OMG Emotion Challenge - ExCouple Team
The proposed model is only for the audio module. All videos in the OMG Emotion Dataset are converted to WAV files. The proposed model makes use of semi-supervised learning for the emotion recognition. A GAN is trained with unsupervised learning, with…
Authors: Ingryd Pereira, Diego Santos
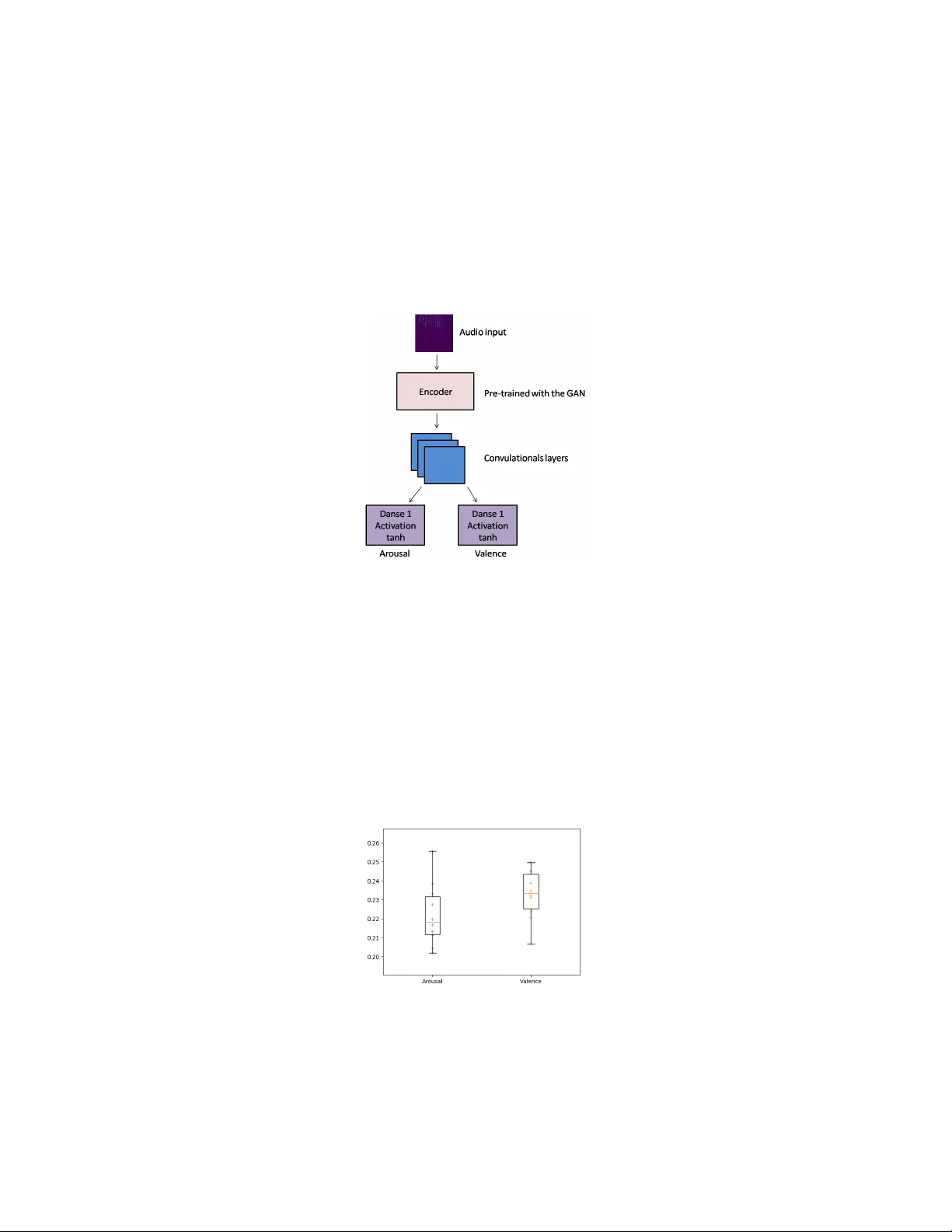
OMG Emotion Challenge - ExCouple T eam Ingryd P ereira 1 and Diego San tos 2 1 P olytechnic Sc ho ol of P ernambuco, Univ ersity of Pernam buco, Recife, Brazil 2 F ederal Universit y of P ernambuco, Recife, Brazil The prop osed model is just for the audio mo dule. The expression of emotion through the v oice is one of the essen tial forms of h uman comm unication [4]. Although the voice is a reliable affection source, recognize the affection through the v oice is a more complicated task [1, 2]. One of the c hallenges when pro cessing audio, is the representation of the audio c haracteristics. F or a long time, handmade transformations ha v e stoo d out in this area, suc h as the MFCC. But traditional feature extraction tec hniques loss to o m uc h information from the audio unlik e deep learning models which p ossible the use of the lo w est lev el of raw sp eech, lik e sp ectral characteristics, for sp eech recognition and automatically learns to mak e this transformation. Deep learning mo dels also allow the use of conv olutional and clustering op erations to represent and deal with some typical sp eech v ariabilit y (e.g., differences in vocal tract length at high-sp eak ers, differen t sp eec h st yles, etc.)[3]. But deep learning mo dels require a high num ber of lab eled training data to p erform well, and there is a scarcit y of emotional data a v ailable, whic h mak es the task of emotion recognition c hallenging. The semi-sup ervised learning can ov ercome the lack information problem of lab eled data. F or the OMG Challenge, w e use a GAN, whic h has unsup ervised learning, to learn and generate the audio represen tation and this representation will b e used as input for the model that will predict the v alues of arousal and v alence. The b enefit of using this approach is that part of the mo del that will represen t the audio can b e trained with an y database, with a m uc h larger amoun t of data, since it does not require a lab el for your training. Doing this also creates a general mo del of audio represen tation, which allow the use of the mo del in differen t tasks and differen t databases without retraining. T o develop the application used for this c hallenge, we use a BEGAN that uses an autoenco der as a discriminator. The enco der part of this autoenco der learns ho w to perform the audio represen tation. F or the BEGAN training, we use the IEMOCAP database, which is one of the largest emotional databases a v ailable. The training o ccurred in 100 ep o c hs, with batch size 16, and with a γ v alue of 0.7. W e only use the audio mo dule from the database, but all files are a v ailable in mp4 video format. So as prepro cessing the application extracts and sav es the audio from all videos in the database as W A V format. The next step is to c hange the audio frequency to 16kH. Then eac h audio trac k w as decomposed in to 1-second ch unks without ov erlapping. After that, the raw audio was con v erted to a sp ectrogram via Short Time F ourier T ransform, with an FFT of size 1024 and a length of 512. I I Figure 1 presen ts the developed mo del abstraction. The model uses the pre- pro cessed audio as input to the representation mo dule pre-trained by the BE- GAN. The encoder output is the input for a set of con v olutional la y ers follo w ed b y dense lay ers with activ ation tahn , which predicts the arousal and v alence v alues (v alues betw een -1 and 1). Fig. 1. Abstraction of the classifier and prediction mo dels In preprocessing, the application divides the audios in to 1-second pieces, per- forming the prediction for each of these pieces. But at the end of the prediction pro cess, it is necessary to gather the results from eac h part and c hec k out the v alue of arousal and v alence for whole audio. T o do this, w e use the median v alue of the predicted v alues of each 1-second part from giv en audio. The median of the set of predicted arousal v alues will be the representation of arousal of that giv en audio, and the application uses the same pro cess for v alence v alue. Fig. 2. Box plot with the CCC of the Arousal and V alence v alues predicts I II Figure 2 sho ws the b ox-plot with the predicted arousal and v alence v alues in 10 mo del runs. The base line present in Barros et al. work, [5] has a CCC better than 0.15 and v alence 0.21, and as can be seen in Figure 2, our mo del obtain b etter results. Bibliograph y [1] Liu, Mengmeng and Chen, Hui and Li, Y ang and Zhang, F engjun ”Emotional tone-based audio con tin uous emotion recognition” . International Conference on Multimedia Mo deling. Springer. 2015 [2] Sch uller, Bj¨ orn and Batliner, Anton and Steidl, Stefan and Seppi, Dino ”Recognising realistic emotions and affect in sp eech: State of the art and lessons learnt from the first challenge” . Sp eech Communication. Elsevier. 2011 [3] Deng, Li and Y u, Dong and others ”Deep learning: metho ds and applica- tions” . F oundations and T rends R in Signal Pro cessing. No w Publishers, Inc.. 2014 [4] W eninger, F elix and Eyb en, Florian and Sc h uller, Bj¨ orn W and Mortillaro, Marcello and Sc herer, Klaus R ”On the acoustics of emotion in audio: what sp eec h, music, and sound hav e in common” . F ron tiers in psyc hology . F ron tiers Media SA. 2013 [5] Barros, P ablo and Ch uramani, Nikhil and Lakomkin, Egor and Siqueira, Hen- rique and Sutherland, Alexander and W ermter, Stefan ”The OMG-Emotion Beha vior Dataset” . arXiv preprin t arXiv:1803.05434. 2018
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment