Use Cases of Computational Reproducibility for Scientific Workflows at Exascale
We propose an approach for improved reproducibility that includes capturing and relating provenance characteristics and performance metrics, in a hybrid queriable system, the ProvEn server. The system capabilities are illustrated on two use cases: scientific reproducibility of results in the ACME climate simulations and performance reproducibility in molecular dynamics workflows on HPC computing platforms.
💡 Research Summary
The paper presents a novel approach to improve computational reproducibility for scientific workflows operating at exascale, centered on a hybrid, queryable system called the ProvEn server. The authors argue that reproducibility—both of scientific results and of performance—is increasingly difficult to achieve on modern high‑performance computing (HPC) platforms because of the sheer number of variables that affect an experiment: hardware architecture, operating system, compiler versions, library stacks, input datasets, and configuration parameters. These variables evolve rapidly in DOE Leadership Class Facilities, and multi‑threaded execution can introduce nondeterministic behavior that further complicates the picture.
ProvEn addresses these challenges by automatically harvesting provenance information (e.g., Git hash of the code, compiler flags, environment variables, node and core counts, file lists, job scripts) and performance metrics (e.g., I/O statistics, memory‑access patterns, network utilization) at runtime, converting them into a unified schema, and storing them in a hybrid database that supports both relational and graph queries. Users can then issue complex queries that combine provenance and performance data, enabling precise reconstruction of past runs or systematic comparison of parameter sweeps.
Two concrete use cases illustrate the system’s capabilities. The first involves the Accelerated Climate Modeling for Energy (ACME) project, a globally distributed climate‑modeling effort that runs massive simulations on multiple supercomputers. Historically, ACME’s execution metadata were kept in scattered, manually maintained documents, leading to missing or inconsistent information. By adopting a standardized “run_acme” wrapper script that feeds all relevant metadata into ProvEn, the team achieved automated, complete capture of every run. This enables exact recreation of previous experiments, rapid identification of successful configuration patterns, and robust verification of model outputs—critical for a domain where scientific credibility and policy relevance depend on data verifiability.
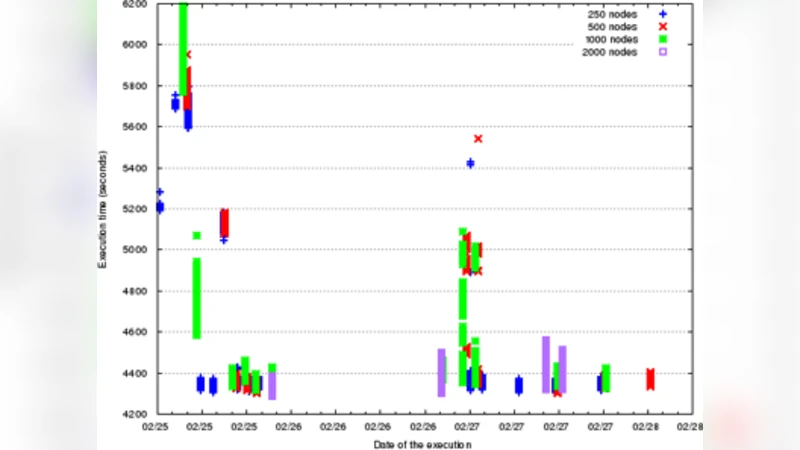
The second use case examines performance reproducibility in two large‑scale workflows: a molecular dynamics (MD) ensemble using GROMACS and a high‑energy physics workflow composed of AthenaMP tasks. Despite being designed with identical tasks, the total time‑to‑completion (TTC) varied significantly across runs. ProvEn’s performance‑aware provenance allowed the authors to correlate TTC fluctuations with specific system‑level factors such as filesystem contention, memory page swapping, and scheduling order on multi‑core nodes. The analysis revealed that while I/O bottlenecks contributed to variability, they were not the sole cause; subtle interactions between the OS scheduler and the application’s threading model also played a role.
Beyond the case studies, the authors propose that workflow management systems should embed reproducibility requirements directly into task specifications, prompting automatic provenance capture as an integral step rather than an afterthought. They also suggest a tiered view of reproducibility—ranging from “blanket” reproducibility (full capture of all variables) to “pragmatic” reproducibility (capturing only the most influential factors)—to balance cost and benefit.
In summary, the ProvEn framework demonstrates that systematic, automated provenance and performance data collection can dramatically improve both scientific and performance reproducibility on exascale platforms. By providing a unified, queryable repository of execution context, ProvEn enables researchers to validate results, diagnose performance anomalies, and make informed decisions about workflow design, ultimately strengthening the credibility and efficiency of large‑scale scientific computing.
Comments & Academic Discussion
Loading comments...
Leave a Comment