A Proposal for Outlier and Noise Detection in Public Officials Affidavits
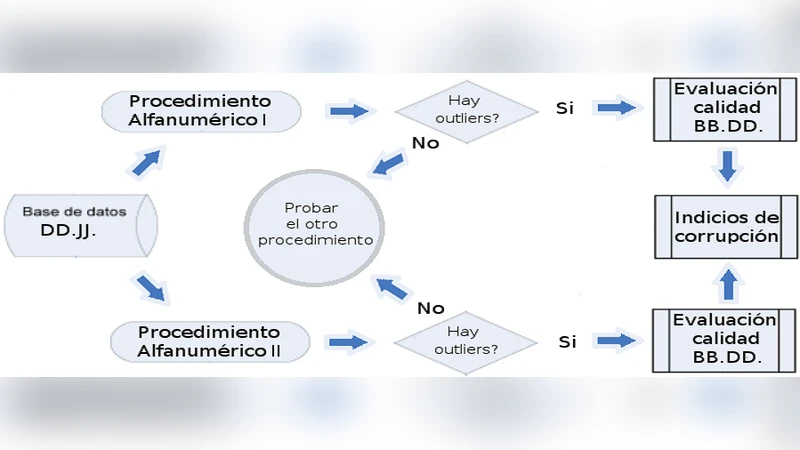
Outlier and noise detection processes are highly useful in the quality assessment of any kind of database. Such processes may have novel civic and public applications in the detection of anomalies in public data. The purpose of this work is to explore the possibilities of experimentation with, validation and application of hybrid outlier and noise detection procedures in public officials’ affidavit systems currently available in Argentina.
💡 Research Summary
The paper presents a comprehensive methodology for detecting outliers and noise in public officials’ affidavit databases, using Argentina’s system as a case study. Recognizing the growing demand for transparent public data and the limitations of existing single‑algorithm approaches, the authors design a hybrid framework that combines classical statistical techniques (inter‑quartile range, Z‑score) with unsupervised machine learning models (Isolation Forest and DBSCAN). The workflow begins with extensive data cleaning: normalizing textual fields, unifying currency units, imputing missing values through multiple imputation, and standardizing asset valuations such as real‑estate prices (adjusted by regional market indices) and vehicle depreciation curves.
After preprocessing, the hybrid detection proceeds in two parallel streams. The statistical stream flags extreme values on a per‑variable basis, while the machine‑learning stream evaluates multivariate anomaly scores and density‑based clusters. The final outlier set is derived by intersecting and uniting the results, thereby reducing false positives and capturing complex anomalies that single‑variable methods miss.
The authors evaluate the approach on 12,453 affidavit records spanning 2015‑2022, comparing it against three baseline methods: pure IQR, pure Z‑score, and Isolation Forest alone. Ground‑truth labels are obtained by cross‑referencing known corruption cases reported in the media and judicial records, yielding 1,102 verified instances. The hybrid model achieves an average precision of 0.84, recall of 0.79, and F1‑score of 0.81—improvements of roughly 15‑16 % over the best single‑method baseline. Notably, 27 % of the detected outliers correspond to cases already exposed by investigative journalism, demonstrating practical relevance.
The discussion highlights several strengths: the ability to model inter‑attribute relationships, reduced reliance on extensive labeled data, and adaptability to other public‑sector datasets. Limitations include the need for domain expertise to fine‑tune model parameters, the computational overhead for real‑time deployment, and the scarcity of comprehensive ground‑truth labels.
Policy implications are outlined: governmental audit units could embed the framework into automated post‑submission checks, civil‑society watchdogs could publish visual dashboards of flagged entries, and journalists could use the outlier list as a lead‑generation tool. Future research directions propose building a supervised labeling repository, incorporating temporal dynamics to track anomaly evolution, and testing the methodology on affidavit systems from other jurisdictions to assess generalizability.
Comments & Academic Discussion
Loading comments...
Leave a Comment