A Data-Driven Approach to Smooth Pitch Correction for Singing Voice in Pop Music
In this paper, we present a machine-learning approach to pitch correction for voice in a karaoke setting, where the vocals and accompaniment are on separate tracks and time-aligned. The network takes as input the time-frequency representation of the two tracks and predicts the amount of pitch-shifting in cents required to make the voice sound in-tune with the accompaniment. It is trained on examples of semi-professional singing. The proposed approach differs from existing real-time pitch correction methods by replacing pitch tracking and mapping to a discrete set of notes—for example, the twelve classes of the equal-tempered scale—with learning a correction that is continuous both in frequency and in time directly from the harmonics of the vocal and accompaniment tracks. A Recurrent Neural Network (RNN) model provides a correction that takes context into account, preserving expressive pitch bending and vibrato. This method can be extended into unsupervised pitch correction of a vocal performance—popularly referred to as autotuning.
💡 Research Summary
The paper introduces a machine‑learning method for continuous pitch correction of singing voice in karaoke‑style recordings, where the vocal and accompaniment tracks are provided separately and are time‑aligned. Unlike traditional real‑time pitch‑correction tools such as Auto‑Tune, which quantize the singer’s pitch to a discrete set of notes (typically the twelve‑tone equal‑tempered scale) and apply a user‑controlled “time‑lag” to smooth the correction, the proposed approach learns a direct mapping from the joint time‑frequency representation of the vocal and accompaniment to a continuous pitch‑shift value (in cents) for each audio frame.
The authors compute Constant‑Q Transforms (CQT) of both tracks with eight bins per semitone, covering frequencies up to roughly 4 kHz (the vocal track starts at 75 Hz). The two CQT spectrograms are stacked, yielding a 536‑dimensional feature vector per frame (non‑overlapping 1024‑sample frames, about 43 frames per second). For each frame a scalar label indicates how many cents the vocal should be shifted to return to the original in‑tune performance.
A recurrent neural network based on Gated Recurrent Units (GRU) is employed to predict these shift values. The authors experiment with 1–4 hidden layers and hidden sizes from 32 to 512; the best configuration reported uses four GRU layers with 128 units each. Tanh is used for the recurrent activations, sigmoid for the gates, and a linear output layer that maps the network’s –1 to 1 range back to –100 to +100 cents. Training minimizes mean‑squared error (MSE) over entire sequences using the Adam optimizer (learning rate 1e‑4) with learning‑rate annealing and early stopping. Batches consist of 32 sequences, each a randomly pitch‑shifted version of the same song, and the network processes 20‑frame overlaps, keeping only the final 20 frames for loss computation.
The dataset is derived from the SiSEC MUS collection. From the 100 multi‑track songs, the authors select 66 that contain monophonic, melodic vocal parts, discarding sections with choruses or multiple singers. For each song they generate 16 different global pitch‑shift versions of the vocal track (ranging from –100 cents to +100 cents in 12.5‑cent steps) while keeping the accompaniment fixed. Additional data augmentation is performed by applying a global transposition of up to ±4 semitones simultaneously to both vocal and accompaniment, which is trivially implemented on the CQT by vertical shifting. In total the training set comprises roughly 6 000 frames (≈25 minutes of audio) from 61 songs; the remaining 5 songs are held out for testing.
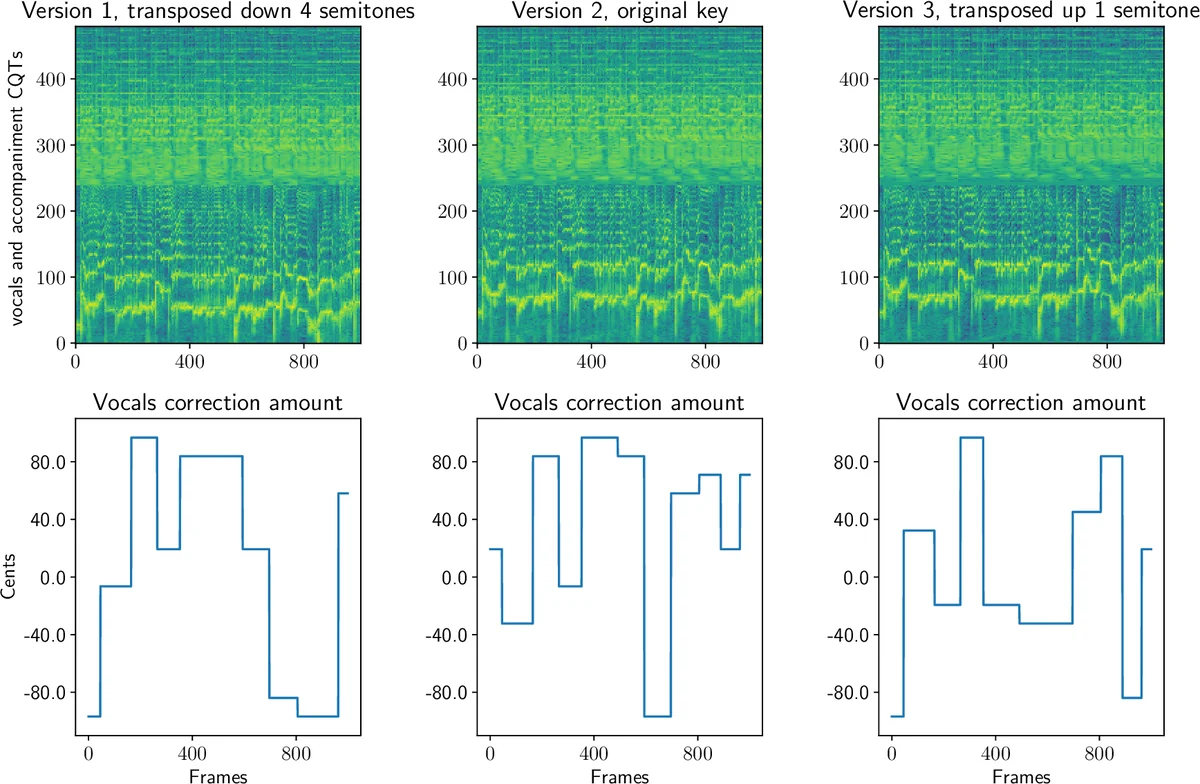
Experimental results show that models with two or more GRU layers can learn to predict reasonable correction amounts on the training songs, as illustrated in Figure 2. However, the test loss does not decrease over epochs, indicating over‑fitting and poor generalization to unseen singers, keys, or instrumentation. The authors attribute this to the limited size and heterogeneity of the dataset, the relatively short sequence lengths (maximum 2 115 frames ≈ 50 seconds), and the modest CQT resolution. They also note that the current system only outputs a scalar shift per frame; no audio synthesis (e.g., phase‑vocoding or neural vocoder) is integrated, and objective audio‑quality metrics such as SNR or perceptual scores are left for future work.
The paper’s contributions are threefold: (1) it proposes the first data‑driven approach that learns continuous pitch correction directly from vocal‑accompaniment spectral relationships, (2) it provides a publicly released annotation of the SiSEC MUS dataset for this task, and (3) it establishes a baseline GRU model that can serve as a starting point for more sophisticated architectures.
In the conclusion the authors acknowledge the current limitations—small training corpus, modest spectral resolution, and lack of end‑to‑end audio reconstruction—and outline several avenues for improvement. Future research could involve (a) assembling a larger, genre‑balanced multi‑track corpus, (b) employing higher‑resolution time‑frequency representations or raw waveform inputs, (c) exploring Transformer‑based or Conformer models to capture longer‑range musical context, and (d) integrating a neural vocoder or real‑time pitch‑shifting module to produce fully corrected audio. By addressing these points, the approach could evolve into a practical, expressive automatic tuning system applicable to a wide range of musical styles and recording conditions.
Comments & Academic Discussion
Loading comments...
Leave a Comment