Deep Discriminant Analysis for i-vector Based Robust Speaker Recognition
Linear Discriminant Analysis (LDA) has been used as a standard post-processing procedure in many state-of-the-art speaker recognition tasks. Through maximizing the inter-speaker difference and minimizing the intra-speaker variation, LDA projects i-ve…
Authors: Shuai Wang, Zili Huang, Yanmin Qian
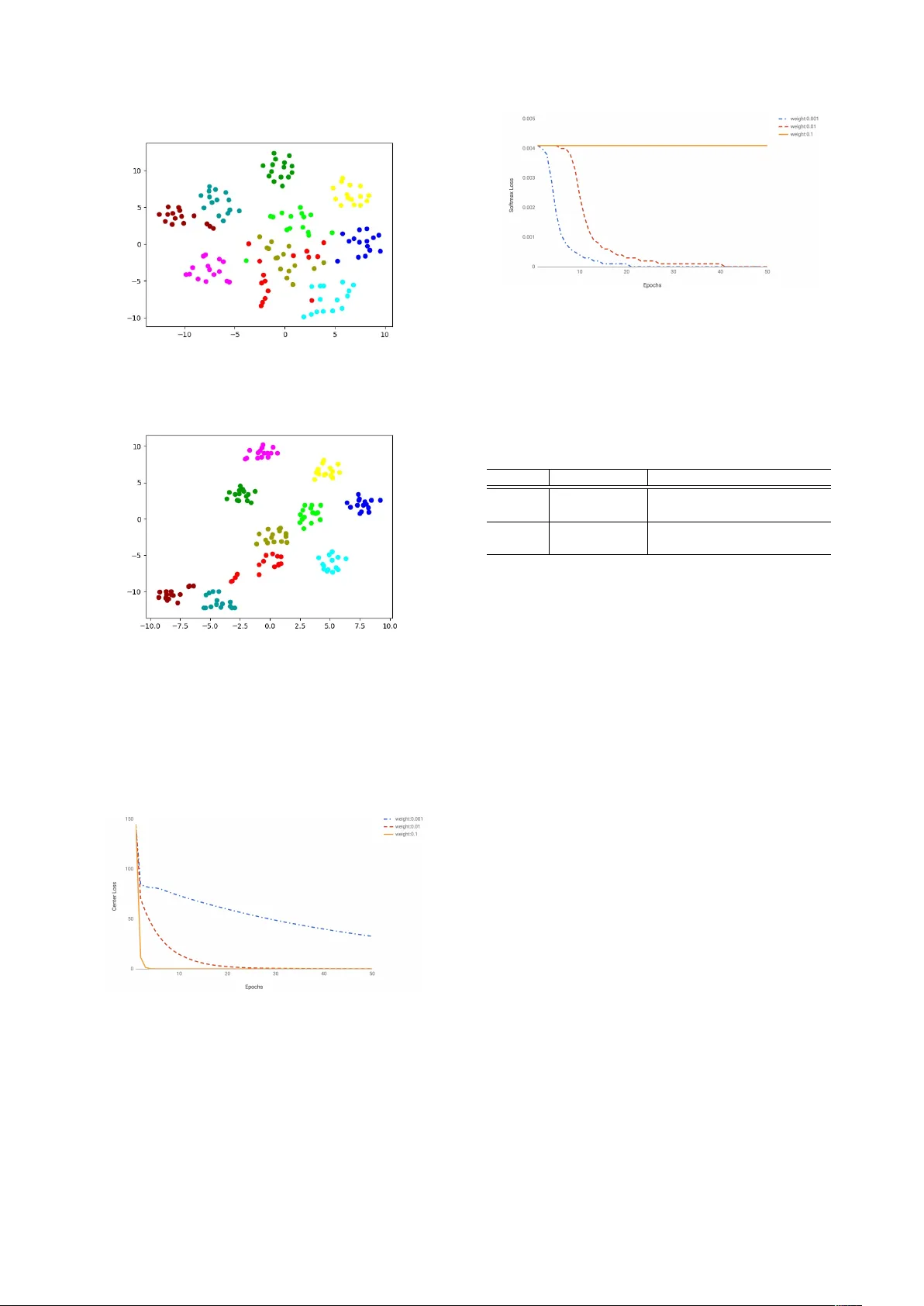
Deep Discriminant Analysis f or i-vector Based Rob ust Speaker Recognition Shuai W ang, Zili Huang, Y anmin Qian, Kai Y u K ey Laboratory of Shanghai Education Commission for Intelligent Interaction and Cogniti ve Engineering SpeechLab, Department of Computer Science and Engineering Brain Science and T echnology Research Center Shanghai Jiao T ong Univ ersity , Shanghai, China { feixiang121976,huangziliandy, yanminqian, kai.yu } @sjtu.edu.cn Abstract Linear Discriminant Analysis (LD A) has been used as a stan- dard post-processing procedure in many state-of-the-art speaker recognition tasks. Through maximizing the inter-speak er differ - ence and minimizing the intra-speaker v ariation, LD A projects i -vectors to a lower -dimensional and more discriminativ e sub- space. In this paper, we propose a neural network based com- pensation scheme(termed as deep discriminant analysis, DDA) for i -vector based speaker recognition, which shares the spirit with LD A. Optimized against softmax loss and center loss at the same time, the proposed method learns a more compact and discriminativ e embedding space. Compared with the Gaussian distribution assumption of data and the learnt linear projection in LD A, the proposed method doesn’t pose any assumptions on data and can learn a non-linear projection function. Ex- periments are carried out on a short-duration text-independent dataset based on the SRE Corpus, noticeable performance im- prov ement can be observed against the normal LD A or PLD A methods. 1. Intr oduction Speaker Recognition aims to recognize or verify a speaker’ s identity through the given speech segment. Since proposed in [1], i -vector has become the state-of-the-art speaker model- ing technique, it is a simple but eleg ant factor analysis model, inspired by the Joint Factor Analysis (JF A) [2] framew ork. Though some researchers hav e been working on improving the i -vector model itself[3, 4], more researchers pay attention to the compensation techniques in the i -vector space[5, 6, 7, 8]. JF A can be regarded as a compensation method in the GMM super-v ector space, which models the speaker and channel v ari- abilities separately . i -v ector simplifies JF A by modeling the speaker - and channel-dependent factors in a single low dimen- sional space, leaving the compensation mechanisms to the fol- lowing steps. In real applications, nuisance attributes such as channel, noise can pose a huge impact on the system perfor- mance, compensation methods become necessary and have at- tracted more and more interest. Linear Discriminant Analysis (LD A) [9, 10] is widely used in pattern recognition tasks[11, 12] to project features onto a lower -dimensional and more discriminativ e space. The trans- The corresponding author is Kai Y u This work has been supported by the National Key Research and Dev elopment Program of China under Grant No.2017YFB1002102 and the China NSFC projects (No. U1736202 and No. 61603252). Experi- ments ha ve been carried out on the PI supercomputer at Shanghai Jiao T ong University formation is learned via maximizing the between-class (inter- speaker) difference and minimizing the within-class (intra- speaker) variation. LD A is a simple linear transformation which is used as a preprocessor to generate reduced dimensional and channel compensated embeddings from the original i -v ectors in many speaker verification systems, results on standard datasets such as the Speaker Recognition Ev aluation (SRE) corpus show its effecti veness[13]. Despite its effecti veness and popularity , LD A has its limitations. For instance, LD A can provide at most C − 1 discriminant features, where C is the number of classes. It’ s a linear projection which may not be capable of dealing with highly non-linear separable data. Sev eral methods such as weighted LD A [14] and nonparametric discriminant analysis (ND A) [15, 6] are proposed as a substitution of LD A in speaker verification tasks. NDA redefines the between-class scatter ma- trix, the expected values that represent the global information about each class are replaced with local sample averages com- puted based on the k -NN of individual samples. Another most popular compensation method in the i -vector space is Proba- bilistic Linear Discriminant Analysis (PLDA) [16]. It’ s usually used as a scoring method and combined with other compen- sation methods, such as LDA. Considering different scenarios, PLD A has several variations such as two-cov ariance PLD A[17], simplified PLDA[5, 18] and Heavy-T ailed PLDA[18]. Cur- rently , the i -vector/PLD A system achieves the state-of-the-art performance. Recently , there are also some attempts using Deep Learn- ing (DL) techniques for de-noising and channel compensation in speaker recognition. This compensation can be performed in the cepstral feature space or the i -vector space. Authors in [19] used features estimated by the denoising DNN as the input to an i -vector system for channel robust speaker recognition. Au- thors in [7] proposed to use an auto-encoder to learn a projection which maps noisy i -vectors to de-noised ones. T o address the short-duration problem of i -vector[20], a Con volutional Neu- ral Network (CNN) based system was trained in [8] to map the i -vectors extracted from short utterances to the corresponding long-utterance i -vectors. In this paper , we propose a discriminative neural network (NN) based compensation method in the i -vector space. The proposed NN-based method shares the same spirit with LD A, it is trained to minimize softmax loss and center loss [21] si- multaneously , where the former forces the transformed embed- dings from dif ferent classes staying apart and the latter pulls the embeddings from the same class close to their centers. W ith the joint supervision of softmax loss and center loss, the NN produces a projection function similar to LDA, enlarging the between-class difference and reducing the within-class v aria- tion. The proposed NN-based compensation method will be referred to as Deep Discriminant Analysis (DD A) in this paper . The rest of the paper is organized as follows. Section 2 briefly introduces the i -vector framew ork. Section 3 revie ws two conv entional compensation methods in i -vector space, LD A and PLD A. W e propose the discriminati ve neural netw ork based compensation method (DDA) in Section 4, followed by exper- iments and results analysis in Section 5. Section 6 concludes this paper . 2. i -vector Joint Factor Analysis (JF A) frame work[2] was proposed as a compensation method in the GMM super-vector space, it mod- els speaker and channel factors in separate subspaces. The fol- lowing i -vector simplifies the JF A framework by modeling a single total variability subspace[1]. In the i -vector framew ork, the speaker- and session-dependent super-v ector M (derived from UBM) is modeled as M = m + Tx + (1) where m is a speaker and session-independent super-vector , T is a lo w rank matrix which captures speaker and session vari- ability , x ∼ N ( 0 , I ) , is a multi variate random variable, and the termed i -vector is the posterior mean of x . ∼ N ( 0 , I ) , is the residual noise term to account for the variability not captured by T . As sho wn in Equation1, i -v ector is a simple and elegant rep- resentation, which follows the standard Factor Analysis (F A) scheme. Howe ver , since i -vector contains the speaker - and channel-dependent factors in the same subspace, further chan- nel compensation methods such as LDA are often applied to annihilate the impact of nuisance attributes. 3. Con ventional Compensation Methods Speaker recognition systems are fragile to noise, channel and many other factors. Compensation technologies hav e been heavily researched on during the past several decades. In this section, we mainly discuss the compensation methods in the i - vector space. T wo methods, LD A and PLD A will be specifically introduced. 3.1. Linear Discriminativ e Analysis (LDA) LD A is widely used in pattern recognition tasks such as image recognition[11] and speaker recognition[13]. LDA calculates a matrix W that projects high dimensional feature vectors x ( i -vectors in this paper) into a lo wer-dimensional and more dis- criminativ e subspace ( W : R h 7→ R l ). The projection can be represented as: y = W T x (2) where y denotes the compensated embedding and W is a rect- angular matrix of shape h × l . W is determined by ˆ W = arg max W tr ( W T S b W ) tr ( W T S w W ) (3) = arg max W T S w W = I [ tr ( W T S b W )] (4) The between-class and within-class covariance matrices, S b and S w respectiv ely , can be computed as S b = 1 N S X s =1 N s ( µ s − µ )( µ s − µ ) T (5) S w = 1 N S X s =1 N s X i =1 ( x i s − µ s )( x i s − µ s ) T (6) where S represents the total number of speakers, N represents the total number of i -vectors from all speak ers. µ represents the global mean of all N i -vectors, whereas µ s represents the mean of i -vectors from the specific s -th speak er . x i s represents the i -th i -vector from the s -th speaker, N s is the number of utterances from the s -th speaker . LD A has an analytical solution and the optimized ˆ W is a matrix whose columns are the l eigenv ectors corresponding to the largest eigenv alues of S − 1 w S b . Howe ver , despite its simple- ness and effecti veness, LD A has se veral limitations, • The within- and between-class matrices are formed based on Gaussian assumptions for samples of each class. If the Gaus- sian assumption doesn’t hold, LD A is not able to learn a effec- tiv e enough projection function for classification problems. • LDA suffers from the “small sample size” problem, which leads to the singularity of the within-class scatter matrix S w . This problem happens when the number of the samples is much smaller than the dimension of the original samples. • Given the class number C , LD A can provide at most C − 1 discriminant features, since the between-class scatter matrix S b has of rank of C − 1 . Howe ver , this may not be suf ficient for tasks in which the class number is much smaller than the dimension of input features. • LDA learns a linear projection function, which may not be enough for data that are highly linearly inseparable. T o address these limitations of LD A, sev eral approaches are proposed. For instance, a nonparametric was proposed in [15] and applied to rob ust speaker v erification [6, 13]. In ND A, instead of only considering the class center when computing the between-class scatter matrix, the global information about a class is defined with local sample averages computed based on the k -NN of individual samples. Researchers also proposed sev eral approaches to tackle the “small sample size” problem [22, 23]. 3.2. Probabilistic Linear Discriminant Analysis i -vectors with Probabilistic Linear Discriminant Analysis (PLD A) back-end obtains the state-of-the-art performance in speaker v erification. Several variants of PLD A ha ve been intro- duced into the speaker verification task, including the standard PLD A[16], two-cov ariance PLD A[17], heavy-tailed PLDA[18] and the Simplified PLD A[5, 18]. The optimization goal of all v ariants is to maximize the between-class difference and minimize the within-class variation. PLD A models regard i - vectors as observations from a probabilistic generative model and can be seen as a factor analysis in the i -vector space. In our e xperimental settings, the variant implemented in Kaldi[24] achiev es best performance, which we termed as Kaldi-PLD A here, it’ s following the formulations in [25] and similar to the two-cov ariance model. In the Kaldi-PLD A, an i -vector x is assumed to be gener- ated as, x = µ + Au (7) u ∼ N ( v , I ) (8) v ∼ N ( 0 , Ψ ) (9) where v represents the class (speaker), and u represents a sample of that class in the projected space. Kaldi-PLD A is trained using EM algorithm, training and inference details can be found in [25] or the Kaldi project[24]. In the following sec- tions, Kaldi-PLD A will be simply referred to as PLD A. 4. Neural Network based Appr oach 4.1. Center Loss Neural networks hav e been inv estigated a lot in areas such as image recognition, speech recognition[26, 27, 28] and speaker recognition[3, 29, 30]. One of the most popular method is to treat the neural network as a feature extractor , whereas the learned features are called “bottle-neck feature” or “deep feature”[31, 32, 33, 34, 35]. For instance, in speaker recogni- tion, researchers proposed to extract feature vectors from the last hidden layer of a well-trained speaker-discriminati ve DNN. In most work, the DNN is optimized against the softmax loss, which emphasizes on discriminating different speak ers. The softmax loss function is defined as L S = − N X i =1 log e W T s i x i + b s i P S j =1 e W T j x i + b j (10) where N is the total number of training samples ( i -vectors), x i denotes the i -th sample, belonging to the s i -th class. S is the number of softmax outputs, representing S different classes. W is the projection weight matrix and b is the corresponding bias term. Center loss [21] is formulated as L C = 1 2 N X i =1 || x i − c s i || 2 (11) where c s i represents the center of s i -th class (which the i -th sample belongs to) and is updated along with the training pro- cedure. The neural network will be trained under the joint su- pervision of softmax loss and center loss, formulated as, L = L S + λ L C (12) where λ is adopted for balancing the two loss functions. Intu- itiv ely , the softmax loss forces the learned embeddings of dif- ferent classes staying apart, while the center loss pulls the em- beddings from the same class close to their centers. W ith the joint supervision of softmax loss and center loss, the neural net- work learns a projection function similar to LD A, enlarging the inter-class dif ferences and reducing the intra-class v ariations. T o show the effectiv eness of center loss, follo wing the ap- proach in [21], we also train a toy example on a small speaker audio dataset, which contains 10 different speakers. A 2-layer neural network is trained and the dimension of embedding layer is set as 2 for illustration. As sho wn in Fig.1 and Fig.2 ( Best viewed in color ), with the assistance of center loss, the within- class variation reduced a lot. In the following experiments, it can be seen that this property can be generalized to scenar- ios where validation speakers hav e no overlap with the training speakers, which is the common condition in speaker verifica- tion. Figure 1: Embeddings supervised by softmax loss Figure 2: Embeddings supervised by softmax + center loss 4.2. Deep Discriminant Analysis Deep Neural Network (DNN) shows its extraordinary capa- bility in speech recognition and speaker recognition, there is no prior assumption on the input data. Through substitut- ing Gaussian Mixture Model (GMM) to DNN[26], the DNN- HMM systems achieve noticeable performance improv ement compared to traditional GMM-HMM systems, which also holds for speaker recognition tasks when updating GMM- i -vector to DNN- i -vector[3]. In this section, a DNN is used to perform the channel compensation in the i -vector space. The whole archi- tecture is depicted in Fig.3. In the training phase, the extracted i - vector from dif ferent speakers are prepared as input, the DNN is joint supervised by the softmax loss and the center loss. The last layer before the loss layer is an embedding layer , from which we extract the transformed embeddings. In the compensation stage, the source i -vectors are mapped to their corresponding transformed version through the trained neural network. Simi- lar to the projection in Equation 2, gi ven the original i -v ector x , the compensated lo wer-dimensional embedding y can be repre- sented as y = G ( x ) (13) where G () denotes the nonlinear transformation function learned by the NN through the training data. W e term this NN-based compensation method as Deep Discriminant Anal- ysis (DD A), for comparison with LD A or ND A. Hidden L ayer s Embeddi ng Layer Center Loss Soft max Loss i- vect ors Tr aining T rans form ed i- vect ors Compe nsation Figure 3: Architecture of DDA 5. Experiments 5.1. Dataset W e e valuate the performance of our proposed methods on a short-duration dataset generated from the NIST SRE corpus. This short duration text-independent task is more difficult for speaker verification. The training set consists of selected data from SRE 04 - 08 , Switchboard II phase 2 , 3 and Switchboard Cellular Part 1 , Part 2 . After removing silence frames using an energy-based V AD, the utterances are chopped into short seg- ments (ranging from 3 - 5 s). The final training set contains 4000 speakers and each speaker has 40 short utterances. The enroll- ment set and test set are derived from NIST SRE 2010 follo wing a similar procedure. The enrollment set contains 300 speakers ( 150 males and 150 females) and each speaker is enrolled by 5 utterances. The test set contains 4500 utterances from the 300 models in the enrollment set. The trial list we create contains 392660 trials. There are 15 positive samples and 1294 nega- tiv e samples on average for each model. No cross-gender trial exists. 5.2. System Details 5.2.1. Baseline Settings The baseline i -vector system is implemented using the Kaldi toolkit, 20-dimensional MFCC coefficients with their first and second order deri vati ves are extracted from the speech segments (identified with an energy based V AD). A 25 ms Hamming win- dow with a 10 ms frame shift is adopted in the feature extrac- tion process. The universal background model (UBM) contains 2048 Gaussian mixtures and the i -vector dimension is set to 600. Different scoring methods are applied to the length nor- malized i -vectors. 3 different scoring methods are adopted to ev aluate the performance. Cos denotes the cosine similarity of two vectors, while Euc denotes the Euclidean Distance. As shown in T able 2, PLDA achie ves best performance for the raw input i -vectors with a EER of 4.96%, since PLDA itself is both a compensation and scoring method. LD A ’ s dimension in T able 2 is set as 300 and obtains significant performance improv e- ment when applied to Cos or Euc scoring methods. Howe ver , no improv ement is observed when combining LD A and PLD A. 5.2.2. Neural Network Settings As shown in T able 1, we adopt a standard feed-forward neural network as the compensation model, which contains one input layer , one hidden layer and one embedding layer . PReLU[36] is chosen as the activ ation function, while a batch normalization layer is added before the embedding layer to stabilize the train- ing procedure. The whole network is trained under the joint supervision of softmax loss and center loss, with the value of λ in Equation 12 set as 0.01 (Detailed explanation of this setting can be found in Section 5.3.1). Follo wing the strategy used in [21], besides the λ to balance the impact of two losses, a dif- ferent learning rate is used for the center loss parameters. The learning rate for the basic neural network is set to 0.01 and the one for center loss is set to 0.1. In the training stage, since it’ s impractical to update the centers with respect to the whole train- ing set, we update the centers per mini-batch instead, centers are computed by averaging the embeddings of corresponding classes (centers of some classes may not be updated). T able 1: Neural Network Configuration Input Source i -vectors of 600 dimension Linear Layers number of nodes nonlinear Input Layer 600 PReLU Hidden Layer 600 PReLU + BatchNorm Embedding Layer 300 None Loss softmax loss 0.01 * center loss 5.3. Results and Analysis The proposed neural network based system is ev aluated on the dataset described in Section 5.1. As shown in T able 2, com- pared to LDA, the NN-based DDA obtains larger improvement for Cos and Euc scoring methods, while the best performance of EER 4.69% is achiev ed by DDA+Euc, which also outperforms the baseline PLDA system. Ho we ver , the proposed compen- sation method is not compatible with PLD A. T o better under- stand the proposed method’ s effect, we use t-SNE[37] to visu- alize the i -vectors and their corresponding DD A-compensated embeddings in Fig.4 and Fig.5 ( Best viewed in color ). T able 2: EER (%) of dif ferent compensation methods Methods Cos Euc PLD A Baseline 7.29 6.04 4.96 LD A 5.89 5.22 5.0 DD A 4.78 4.69 7.32 Fig.4 depicts the distribution of i -vectors from 10 speak- ers randomly chosen from the test set, while the distribution of corresponding compensated embeddings are shown in Fig.5. As shown in the two figures, with the proposed compensation method, the distribution of embeddings from the same speaker seems more compact, which means the intra-speaker variation is significantly reduced. 5.3.1. Impact of the loss weight As mentioned in above sections, a weight λ is used to balance the softmax loss and center loss. A small λ implies a strong su- pervision signal provided by the softmax loss, whereas a large λ implies a strong supervision signal from the center loss. As shown in Fig.6 and Fig.7, when the weight is set to 0.1, the net- work is actually not trainable, though the center loss degrades quickly , the softmax loss hardly change. In this case, the em- beddings are trained to be similar to each other and became not Figure 4: V isualization of i -vectors Figure 5: V isualization of compensated embeddings distinguishable. As the value of λ is reduced, the softmax loss degrades faster due to its relativ ely stronger supervision sig- nal. In our experiments, when λ varies from 0.001 to 0.01, the training conv erges faster , while the compensation performance hardly changes. Figure 6: Center Loss with the training epochs 5.3.2. Impact of the embedding dimension In this section, we in vestigated the impact of dif ferent dimen- sions of the projection subspace by varying the embedding layer’ s dimension. As shown in T able 3, it’ s interesting to find that DDA achiev es best performance with 400 dimension, in Figure 7: Softmax Loss with the training epochs contrary , LDA achiev es best performance with 200 dimension. Though not listed in the following table, it should be mentioned that with the dimension of 100 or 500 which are not listed, the EER increases for both two compensation methods. T able 3: EER (%) comparison Scoring Compensation 200dim 300dim 400dim Cos LD A 5.53 5.89 6.28 DD A 5.31 4.78 4.67 Euc LD A 5.22 5.22 5.40 DD A 5.08 4.69 4.51 6. Conclusion Intra-speaker v ariability compensation techniques such as LD A hav e been researched a lot in the state-of-the-art i -vector frame- work, LD A has sev eral limitations dual to the mismatch be- tween LD A ’ s assumptions and the true distribution of i -v ectors. In this paper , we proposed a non-linear compensation frame- work based on a discriminati ve neural network, termed as DD A (Deep Discriminant Analysis). The neural network is trained under the joint supervision of softmax loss and center loss, the softmax loss forces the learned embeddings of different classes staying apart, while the center loss pulls the embeddings from the same class close to their centers. Experiments shows that with the assistance of the proposed compensation method, sim- ple Cosine Scoring or Euclidean Scoring can achieve ev en better performance than PLD A. 7. Refer ences [1] Najim Dehak, Patrick J Kenny , R ´ eda Dehak, Pierre Du- mouchel, and Pierre Ouellet, “Front-end factor analysis for speaker verification, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , v ol. 19, no. 4, pp. 788– 798, 2011. [2] Patrick Kenn y , “Joint factor analysis of speaker and ses- sion variability: Theory and algorithms, ” CRIM, Mon- tr eal,(Report) CRIM-06/08-13 , 2005. [3] Y un Lei, Nicolas Scheffer , Luciana Ferrer, and Mitchell McLaren, “ A nov el scheme for speaker recognition using a phonetically-aware deep neural network, ” in Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE In- ternational Confer ence on . IEEE, 2014, pp. 1695–1699. [4] W ei Rao, Man-W ai Mak, and Kong-Aik Lee, “Normal- ization of total v ariability matrix for i-vector/plda speaker verification, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE International Confer ence on . IEEE, 2015, pp. 4180–4184. [5] Daniel Garcia-Romero and Carol Y Espy-W ilson, “ Analy- sis of i-v ector length normalization in speak er recognition systems, ” in T welfth Annual Confer ence of the Interna- tional Speec h Communication Association , 2011. [6] Seyed Omid Sadjadi, Jason Pelecanos, and W eizhong Zhu, “Nearest neighbor discriminant analysis for robust speaker recognition, ” in F ifteenth Annual Confer ence of the International Speech Communication Association , 2014. [7] Shiv angi Mahto, Hitoshi Y amamoto, and T akafumi K oshi- naka, “I-vector transformation using a novel discrimina- tiv e denoising autoencoder for noise-robust speaker recog- nition, ” Proc. Interspeech 2017 , pp. 3722–3726, 2017. [8] Jinxi Guo, Usha Amrutha Nookala, and Abeer Alwan, “Cnn-based joint mapping of short and long utterance i- vectors for speaker verification using short utterances, ” Pr oc. Inter speech 2017 , pp. 3712–3716, 2017. [9] Suresh Balakrishnama and Aravind Ganapathiraju, “Lin- ear discriminant analysis-a brief tutorial, ” Institute for Sig- nal and information Pr ocessing , vol. 18, pp. 1–8, 1998. [10] Nasser M Nasrabadi, “Pattern recognition and machine learning, ” Journal of electr onic imaging , vol. 16, no. 4, pp. 049901, 2007. [11] Peter N. Belhumeur, Jo ˜ ao P Hespanha, and David J. Kriegman, “Eigenfaces vs. fisherfaces: Recognition us- ing class specific linear projection, ” IEEE T ransactions on pattern analysis and mac hine intelligence , vol. 19, no. 7, pp. 711–720, 1997. [12] Reinhold Haeb-Umbach and Hermann Ney , “Linear dis- criminant analysis for improv ed lar ge vocab ulary continu- ous speech recognition, ” in Acoustics, Speec h, and Signal Pr ocessing, 1992. ICASSP-92., 1992 IEEE International Confer ence on . IEEE, 1992, v ol. 1, pp. 13–16. [13] Seyed Omid Sadjadi, Sriram Ganapathy , and Jason W Pelecanos, “The ibm 2016 speaker recognition system, ” arXiv pr eprint arXiv:1602.07291 , 2016. [14] Ahilan Kanagasundaram, David Dean, Robbie V ogt, Mitchell McLaren, Sridha Sridharan, and Michael Ma- son, “W eighted lda techniques for i-vector based speaker verification, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2012 IEEE International Confer ence on . IEEE, 2012, pp. 4781–4784. [15] K Fukunaga and JM Mantock, “Nonparametric discrim- inant analysis, ” IEEE T ransactions on P attern Analysis and Mac hine Intelligence , , no. 6, pp. 671–678, 1983. [16] Simon JD Prince and James H Elder, “Probabilistic lin- ear discriminant analysis for inferences about identity , ” in Computer V ision, 2007. ICCV 2007. IEEE 11th Interna- tional Confer ence on . IEEE, 2007, pp. 1–8. [17] Niko Br ¨ ummer and Edward De V illiers, “The speaker par- titioning problem., ” in Odyssey , 2010, p. 34. [18] Patrick K enny , “Bayesian speaker verification with heavy- tailed priors., ” in Odyssey , 2010, p. 14. [19] Frederick S Richardson, Douglas A Reynolds, and Brian Nemsick, “Channel compensation for speaker recognition using map adapted plda and denoising dnns, ” T ech. Rep., MIT Lincoln Laboratory Lexington United States, 2016. [20] Ahilan Kanagasundaram, Robbie V ogt, David B Dean, Sridha Sridharan, and Michael W Mason, “I-vector based speaker recognition on short utterances, ” in Pr oceedings of the 12th Annual Conference of the International Speech Communication Association . International Speech Com- munication Association (ISCA), 2011, pp. 2341–2344. [21] Y andong W en, Kaipeng Zhang, Zhifeng Li, and Y u Qiao, “ A discriminative feature learning approach for deep face recognition, ” in Eur opean Confer ence on Computer V i- sion . Springer , 2016, pp. 499–515. [22] Rui Huang, Qingshan Liu, Hanqing Lu, and Songde Ma, “Solving the small sample size problem of lda, ” in P at- tern Recognition, 2002. Pr oceedings. 16th International Confer ence on . IEEE, 2002, v ol. 3, pp. 29–32. [23] Alok Sharma and Kuldip K Paliwal, “Linear discriminant analysis for the small sample size problem: an overvie w , ” International Journal of Machine Learning and Cybernet- ics , vol. 6, no. 3, pp. 443–454, 2015. [24] Daniel Pove y , Arnab Ghoshal, Gilles Boulianne, Lukas Burget, Ondrej Glembek, Nagendra Goel, Mirko Hanne- mann, Petr Motlicek, Y anmin Qian, Petr Schwarz, et al., “The kaldi speech recognition toolkit, ” in IEEE 2011 workshop on automatic speech r ecognition and under- standing . IEEE Signal Processing Society , 2011. [25] Sergey Ioffe, “Probabilistic linear discriminant analysis, ” in Eur opean Confer ence on Computer V ision . Springer , 2006, pp. 531–542. [26] Geoffrey Hinton, Li Deng, Dong Y u, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly , Andrew Se- nior , V incent V anhoucke, Patrick Nguyen, T ara N Sainath, et al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups, ” IEEE Signal Processing Magazine , vol. 29, no. 6, pp. 82–97, 2012. [27] George E Dahl, Dong Y u, Li Deng, and Alex Acero, “Context-dependent pre-trained deep neural networks for large-v ocabulary speech recognition, ” IEEE T ransactions on audio, speec h, and language pr ocessing , v ol. 20, no. 1, pp. 30–42, 2012. [28] Frank Seide, Gang Li, and Dong Y u, “Con versational speech transcription using context-dependent deep neural networks, ” in T welfth Annual Confer ence of the Interna- tional Speec h Communication Association , 2011. [29] Georg Heigold, Ignacio Moreno, Samy Bengio, and Noam Shazeer , “End-to-end text-dependent speaker verifica- tion, ” in IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP), 2016 . IEEE, 2016, pp. 5115–5119. [30] David Snyder , Pegah Ghahremani, Daniel Pove y , Daniel Garcia-Romero, Y ishay Carmiel, and Sanjee v Khudanpur , “Deep neural netw ork-based speak er embeddings for end- to-end speaker verification, ” in Spoken Language T echnol- ogy W orkshop (SLT), 2016 IEEE . IEEE, 2016, pp. 165– 170. [31] Zhizheng W u, Cassia V alentini-Botinhao, Oliver W atts, and Simon King, “Deep neural networks employing multi-task learning and stacked bottleneck features for speech synthesis, ” in Acoustics, Speech and Signal Pr o- cessing (ICASSP), 2015 IEEE International Confer ence on . IEEE, 2015, pp. 4460–4464. [32] Dong Y u and Michael L Seltzer , “Improv ed bottle- neck features using pretrained deep neural networks, ” in T welfth Annual Conference of the International Speech Communication Association , 2011. [33] Ehsan V ariani, Xin Lei, Erik McDermott, Ignacio Lopez Moreno, and Ja vier Gonzalez-Dominguez, “Deep neural networks for small footprint text-dependent speaker veri- fication, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2014, pp. 4052–4056. [34] Y uan Liu, Y anmin Qian, Nanxin Chen, Tianfan Fu, Y a Zhang, and Kai Y u, “Deep feature for text-dependent speaker verification, ” Speech Communication , vol. 73, pp. 1–13, 2015. [35] Nanxin Chen, Y anmin Qian, and Kai Y u, “Multi-task learning for text-dependent speaker verification, ” in Six- teenth Annual Conference of the International Speech Communication Association , 2015. [36] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Delving deep into rectifiers: Surpassing human- lev el performance on imagenet classification, ” in Pr oceed- ings of the IEEE international confer ence on computer vi- sion , 2015, pp. 1026–1034. [37] Laurens van der Maaten and Geoffre y Hinton, “V isual- izing data using t-sne, ” Journal of machine learning re- sear ch , v ol. 9, no. Nov , pp. 2579–2605, 2008.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment