λ 2 ( e L ) n , λ K ( e L ) n ] reduces to a point p almost su rely . Th e refore, δ reduces to δ p as defined in Th eorem 3. Furtherm ore, if p max ≤ p ∗ , then (4) ho ld s for all p ≤ p max . T aking th e minimum of all upp e r bound s in ( 4) for p ≤ p max completes the theorem. R E F E R E N C E S [1] S. White and P . Smyth, “ A spectral clu stering approach to finding communitie s in graph. ” in SIAM Interna tional Confer ence on Data Mining (SDM) , vol. 5, 2005, pp. 76–84. [2] P .-Y . Chen and A. O. Hero, “Pha se transition s in spectral community detec tion, ” IEEE T rans. Signal P r ocess. , vol. 63, no . 16, pp. 4 339–4347, Aug 2015. [3] A. Sandryha ila and J. Moura, “Di screte signal processing on gra phs, ” IEEE T rans. Signal Proc ess. , vol. 61 , no. 7, pp. 1644–1656, Apr . 2013. [4] A. Bertrand and M. Moonen, “Seei ng the bigger pict ure: How nodes can lea rn their place wi thin a comple x ad hoc network topolo gy , ” IEE E Signal Pro cess. Mag . , vol. 30, no. 3, pp. 71–82, 2013. [5] D. Shuman, S. Narang , P . Frossard, A. Ortega, and P . V anderghe ynst, “The emerging field of signal proc essing on graphs: E xtendin g high- dimensiona l data analy sis to networks and other irre gular domains, ” IEEE Signal Proc ess. Mag . , vol. 30, no. 3, pp. 83–98, 2013. [6] B. A. Miller , N. T . Bliss, P . J. W olfe, and M. S. Beard, “Dete ction th eory for graphs, ” Lincoln Laborat ory J ournal , vol. 20, no. 1, pp. 10–30, 2013. [7] X. Dong, P . Frossard, P . V anderghe ynst, and N. Nefe dov , “Clustering with multi-l ayer graphs: A spectra l perspecti ve, ” IE EE T rans. Signal Pr ocess. , vol. 60, no. 11, pp. 5820–5831 , 2012. [8] B. Oselio, A. Kule sza, and A. O. Hero, “Multi-layer graph an alysis for dynamic social netw orks, ” IEEE J ournal of Select ed T opics in Signal Pr ocessing , vol. 8, no. 4, pp. 514–523, Aug 2014. [9] K. S. Xu and A. O. Hero, “Dynamic stochastic blockmodel s for time- e volving social networks, ” IE EE J ournal of Selecte d T opics in Signal Pr ocessing , vol. 8, no. 4, pp. 552–562, 2014. [10] S. Chen, A. Sandryha ila, J. Moura, and J. K ov ace vic, “Signal recov- ery on graphs: V ariati on minimization , ” IEEE T rans. Signal Pr ocess. , vol. 63, no. 17, pp. 4609–4624, Sept. 2015. [11] A. Sandryha ila and J. M. Moura, “Big data analysis w ith signal processing on graphs: Represe ntation and processing of massi ve data sets with irregular structure, ” IEEE Signal Proce ss. Mag. , vol. 31, no. 5, pp. 80–90, 2014. [12] X. W ang, P . Liu, and Y . Gu, “Local-set-b ased graph signal reconstruc- tion, ” IEEE T rans. Signal Proce ss . , v ol. 63, no. 9, pp. 2432–244 4, May 2015. [13] A. Y . Ng, M. I. Jordan, a nd Y . W eiss, “On spe ctral clustering: Analysis and an algorithm, ” in A dvances in neural informati on pr ocessing systems (NIPS) , 2002, pp. 849–856. [14] L. Zelnik-Manor and P . Perona, “Self-tunin g spectra l clusterin g, ” in Advances in neu ral in formation pr ocessing systems (NIPS) , 2004, pp. 1601–1608. [15] U. Luxbur g, “ A tutoria l on spectral clusteri ng, ” Statistics and Computing , vol. 17, no. 4, pp. 395–416, Dec. 2007. [16] J. Shi and J. Malik, “Normalized cuts and image s egmen tatio n, ” IEEE T rans. P attern Anal. Mach . Intell. , vol. 22, no. 8, pp. 888–905, 2000. [17] S. Y u, R. Gross, and J. Shi, “Concurre nt object segmen tatio n and recogni tion with graph par tition ing, ” in Advances i n neur al information pr ocessing systems (NIPS) , 2002, pp. 1383–1390. [18] F . Radicchi and A. Arenas, “ Abrupt transition in the structural formation of inter connec ted networks, ” Natur e Physics , vol. 9, no. 11, pp. 717–720, Nov . 2013. [19] P .-Y . Chen and A. O. Hero, “ Assessing and s afeguarding networ k resilie nce to nodal attac ks, ” IEEE Commun. Mag. , vol. 52, no. 11, pp. 138–143, Nov . 2014. [20] R. Merris, “Laplacia n matrices of graphs: a surve y , ” Lin ear Algebr a and its Applicati ons , vol. 197-198, pp. 143–176, 1994. [21] J. A. Hartigan and M. A. W ong, “ A k-means clusterin algorithm, ” Applied statistic s , pp. 100–108, 1979. [22] M. Poli to and P . Perona, “Grouping and dimensiona lity reduction by local ly linear embedding, ” in Advances in neural informat ion pr ocessing systems (NIPS) , 2001, pp. 1255–1262. [23] A. Decelle , F . Krzakala , C. Moore, and L. Z deboro v ´ a, “ Asymptotic analysi s of the stocha stic block model for modular netw orks and its algorit hmic applicatio ns, ” Phys. Rev . E , vol. 84, p. 066106, Dec 2011. [24] M. Alamgir and U. von Luxburg, “Phase transitio n in the f amily of p-resistan ces, ” in Advanc es in Neura l Information Pr ocessing Syste m s (NIPS) , 2011, pp. 379–387. [25] R. R. Nadakuditi and M. E. J. Ne wm an, “Graph spectra and the detec tabil ity of c ommunity struct ure in ne tworks, ” Phys. Re v . Lett. , vo l. 108, p. 188701, May 2012. [26] E. Abbe, A. S. Bandeira, an d G. Hall, “Exact recov ery in the stochast ic block model, ” arXiv pre print arXiv:1405.3267 , 2014. [27] P .-Y . Chen and A. O. Hero, “Univ ersal phase transitio n in community detec tabil ity under a stochasti c block model, ” Phys. Rev . E , vol. 91, p. 032804, Mar 2015. [28] B. Hajek, Y . W u, and J. Xu, “ Achie ving e xact cluster recove ry threshold via semidefinite programming, ” in IEEE International Symposium on Informatio n Theory (ISIT) , June 2015, pp. 1442–1446. [29] P . W . Holland, K. B. Laskey , and S. Leinhardt, “Stochasti c blockmodels: First steps, ” Social Networks , vol. 5, no. 2, pp. 109–137, 1983. [30] J. Reichar dt and S. Bornholdt , “Stati stical m echanics of community detec tion, ” P hys. Rev . E , vol . 74, no. 1, p. 016110, 2006. [31] A. Arenas, A. Fernandez , and S. Gomez, “ Analysis of the structure of comple x netw orks at diffe rent resolution le vels, ” New J ournal of Physics , vol. 10, no. 5, p. 053039, 2008. [32] M. T . Schaub, J.-C. Delve nne, S. N. Y aliraki, and M. Barahona , “Marko v dynamics a s a zooming len s for mult iscale community dete ction: non clique -like communities and the field-of-vie w limit, ” PloS one , vol. 7, no. 2, p. e32210, 2012. [33] N. Trembla y and P . Borgnat, “Graph wav elets for multiscale community mining, ” IEEE T rans. Signal Pr ocess. , vol. 62, no. 20, pp. 5227–5239, 2014. [34] M. E. J. Newman, “Modulari ty and community s tructu re in networks, ” Pr oc. National A cademy of Science s , vol . 103, no. 23, pp. 8577–8582, 2006. [35] V . D. Blondel , J.-L. Guillaume, R. Lambiotte, and E. Lefebvre, “F ast unfoldin g of communiti es in large networks, ” Journal of Statistic al Mec hanics: Theory and E xperiment , no. 10, 2008. [36] J.-J. Daudin, F . Picard, and S. Robin, “ A m ixture model for random graphs, ” Statisti cs and Comput ing , vol. 18, no. 2, pp. 173–183, 2008. [37] C. Biernack i, G. Celeux , and G. Govae rt, “ As sessing a mixture model for clusterin g with the integrate d completed likeli hood, ” IE EE T rans. P attern Anal. Mac h. Intell. , vol. 22, no. 7, pp. 719–725, 2000. [38] M. E. J. N ewman and G. Reine rt, “Estima ting the number of commu- nitie s in a network, ” Phys. Rev . Lett. , vol. 117, p. 078301, Aug 2016. [39] B. Karrer and M. E. J. Newma n, “St ochasti c blockmodels and com- munity structure in networ ks, ” Phys. Rev . E , vol. 83, p. 016107, Jan 2011. [40] F . Krzaka la, C. Moore, E. Mossel , J. Neeman, A. Sly , L. Zdeboro v a, and P . Zhang, “Spectr al redemption in clusteri ng sparse networks, ” Pr oc. National Academy of Sciences , vol. 110, pp. 20 935–20 940, 2013. [41] A. Saade, F . Krzakala, M. Lelar ge, and L. Zdeboro va, “Spectral detect ion in the censored block model, ” , 2015. [42] M. F iedler , “ Algebraic connec ti vity of graphs, ” Czechosl ovak Mathema t- ical Jo urnal , vol. 23, no. 98, pp. 298–305, 1973. [43] A. Jennings and J . J. McKeo wn, Matrix computat ion . John W iley & Sons Inc, 1992. [44] J. A. Tropp, “ An introduc tion to matrix concen tratio n inequal ities, ” F oundation s and T re nds in Mac hine Learning , vol. 8, no. 1-2, pp. 1–230, 2015. [Onlin e]. A vail able: http:/ /dx.doi.org/10.1561/ 2200000048 [45] H. W eyl, “Das asymptotisch e vertei lungsgeset z der eigenwert e line arer partie ller dif ferential gleichungen (mit einer anwendung auf die the orie der hohl raumstrahl ung), ” Mathematisc he Annalen , v ol. 71, no. 4, pp. 441–479, 1912. [46] S. O’Rourke, V . V u, and K. W ang, “Random perturbation of low rank matrice s: Improving cl assical bounds, ” arXiv preprin t arXiv:1311.2657 , 2013. [47] C. Davis and W . M. Kahan, “The rotation of eig env ectors by a perturba tion. iii, ” SIAM J ournal on Numerical Analysis , v ol. 7, no. 1, pp. 1–46, 1970. [48] K. Rohe, S. Chatt erjee, and B. Y u, “Spectral clusteri ng and the high- dimensiona l stoc hastic blockmodel , ” The A nnals of Statistic s , pp. 1878– 1915, 2011. [49] R. F . Potthof f and M. Whitt inghill , “T esting for homogeneit y: I. the binomial and multi nomial distri butions, ” Biometrika , vol. 53, no. 1-2, pp. 167–182, 1966. [50] R. J. Simes, “ An impro ved bonferroni procedur e for multiple tests of significa nce, ” Biome trika , vol. 73, no. 3, pp. 751–754, 1986. [51] Y . Benj amini and Y . Hochberg, “Controllin g the false disco very rate: a pra ctical and po werful ap proach to multiple testin g, ” J ournal of the Royal Statisti cal Societ y . Series B (Methodolo gical) , pp. 289–300, 1995. [52] S. S. Wil ks, “The la rge-sample distribu tion of the likel ihood rati o for testing composi te hypot heses, ” The Annals of Mathemat ical Statistics , vol. 9, no. 1, pp. 60–62, 1938. [53] F . J. Anscombe, “ T he transformati on of poisson, binomial and negati ve- binomial data, ” Biometrika , vol. 35, no. 3/4, pp. 246–254, 1948. [54] Y . -P . Chang a nd W .-T . Huang, “Gen eralized confidenc e inter v als for the larg est v alue of some function s of parameters under normalit y , ” Statistica Sinica , pp. 1369–1383, 2000. [55] P .-Y . Chen, B. Zhang, M. A. Hasan, and A. O. Hero, “Incre m ental method for s pectral clusteri ng of increa sing orders, ” in A CM Interna- tional Confer ence on Knowledge Discovery and Data Mining (KDD) W orkshop on Mining and Learning with Graphs , 2016, arXi v prepri nt arXi v:1512.07349. [56] M. J. Zaki and W . M. Jr , Data Mining and Analysis: Fundamenta l Concept s and Algori thms . Cambridge Univ ersity Press, 2014. [57] D. A. Spielman, “ Algorithms, graph theory , and linear equations in lapla cian matrices, ” in Proce edings of the interna tional congr ess of mathemati cians , v ol. 4, 2010, pp. 2698–2722. [58] O. E. Li vne and A. Brandt, “Lean algebrai c multigri d (lamg): Fast graph lapla cian linear sol ver , ” SIAM J ournal on Scientific Computi ng , vol. 34, no. 4, pp. B499–B522, 2012. [59] D. J. W atts and S. H. Strogatz, “Collecti ve dynamic s of ‘sm all-w orld’ netw orks, ” Nature , vol. 393, no. 6684, pp. 440–44 2, June 1998. [Online]. A v ailable: http:// www- personal .umich.edu/ ∼ mejn/net data [60] C. Grigg, P . W ong, P . Albrec ht, R. All an, M. Bha varaju, R. Billinton, Q. Chen, C. Fong, S. Haddad, S. Kurugant y , W . L i, R. Mukerj i, D. Patt on, N. Rau, D. Rep pen, A. Schneide r, M. Shahidehpour , and C. Singh, “The IEEE reliabil ity test system-1996. a report prepared by the reliabilit y test system task force of the applicati on of proba bilit y methods subcommitte e, ” IEEE T rans. P ower Syst. , vol . 14, no. 3, pp. 1010–1020, 1999. [61] S. Knight, H. Nguyen, N. Falkn er , R. Bowden, and M. Roughan, “The Interne t topology zoo, ” IEEE J. Sel. A re as Commun. , vol. 29, no. 9, pp. 1765–1775, Oct. 2011. [Online]. A vai lable: http:/ /www .topology-zoo.org/dataset.html [62] [Online]. A vaila ble: https://www .cs.purdue.edu/homes/dgl eich/packages/matlab bgl/ [63] M. J. Z aki and W . Meira Jr , Data mini ng and analysis: fundamental concep ts and algorithms . Cambridge Univ ersity Press, 2014. [64] S. Resnick, A Pr obability P ath . Birkh ¨ auser Boston, 2013. [65] P . V an Mie ghem, Graph Spectr a for Comple x Netw orks . Cambridge Uni versity P ress, 2010. [66] R. Lata la, “Some estimates of norms of random matrices.” Pr oc. Am. Math. Soc. , vol. 133, no. 5, pp. 1273–1282, 2005. [67] R. A. Horn and C. R. Johnson, Ma trix Analysi s . Cambridge Un i versity Press, 1990. A C K N O W L E D G M E N T The fi rst author would like to than k Mr . Chu n-Chen Tu fro m the University of Michigan Ann Arbor , USA, for his help in implementin g the Newman-Reinert method. S U P P L E M E N T A RY M A T E R I A L F O R P H A S E T R A N S I T I O N S A N D A M O D E L O R D E R S E L E C T I O N A L G O R I T H M F O R S P E C T R A L G R A P H C L U S T E R I N G A U T H O R S : P I N - Y U C H E N A N D A L F R E D O . H E R O I I I A. Pr oo f of Cor o llary 1 Recall the eige nvector m a trix Y = [ Y T 1 , Y T 2 , . . . , Y T K ] T , where Y k is th e n k × ( K − 1) ma tr ix with row vec- tors rep resenting th e node s from cluster k . Since Y T Y = P K k =1 Y T k Y k = I K − 1 , Y T 1 n = P K k =1 Y T k 1 n k = 0 K − 1 , and from (28) when p < p ∗ the matrix √ n k Y k a.s. − → 11 T K − 1 V k = v k 1 1 , v k 2 1 , . . . , v k K − 1 1 as n k → ∞ and n min n max → c > 0 , by the fact that 1 n k 1 T K − 1 V k → 11 T K − 1 V k we have P K k =1 v k v k T = I K − 1 ; P K k =1 v k = 0 K − 1 , (43) where v k = [ v k 1 , v k 2 , . . . , v k K − 1 ] T is a vector o f constants. The condition in (43) s uggests that som e v k cannot be a zero vecto r since P K k =1 ( v k j ) 2 = 1 for all j ∈ { 1 , 2 , . . . , K − 1 } , and f r om (43) we have P k : v k j > 0 v k j = − P k : v k j < 0 v k j , ∀ j ∈ { 1 , 2 , . . . , K − 1 } ; P k : v k i v k j > 0 v k i v k j = − P k : v k i v k j < 0 v k i v k j , ∀ i, j ∈ { 1 , 2 , . . . , K − 1 } , i 6 = j. (44) Lastly , using the fact th at √ n Y = r n n 1 √ n 1 Y T 1 , . . . , r n n K √ n K Y T K T (45) a.s. − → r 1 ρ 1 v 1 1 T , . . . , r 1 ρ K v K 1 T T (46) as n k → ∞ for all k an d n min n max → c > 0 , we co nclude the proper ties in Cor ollary 1. B. Pr oo f of Cor o llary 2 If c n = Ω n max n , then by Theor em 2 (c) p LB > 0 . Therefo re p ∗ ≥ p LB > 0 . Similarly , if c n = o n min n , then by Theorem 2 (c) p UB = 0 . Therefo re p ∗ = 0 . Finally , since S 2: K ( L k ) = P K i =2 λ i ( L k ) ≥ ( K − 1) λ 2 ( L k ) and S 2: K ( L k ) = P K i =2 λ i ( L k ) ≤ ( K − 1) λ K ( L k ) , we hav e ( K − 1 ) c ∗ 2 ≤ c ∗ ≤ ( K − 1) c ∗ K . Applying these two inequalities to Theor e m 2 (c) gives Cor o llary 2 (c). C. Pr o o f of Cor o llary 3 If cluster k is a complete graph, then λ i ( L k ) = n k for 2 ≤ i ≤ n k [65], wh ich imp lies c ∗ = min k ∈{ 1 , 2 ,.. .,K } ρ k = ρ min . Therefo re, p LB = ρ min ρ max = c , and p UB = 1 . If cluster k is a star graph, then λ i ( L k ) = 1 for 2 ≤ i ≤ n k − 1 [65], which imp lies c ∗ = 0 and h ence c ∗ = o ( ρ min ) . As a result, b y Coro llary 2 (b) p ∗ = 0 . D. Pr oof o f (3) If cluster k is a Erdo s-Renyi rand om g raph with edge connectio n prob ability p k , then λ i ( L k ) n k a.s. − → p k for 2 ≤ i ≤ n k [2] as n k → ∞ and n min n max → c > 0 , where p k is a constant. Therefo re, p LB = min k ∈{ 1 , 2 ,...,K } ρ k p k ρ max ≥ c · min k ∈{ 1 , 2 ,.. .,K } p k , and p UB = min k ∈{ 1 , 2 ,...,K } ρ k p k ρ min ≤ ρ max · min k ∈{ 1 , 2 ,...,K } p k ρ min = 1 c · min k ∈{ 1 , 2 ,.. .,K } p k . E. Pr oo f of Cor o llary 4 Corollary 4 (a) is a direct resu lt f rom Theo rem 2 (a), with K = 2 and the fact th at min { a, b } = a + b −| a − b | 2 for all a, b ≥ 0 . Corollary 4 (b) is a direct result from Theorem 2 (b) and Corollary 1 , with the ortho normality con straints that y T 1 1 n 1 + y T 2 1 n 2 = 0 an d y T 1 y 1 + y T 2 y 2 = 1 . Corollar y 4 (c) is a direct result from Corollary 2 (c) , with max { a, b } = a + b + | a − b | 2 for all a, b ≥ 0 . F . Pr oof of Cor ollary 5 W e first show that when p max < p ∗ , the normalized second eigenv alue of L , λ 2 ( L ) n , lies within th e interval [ p min , p max ] almost surely as n k → ∞ a n d n min n max → c > 0 . Consider a graph gener ated by the in homog eneous RIM with param eter { p ij } . In [2] it was established that k C ij − C ij k 2 √ n i n j a.s. − → 0 , where C ij = p ij 1 n i 1 T n j , which m eans that when prop erly nor malized by √ n i n j the matrices C ij and C ij asymptotically have identical singular values and singu lar vectors for any cluster pair i and j as n k → ∞ for all k and n min n max → c > 0 . Let A ( p ) be the adjacency matrix und er the ho mogene o us RIM with param eter p . Then the ad jacency matrix A of the inhomo geneou s RIM can be written as A = A ( p min ) + ∆A , and the graph Laplacian ma trix associated with A can be written as L = L ( p min ) + ∆L , where L ( p min ) and ∆L are associated with A ( p min ) and ∆A , respectively . Let − − → ∆ A , − → ∆ L , and − − → L ( p ) denote th e limit of ∆A n , ∆L n , and L ( p ) n , respectively . Since p min = min i 6 = j p ij , as n k → ∞ an d n min n max → c > 0 , − − → ∆ A is a sym metric nonn egati ve ma tr ix almost surely , and − → ∆ L is a graph Laplacian matrix almost surely . By the PSD proper ty of a grap h Laplac ia n m atrix and Corollary 4 (a), we obtain λ 2 ( L ) n ≥ p min almost surely as n k → ∞ and n min n max → c > 0 . Similarly , following the same procedu r e we can show that λ 2 ( L ) n ≤ p max almost surely a s n k → ∞ and n min n max → c > 0 . Lastly , when p < p ∗ , using th e fact from (20) that λ j ( L ( p )) n a.s. − → p , and λ j ( L ( p min )) n ≤ λ j ( L ) n ≤ λ j ( L ( p max )) n almost surely for all j ∈ { 2 , 3 , . . . , K } as n k → ∞ and n min n max → c > 0 , we obtain the results. G. Pr oof of Theo r em 4 Similar to the proof of Theore m 2, for undirected weigh ted graphs u nder the homo geneou s RIM w e n eed to show k W ij − W ij k 2 √ n i n j a.s. − → 0 as n i , n j → ∞ and n min n max → c > 0 , where W ij is the weight matrix of inter-cluster edges between a cluster pair ( i, j ), W is the mea n of th e comm on non n egati ve inter-cluster ed g e weight d istribution, an d W ij = pW 1 n i 1 T n j when p ij = p . Equiv alently , we nee d to show σ 1 ( W ij ) √ n i n j a.s. − → p W ; σ ℓ ( W ij ) √ n i n j a.s. − → 0 , ∀ ℓ ≥ 2 , (47) for all i, j ∈ { 1 , 2 , . . . , K } as n i , n j → ∞ and n min n max → c > 0 . By the smo othing pro perty in con ditional expectation we have the mean of [ W ij ] uv to be E [ W ij ] uv = E [ E [[ W ij ] uv [ C ij ] uv | [ C ij ] uv ]] (4 8) = E [ C ij ] uv E [[ W ij ] uv | [ C ij ] uv ] (49) = p W . Let ∆ = W ij − W ij , where W ij = pW 1 n i 1 T n j is a matrix whose e lem ents are the mean s of entries in W ij . Then [ ∆ ] uv = [ W ij ] uv − p W with p robability p and [ ∆ ] uv = − pW with probab ility 1 − p . The Latala’ s theor em [6 6] states that for any random matrix M with statistically indepe n dent and zero mean entries, th e re exists a positiv e constant c 1 such that E [ σ 1 ( M )] ≤ c 1 max u s X v E [[ M ] 2 uv ] + max v s X u E [[ M ] 2 uv ] + 4 s X u,v E [[ M ] 4 uv ] . (50) It is clear that E [[ ∆ ] uv ] = 0 and each entr y in ∆ is indepen d ent. Sub stituting M = ∆ √ n i n j into th e Latala’ s theorem, since p ∈ [0 , 1 ] and the common inter-cluster edge weight d istribution has finite f ourth m o ment, by the smooth- ing pr operty we have max u p P v E [[ M ] 2 uv ] = O ( 1 √ n i ) , max v p P u E [[ M ] 2 uv ] = O ( 1 √ n j ) , and 4 q P u,v E [[ M ] 4 uv ] = O ( 1 4 √ n i n j ) . Therefo re E h σ 1 ( ∆ ) √ n i n j i → 0 for all i , j ∈ { 1 , 2 , . . . , K } as n i , n j → ∞ and n min n max → c > 0 . Next we use th e T alagrand’ s con centration theo r em stated as follows. L e t g : R k 7→ R be a co n vex an d Lipschitz functio n. Let x ∈ R k be a random vector and assume that every elemen t of x satisfies | x i | ≤ φ for all i = 1 , 2 , . . . , k and som e constant φ , with p r obability one. Then the r e exist positiv e co nstants c 2 and c 3 such that for any ǫ > 0 , Pr ( | g ( x ) − E [ g ( x )] | ≥ ǫ ) ≤ c 2 exp − c 3 ǫ 2 φ 2 . (51) It is well-k n own that the largest singu lar value of a matrix M can b e r epresented as σ 1 ( M ) = max z T z =1 || Mz || 2 [67] so that σ 1 ( M ) is a con vex and Lipschitz function . Applying the T alagrand ’ s the o rem by substituting M = ∆ √ n i n j and using the facts that E h σ 1 ( ∆ ) √ n i n j i → 0 and [ ∆ ] uv √ n i n j ≤ [ W ] uv √ n i n j , we hav e Pr σ 1 ( ∆ ) √ n i n j ≥ ǫ ≤ c 2 exp − c 3 n i n j ǫ 2 . (52) Since for any positive integer n i , n j > 0 n i n j ≥ n i + n j 2 , P n i ,n j c 2 exp − c 3 n i n j ǫ 2 < ∞ . By Borel-Cantelli lemma [64], σ 1 ( ∆ ) √ n i n j a.s. − → 0 when n i , n j → ∞ . Finally , a standar d matrix pertur b ation theory result ( W eyl’ s inequ ality) [45], [67] is | σ ℓ ( W ij + ∆ ) − σ ℓ ( W ij ) | ≤ σ 1 ( ∆ ) for all ℓ , and as σ 1 ( ∆ ) √ n i n j a.s. − → 0 , we have as n i , n j → ∞ , σ 1 ( W ij ) √ n i n j = σ 1 W ij + ∆ √ n i n j a.s. − → p W ; (53) σ ℓ ( W ij ) √ n i n j a.s. − → 0 , ∀ ℓ ≥ 2 . (54) This implies that after prope r normaliza tio n by √ n i n j , W ij and W ij asymptotically hav e the same singular v a lues. Fur- thermor e , by the Da vis-Kahan sin θ theore m [46], [47], the singular vectors of W ij √ n i n j and W ij √ n i n j are close to each o ther in the sense that the square o f inner pro duct of their left/right sin - gular vectors con verges to 1 almost surely wh en σ 1 ( ∆ ) √ n i n j a.s. − → 0 . Therefo re, after proper n ormalization b y √ n i n j , W ij and W ij also asy mptotically hav e the sam e sing ular vectors. Lastly , f ollowing the same p roof procedu r e in App endix-B, we obtain Theorem 4. H. Asymptotic confi dence interval fo r the homogeneous RIM Here we d efine the generalized log -likelihood ra tio test (GLR T ) und er the RIM for th e h ypothesis H 0 : p ij = p ∀ i, j, i 6 = j , against its alternative h ypothesis H 1 : p ij 6 = p , for at least one i, j , i 6 = j . Let f h ij ( x, θ |{ b G k } K k =1 ) den ote the likelihood fu nction of o bserving x edg es between b G i and b G j under hyp othesis H h , and θ is the ed ge interconnec tion probab ility . b n k is the num ber of nodes in clu ster k , and b m ij is the nu m ber of edges between clusters i an d j . Then under the RIM f 1 ij ( b m ij , p ij |{ b G k } K k =1 ) = b n i b n j b m ij p b m ij ij (1 − p ij ) b n i b n j − b m ij ; f 0 ij ( b m ij , p |{ b G k } K k =1 ) = b n i b n j b m ij p b m ij (1 − p ) b n i b n j − b m ij . Since b p ij is the MLE of p ij under H 1 and b p is the MLE of p under H 0 , the GLR T statistic is GLR T = 2 ln sup p ij Q K i =1 Q K j >i f 1 ij ( b m ij , p ij |{ b G k } K k =1 ) sup p ij = p Q K i =1 Q K j >i f 0 ij ( b m ij , p ij |{ b G k } K k =1 ) = 2 ln Q K i =1 Q K j = i +1 f 1 ij ( b m ij , b p ij |{ b G k } K k =1 ) Q K i =1 Q K j = i +1 f 0 ij ( b m ij , b p |{ b G k } K k =1 ) = 2 K X i =1 K X j = i +1 I { b p ij ∈ (0 , 1) } [ b m ij ln b p ij +( b n i b n j − b m ij ) ln(1 − b p ij )] − m − K X k =1 b m i ! ln b p − " 1 2 n 2 − K X k =1 b n 2 k ! − m − K X k =1 b m k !# ln(1 − b p ) ) , where we use th e relation s th at P K i =1 P K j = i +1 b m ij = m − P K k =1 b m k and P K i =1 P K j = i +1 b n i b n j = n 2 − P K k =1 b n 2 k 2 . By the W ilk’ s theorem [52], as n k → ∞ ∀ k , this statistic con verges in law to the ch i-square distrib u tion, d enoted b y χ 2 ν , with ν = K 2 − 1 degrees of fr eedom. Therefor e, we ob ta in the asymptotic 100(1 − α )% confidence interval for p in (5). I. Pha se tr a nsition tests for undir ected weighted graphs Giv en cluster s { b G k } K k =1 of an un directed weighted graph obtained from spectral clustering with m odel order K , let c W be the av e r age weight of the in te r-cluster e dges and define b t ij = b p ij · c W , b t = b p · c W , b t max = b p max · c W and b t LB = min k ∈{ 1 , 2 ,...,K } S 2: K ( b L k ) ( K − 1) b n max . For undirected weigh ted graphs, th e first phase o f testing the RIM assum p tion in the AMOS algorith m is identical to und irected unwe ighted graphs, i.e., the estimated local inter-cluster ed ge connection probab ilities b p ij ’ s are u sed to test the RIM hypothe sis. In the second phase, if th e clusters pass the homoge n eous RIM test (i.e., the estimate of globa l inter-cluster ed ge pr obability b p lies in the co nfidence inter val specified in (5) ), the n based on the phase transition results in T heorem 4, th e clusters pass th e homogeneo us phase tran sition test if b t < b t LB . If the homog eneous RIM test fails, then by Theorem 3 the clusters pass th e inhomoge n eous RIM test if b t max lies in a confide nce interval [0 , ψ ] and ψ < t ∗ . Mor eover , since testing b t max < t ∗ is equivalent to testing b p max < t ∗ c W , as discussed in Sec. V -C, we can verify ψ < t ∗ by checking the cond ition K Y i =1 K Y j = i +1 F ij b t LB c W , b p ij ! ≥ 1 − α ′ , where α ′ is the precision param eter of the confidenc e inter val. J. Ad d itional r esu lts of phase transition in simulated networks Fig. 7 (a ) shows the phase transition in n ormalized p artial eigenv alue sum S 2: K ( L ) n and clu ster d etectability for clusters generated by Er dos-Renyi random graph s with different n et- work sizes. As pre dicted by Theorem 2 (a), the slope of S 2: K ( L ) n undergoes a phase transition at some critical threshold value p ∗ . When p < p ∗ , S 2: K ( L ) n is exactly 2 p . When p > p ∗ , S 2: K ( L ) n is up per an d lower boun d ed by the derived bounds. Fig. 7 ( b) shows the row vectors of Y that verifies Theo rem 2 (b) and Cor ollary 1. Similar phase transition can be f ound for clusters generated by the W atts-Strogatz small world network model [59] with different cluster sizes in Fig . 8. Next we inves tigate the sensitivity of cluster detectab ility to the inh o mogen eous RIM. W e con sider the perturbation model p ij = p 0 + unif ( − a, a ) , where p 0 is the base edge con nection probab ility and unif ( − a, a ) is an unif orm rand o m variable with sup port ( − a, a ) . The simu lation results in Figs. 9 ( a) and (b) show that almo st perfect cluster d etectability is still valid when p ij is within certain perturbation of p 0 . The sensiti v ity of cluster detectability to inhomog e neous RIM also implies that if b p is within the confidence inter val in (5), then almost perfect cluster detectability can be expected. Note th at Theorem 1 also explains the effect o f the perturb a- tion mo del p ij = p 0 + u nif ( − a, a ) on cluster detectability . As a increases the off-diagonal entr ies in e A further d eviate from 0 and the m atrix e A ⊕ − Λ in App endix-A gradually b ecomes non-sing ular, resulting in the degradation of cluster d etectabil- ity . Furthe rmore, using Theor em 1 and the Ge r shgorin cir cle theorem [67], each eigenv alue of e A n lies within at least o ne of the closed disc centered at [ e A ] ii n with radius R i , where R i = n i n P K − 1 j =1 ,j 6 = i | p iK − p ij | . Th erefore larger inhom ogeneity in p ij further driv es the matrix e A ⊕ − Λ aw ay from singularity . K. Clustering results of AMOS in the Cogent and Minnesota r oad datasets As shown in Fig. 10, the clusters of the Cogent Internet backbo ne map yield ed b y AMOS are con sistent with the g eo- graphic locatio ns except that North Ea ster n Am erica and W est Europ e ar e identified as one cluster du e to many tran soceanic connectio ns, wher es the clusters yielded b y self-tunin g spectral clustering are inconsistent with the geogr aphic lo cations. Fig. 11 shows that the clusters o f the Minn esota road map v ia AMOS are aligned with the geogra phic separations, whereas some clusters identified via self-tunin g clu stering are incon sistent with the geog r aphic sep arations and several clusters hav e small sizes 3 . L. P erformance of the Louvain meth od, the non backtrac king matrix method , and the Newman-Reinert method on real-life network datasets Fig. 1 2, Fig. 13, and Fig. 1 4 show the cluster s of the d atasets in T able II identified by the nonba c ktracking matrix metho d [40], [ 41], th e Lou vain method [35], and the Newman-Reinert method [3 8], respectively . Comparing the proposed AMOS algorithm with th ese method s, the c lu sters identified by AM O S are more consistent with the groun d -truth meta inform ation provided b y the datasets, except for Cogent Inter net Internet backbo ne map. For th e Co g ent d ataset AMOS has com pa- rable p erform ance to the best me thod (the Newman-Reinert method) . The p erform a n ce of the n onback tr acking matrix metho d is summarized as follows. For I E EE reliab ility test system, 8 nodes are clustered incorrectly . For Hibern ia I nternet ba ckbone map, 3 cities in the nor th Ame rica are clustered with the cities in Eu r ope. For Cogen t Intern et backbo ne map, the clusters are inco nsistent with the ge ograph ic locatio n s. For Minn esota road map, some clusters are no t a lig ned with the geograph ic separations. The performan ce of the Louvain meth od is summ arized as follows. For IE EE reliability test system, the number of clusters is d ifferent from the number of actu al sub grids. For Hib e rnia an d Cogent In ternet backbo ne maps, although the clusters are co n sistent with the geog raphic locations, the Louvain meth od ten ds to identify clusters with small sizes. For Minnesota roa d map, the clusters ar e incon sistent with the geograp h ic separatio ns. The performance of the Newman-Reinert m ethod is summa- rized as fo llows. F or IEEE re liab ility test system, 6 clusters are identified and th e clustering results are incon sistent with the ground-tr u th cluster s. For H ib ernia Internet back bone m ap, 3 c ities in th e north Ame rica are clustered with the c ities in Eu r ope. For Cogen t Intern et backbo ne map, the clusters are co nsistent with the geogr a p hic locations. For Minne so ta road map, the clusters are incon sistent with the geog r aphic separations. 3 For the Minnesota roa d map we set K max = 100 for self-tuning spectra l clusteri ng t o speed up the computation. M. External and interna l clustering metrics W e use the f ollowing extern al and internal clusterin g metrics to ev aluate the perfo rmance of different autom ated graph clustering method s. Exter nal metrics can be compu ted on ly when groun d-truth clu ster labels are known, whereas internal metrics can be computed in th e absence of g round -truth cluster labels. In particular, we denote the K clusters identified by a graph clustering algorithm by { C k } K k =1 , and denote the K ′ groun d-truth clu sters by {C ′ k } K ′ k =1 . • external clustering metrics 1) norm alized mutual inf ormation ( N M I) [6 3]: NMI is defined as NMI ( {C k } K k =1 , {C ′ k } K ′ k =1 ) = 2 · I ( {C k } , { C ′ k } ) | H ( {C k } ) + H ( {C ′ k } ) | , where I is th e mu tual inf ormation between { C k } K k =1 and {C ′ k } K ′ k =1 , and H is the entro py o f clusters. Larger NMI means better clustering perfo rmance. 2) Rand index (RI) [63]: RI is defined as RI ( {C k } K k =1 , {C ′ k } K ′ k =1 ) = T P + T N T P + T N + F P + F N , where T P , T N , F P and F N represent true positi ve, true ne g ativ e , false positi ve, an d false ne gativ e d ecisions, respectively . Larger RI means better c lustering perfo r- mance. 3) F-measure [63]: F- measure is the harmo nic m e an of the precision and recall values for each clu ster , which is defined as F-measure ( {C k } K k =1 , {C ′ k } K ′ k =1 ) = 1 K K X k =1 F-measure k , where F-measure k = 2 · P RE C k · RE C ALL k P RE C k + RE C ALL k , and P RE C k and R E C ALL k are the precision and rec all values for cluster C k . Larger F-measure means better clustering perfor mance. • internal clustering metrics 1) cond u ctance [ 1 6]: conductance is defined as condu c ta n ce ( {C k } K k =1 ) = 1 K K X k =1 condu c ta n ce k , where cond uctance k = W out k 2 · W in k + W out k , and W in k and W out k are the sum o f within- cluster an d between-clu ster edge weights of clu ster C k , respectively . Lower co nduc- tance means better clustering perfor mance. 2) norm alized cut ( NC) [16]: NC is defined as NC ( {C k } K k =1 ) = 1 K K X k =1 NC k , where NC k = W out k 2 · W in k + W out k + W out k 2 · ( W all k − W in k )+ W out k , and W in k , W out k and W all k are the sum o f with in-cluster, between-clu ster and total edg e weigh ts of cluster C k , respectively . Lower NC means better clu stering perfor- mance. 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0 0.5 1 1.5 p S 2: K ( L ) n si m u lat ion S 2: K ( L ) n = 2 p upp er bound lo wer b ound 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.2 0.4 0.6 0.8 1 p cluster detectability simulation random guess (a) P hase transition in normalized partial sum of eigen- v alues S 2: K ( L ) n and cluster detectability . (b) Row v ectors in Y with respect to different p . Colors and red solid circles r epresent cl usters and cluster-wise centroids. Fig. 7: Phase transition of clusters gen e rated by Erdo s-Renyi random g raphs. K = 3 , ( n 1 , n 2 , n 3 ) = (6000 , 8000 , 10000) , and p 1 = p 2 = p 3 = 0 . 2 5 . The empiric a l lower bo und p LB = 0 . 1373 and the em p irical upper bo und p UB = 0 . 22 88 . The results in (a) are av e r aged over 50 trials. 0 0.05 0.1 0.15 0.2 0 0.1 0.2 0.3 0.4 p S 2: K ( L ) n si m u lat ion S 2: K ( L ) n = 2 p upp er bound lo wer b ound 0 0.05 0.1 0.15 0.2 0.2 0.4 0.6 0.8 1 p cluster detectability simulation random guess (a) P hase transition in normalized partial sum of eigen- v alues S 2: K ( L ) n and cluster detectab i lity . −0.05 0 0.05 −0.05 0 0.05 p = 0 . 045 −0.05 0 0.05 −0.05 0 0.05 p = 0 . 05 −0.05 0 0.05 −0.05 0 0.05 second component p = 0 . 055 −0.05 0 0.05 −0.05 0 0.05 second component p = 0 . 06 −0.1 0 0.1 −0.1 0 0.1 first component p = 0 . 065 −0.1 0 0.1 −0.1 0 0.1 first component p = 0 . 07 (b) Ro w vectors in Y with respect to different p . Colors and red solid circles r epresent cl usters and cluster-wise centroids. Fig. 8: Phase transition of clusters gener ated by the W atts- Strogatz small world network model. K = 3 , ( n 1 , n 2 , n 3 ) = (1500 , 1000 , 1000) , average number of neighbo rs = 200 , and rewire p r obability for e a ch cluster is 0 . 4 , 0 . 4 , and 0 . 6 . The empirical lower and upper boun ds ar e p LB = 0 . 0 6 02 an d p UB = 0 . 09 0 2 . The results in ( a) are av eraged over 50 trials. 0 0.05 0.1 0.15 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 a cluster detectability simulation random guess (a) 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 a cluster detectability simulation random guess (b) Fig. 9: Sensitivity of cluster detectability to the in homog e- neous RIM . The results are average over 50 tr ials and err or bars repre sen t stan dard deviation. (a) Clusters gener ated b y Erdos-Renyi rando m graphs. K = 3 , n 1 = n 2 = n 3 = 80 0 0 , p 1 = p 2 = p 3 = 0 . 2 5 , an d p 0 = 0 . 15 . (b) Clusters gene r ated by th e W atts-Str o gatz small world network model. K = 3 , n 1 = n 2 = n 3 = 10 0 0 , av er age num b er of ne ig hbors = 2 00 , and re wir e pro bability fo r each cluster is 0 . 4 , 0 . 4 , 0 . 6 , an d p 0 = 0 . 08 . (a) Proposed AMOS algo rithm. T he number of clusters is 4 . (b) Self-tuning sp ectral clustering [14]. The numbe r of clusters is 14 . Fig. 10: The Cogent Inte r net backb one map across Europ e and North Amer ica [6 1]. Clusters fro m autom ated SGC are con sistent with th e ge o graph ic loc a tio ns, where a s clusters f rom self-tu ning spectral clustering ar e inc onsistent w ith the geograph ic locations. Automated clusters found by AMOS, includin g city na mes, can be found in the supplemen ta r y mater ia l. 10 20 30 40 (a) Proposed AMOS algorithm. The number of clusters is 46 . 20 40 60 80 100 (b) Self-tuning spectral clustering [14]. The number of clusters is 100 . Fig. 11: Minnesota road map [62]. Clusters from automated SGC are align ed with the geograp hic separations, wh ereas some clusters fro m self-tuning spectral cluster in g are inc o nsistent with the geographic sep arations and self- tu ning spectral clustering identifies se veral small clusters. power line subgrid 1 subgrid 2 subgrid 3 Nonbacktracking matrix method (a) IEEE reliabili t y test system. The number of clusters i s 3 . (b) Hibernia Internet backbo ne map. The number of clusters is 2 . (c) Cogent Internet backbone map. The number of cl usters is 3 . 5 10 15 20 25 30 35 (d) Minnesota road map. The number of clusters i s 35 . Fig. 12: Clusters fou nd with the nonba c ktracking matrix method [40], [4 1]. For IEEE reliability test system, 8 nodes are clustered inco rrectly . For Hibern ia Interne t backbon e map, 3 cities in th e no rth America are clustered with the cities in Eu rope. For Cog ent In te r net b ackbone map, th e clusters are inconsistent with the geog r aphic locatio ns. For M in nesota road m ap, some clusters are not aligned with the geogr aphic sep a r ations. power line subgrid 1 subgrid 2 subgrid 3 Louvain method (a) IEEE reliabili t y test system. The number of clusters i s 6 . 1 2 3 4 5 6 (b) Hibernia Internet ba ckbone map. The number of clusters is 6 . 1 2 3 4 5 6 7 8 9 10 11 (c) Cogent Internet backb one map. The number of clusters is 11 . 5 10 15 20 25 30 (d) Minnesota road map. The number of clusters i s 33 . Fig. 1 3 : Clusters found with the L ouvain method [35]. For IEEE reliability test system, the n u mber of clusters is different from the number of actual subgr ids. For Hibernia and Cogent Inter n et back b one maps, although the clusters ar e co nsistent with the geogra p hic location s, th e Lou vain method ten d s to identify clusters with small sizes. For M innesota road map, the clusters are inconsistent with the geogr a phic separ ations. 1 2 3 4 5 6 (a) IEEE reliabili t y test system. The number of clusters i s 6 . (b) Hibernia Internet backbo ne map. The number of clusters is 2 . (c) Cogent Internet backbone map. The number of cl usters is 3 . 10 20 30 40 50 (d) Minnesota road map. The number of clusters i s 58 . Fig. 14 : Clusters f ound with the Newman-Reinert method [3 8]. For IEEE r e liability test system, the clusters are incon sistent with the actual sub grids. For Hibe r nia Internet backb one map, 3 cities in the no rth America are clustered with the cities in Europ e . For Cogent Intern et backbo ne map, the clusters ar e co nsistent with the geog raphic location s. For Min nesota road map , the clusters are inconsistent with the geog raphic separa tio ns. Raleigh Miami Atlanta Charlotte Buffalo Cleveland Chicago Toronto Montreal Albany Unknown Unknown Richmond New York Amsterdam Dusseldorf Southport Manchester Reading London Egham Biache Paris Brussels Portrush Baltimore Washington Dc Mannheim Frankfurt Newark Strasbourg Pittsburgh Ashburn McClean Philadelphia Dublin Belfast Sainte−Foy Boston Stamford White Plains Halifax Truro Moncton Edmundston Houston Tampa Seattle Denver San Francisco Los Angeles San Diego Las Vegas Phoenix Dallas Fig. 15 : 2 clu ster s found with the propo sed autom ated mode l or der selection (A M OS) algorithm fo r the Hibern ia Internet backbo ne map with city names. The clusters are consistent w ith the g eograp hic locations in the sense that one cluster con tains cities in America and the other cluster contains cities in Europ e. Timisoara Bucharest Mainz Wiesbaden Mannheim Stuttgart Nuremberg Munich Vienna Bratislava Budapest Milwaukee Minneapolis South Bend Chicago Kansas City St Louis Des Moines Omaha Louisville Nashville Gijon Santander Vigo Leon Zaragoza Barcelona Bilbao Logrono Avila San Sebastian Indianapolis Cincinnati Toledo Detroit Dayton Columbus Hamilton Cleveland Buffalo Toronto Oslo Stockholm Copenhagen Malmo Newcastle Leeds Glasgow Edinburgh Liverpool Southport Manchester Lisbon Coimbra Alicante Murcia Madrid Valencia Sevilla Badajoz Granada Malaga Austin San Antonio New Orleans Jackson Tulsa Oklahoma City Fort Worth Dallas Memphis Houston Tours Nantes Rennes Caen Rouen Reims Luxembourg Frankfurt Bordeaux Poiters Miami Boca Raton Atlanta Charlotte Greensboro Raleigh Tampa Orlando Jacksonville Birmingham Nice Grenoble Lyon Dijon Toulouse Montpellier Marseille Sophia Prague Geneva Bern Los Angeles Orange County San Francisco Santa Clara Sacramento Oakland Salt Lake City Boise San Diego Phoenix Arezzo Rome Odessa Galati Balchik Constanta Burgas Varna Sofia Kapitan Andreevo McAllen Laredo Queretaro Monterrey Mexico City Guadalajara Albuquerque El Paso Denver Colorado Springs Dresden Basel Strasbourg Milan Zurich Zagreb Genoa Padua Venice Ljubljana Florence Bologna Berlin Hamburg Unkown White Plains Baltimore Unkown Unkown Unkown Unkown Newark Philadelphia Harrisburg Washington Boston Providence Stamford New York Herndon Pittsburgh Cologne Dusseldorf Amsterdam Cambridge London Slough Essen Dortmund Munster Rotterdam Unkown Unkown Unkown Unkown Unkown Unkown Dublin Seattle Portland Las Vegas Montreal Tallinn Paris Lille Bremen Brussels Antwerp Porto Helsinki Kharkiv Kiev Warsaw Krakow Brno Worcester Albany Fig. 16 : 4 cluster s fo und with th e pro posed automated model o rder selection (AMOS) algorith m for the Co g ent Intern et backbo ne map with city names. Clusters a r e separated by geograp hic location s except f or th e cluster containin g cities in North Eastern America and W est Europ e d ue to many transoceanic connections.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment