The Dataset Nutrition Label: A Framework To Drive Higher Data Quality Standards
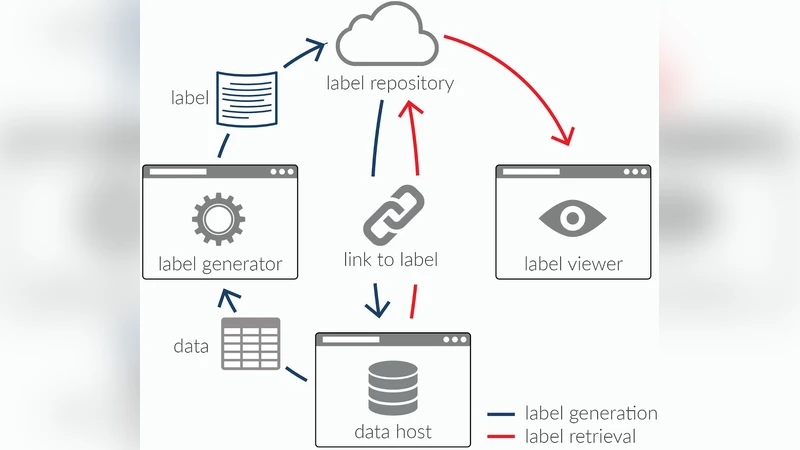
Artificial intelligence (AI) systems built on incomplete or biased data will often exhibit problematic outcomes. Current methods of data analysis, particularly before model development, are costly and not standardized. The Dataset Nutrition Label (the Label) is a diagnostic framework that lowers the barrier to standardized data analysis by providing a distilled yet comprehensive overview of dataset “ingredients” before AI model development. Building a Label that can be applied across domains and data types requires that the framework itself be flexible and adaptable; as such, the Label is comprised of diverse qualitative and quantitative modules generated through multiple statistical and probabilistic modelling backends, but displayed in a standardized format. To demonstrate and advance this concept, we generated and published an open source prototype with seven sample modules on the ProPublica Dollars for Docs dataset. The benefits of the Label are manyfold. For data specialists, the Label will drive more robust data analysis practices, provide an efficient way to select the best dataset for their purposes, and increase the overall quality of AI models as a result of more robust training datasets and the ability to check for issues at the time of model development. For those building and publishing datasets, the Label creates an expectation of explanation, which will drive better data collection practices. We also explore the limitations of the Label, including the challenges of generalizing across diverse datasets, and the risk of using “ground truth” data as a comparison dataset. We discuss ways to move forward given the limitations identified. Lastly, we lay out future directions for the Dataset Nutrition Label project, including research and public policy agendas to further advance consideration of the concept.
💡 Research Summary
The paper introduces the “Dataset Nutrition Label” (the Label), a modular diagnostic framework designed to standardize and streamline pre‑model‑development data analysis. Recognizing that AI systems inherit the biases and gaps of their training data, the authors argue that current exploratory data analysis (EDA) practices are costly, fragmented, and lack industry‑wide standards. Drawing inspiration from food nutrition labeling and privacy “nutrition labels,” the Label aggregates both qualitative and quantitative information about a dataset into a concise, standardized visual report that can be generated automatically or with minimal manual effort.
The framework is built around three guiding principles: (1) provide data specialists with rapid, actionable insights to assess dataset fitness; (2) ensure the system is flexible, extensible, and openly implementable across domains; and (3) leverage probabilistic computing back‑ends to surface hidden correlations, proxies, and anomalies that might otherwise go unnoticed. To meet these goals, the authors define a set of interchangeable “modules.” Each module can be included or omitted depending on the dataset’s characteristics and the user’s needs. The core modules demonstrated in the prototype are:
- Metadata – basic identifiers such as name, source, license, and version.
- Provenance – description of collection methods, responsible parties, and any ethical or legal considerations.
- Variables – per‑column definitions, data types, allowed ranges, and missing‑value statistics.
- Statistics – univariate summaries (mean, median, std, histograms) that give a quick sense of distribution.
- Pair Plots – bivariate visualizations that expose potential multicollinearity or unexpected relationships.
- Probabilistic Computing – Bayesian network or other probabilistic models that infer latent dependencies, flag outliers, and suggest proxy variables.
- Dataset Proxy – a privacy‑preserving summary that can stand in for proprietary data when the raw dataset cannot be released.
The prototype is applied to the publicly available ProPublica “Dollars for Docs” dataset, which records payments from pharmaceutical companies to physicians. By generating a full Label for this dataset, the authors illustrate how the framework uncovers concrete quality issues: a strong positive correlation between payment amount and physician specialty, a high missing‑rate (≈35 %) for the drug name field, and regional patterns revealed by the probabilistic module that hint at geographic bias in payment distribution. These findings demonstrate that the Label can guide data cleaning, feature selection, and bias mitigation before any model is trained.
The paper also discusses limitations. The current implementation assumes tabular CSV data under 10 k rows, leaving image, text, and large‑scale datasets unsupported. The reliance on an external “ground truth” for comparative benchmarking can be problematic when such reference data does not exist, potentially reducing the objectivity of the Label. Moreover, while the proxy module aims to protect privacy, the disclosed summary statistics could still be exploited for re‑identification attacks; the authors suggest integrating differential privacy techniques in future versions.
Future work outlined includes: (a) expanding the module library with domain‑specific templates (e.g., medical, financial, education); (b) automating the entire label generation pipeline to handle larger, more complex datasets; (c) exploring policy avenues for mandatory dataset labeling or certification to promote industry‑wide transparency; (d) extending the approach to non‑tabular data and multimodal datasets; and (e) incorporating advanced privacy‑preserving methods such as federated learning or secure multiparty computation.
In conclusion, the Dataset Nutrition Label offers a practical, scalable tool that can improve data‑driven decision making by making dataset quality assessment faster, more systematic, and more transparent. By lowering the barrier to rigorous pre‑model data inspection, it promises to reduce development costs, mitigate bias, and ultimately foster more trustworthy AI systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment