Predicting language diversity with complex network
Evolution and propagation of the world’s languages is a complex phenomenon, driven, to a large extent, by social interactions. Multilingual society can be seen as a system of interacting agents, where the interaction leads to a modification of the language spoken by the individuals. Two people can reach the state of full linguistic compatibility due to the positive interactions, like transfer of loanwords. But, on the other hand, if they speak entirely different languages, they will separate from each other. These simple observations make the network science the most suitable framework to describe and analyze dynamics of language change. Although many mechanisms have been explained, we lack a qualitative description of the scaling behavior for different sizes of a population. Here we address the issue of the language diversity in societies of different sizes, and we show that local interactions are crucial to capture characteristics of the empirical data. We propose a model of social interactions, extending the idea from, that explains the growth of the language diversity with the size of a population of country or society. We argue that high clustering and network disintegration are the most important characteristics of models properly describing empirical data. Furthermore, we cancel the contradiction between previous models and the Solomon Islands case. Our results demonstrate the importance of the topology of the network, and the rewiring mechanism in the process of language change.
💡 Research Summary
The paper investigates how the diversity of languages scales with the size of a human population by employing a co‑evolving complex‑network model of social interactions. Each individual (node) is characterized by a vector of F linguistic traits, each of which can take one of q discrete values, yielding q^F possible language states. Simulations start from a random graph with N nodes and a prescribed average degree ⟨k⟩, with traits assigned uniformly at random.
At each discrete time step an active node i selects a neighbor j. The number m of identical traits between i and j is counted. If m = F the agents are already identical and nothing happens. If m = 0 the languages share no common trait; the edge (i, j) is removed and i creates a new link to a node that is at distance two (a neighbor‑of‑a‑neighbor). This “local rewiring” can be performed either with uniform probability over the candidate set or with preferential attachment proportional to (k + 1)^2. If 0 < m < F, a positive interaction occurs with probability m/F: i randomly adopts one of the traits it does not share from j. The process repeats until a frozen configuration or a thermalized state is reached.
The authors identify three distinct phases as the parameter q varies. For small q the system quickly converges to a single language covering the whole, connected network (phase 1). For intermediate q the network fragments into many small components, each internally homogeneous but mutually different (phase 2). For large q a partial recombination appears: some links survive between agents speaking different languages (phase 3). The authors argue that phase 2 best captures real‑world language diversity because it combines high clustering, network disintegration, and a multiplicity of distinct language domains.
A central result is that the number of language domains (i.e., distinct languages) grows with the system size N when the rewiring is local. Simulations with both uniform and preferential rewiring show a clear positive scaling, in contrast to earlier static‑lattice models that predicted a decrease, and to earlier adaptive models that yielded size‑independent domain counts. This scaling aligns with empirical observations from the Solomon Islands, where the number of languages increases with island area.
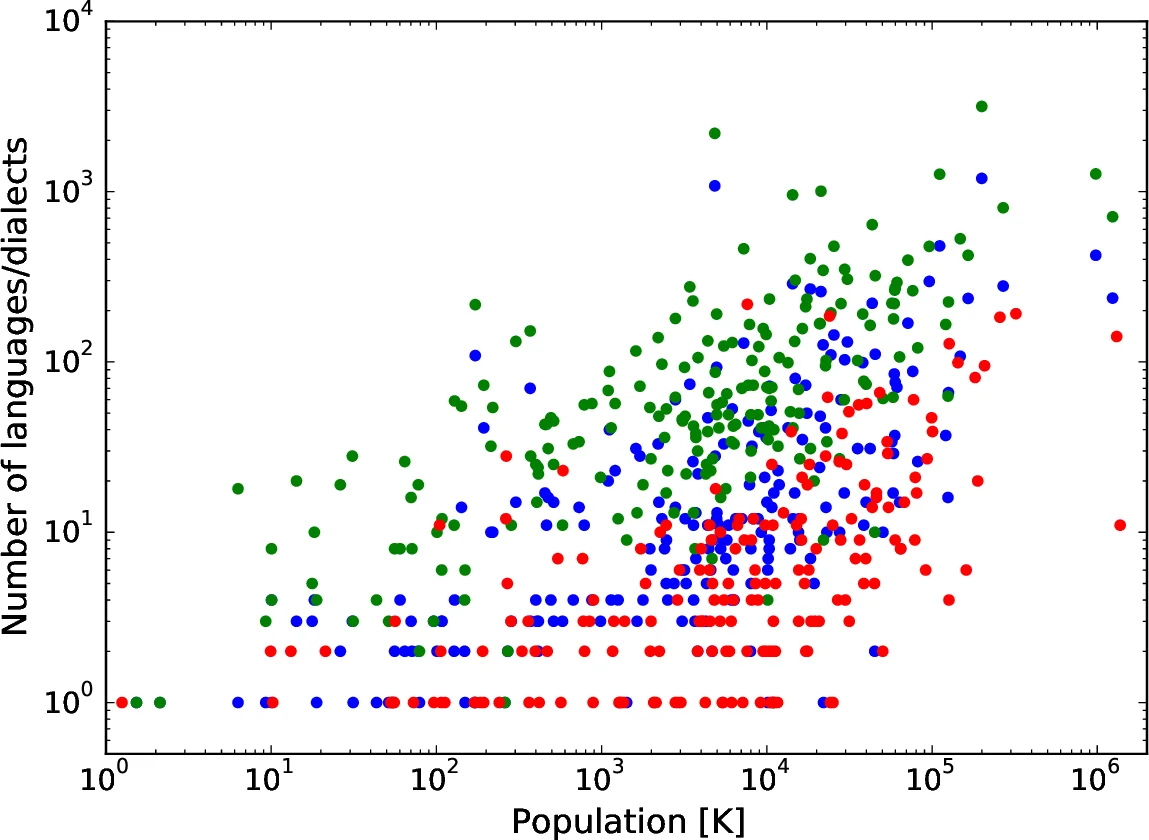
To validate the model, the authors analyze two large linguistic databases: Ethnologue (1996) with 6 866 languages and 9 130 dialects across 209 countries, and WALS (2013) with 2 679 languages across 188 countries. Population figures are taken from UN World Population Prospects (2015). Plotting language count versus national population reveals an overall upward trend, though noisy due to outliers such as China, India, Indonesia, and Papua New Guinea. After excluding these extreme cases and aggregating countries into population bins, the positive correlation becomes pronounced, especially for dialect counts. The simulated scaling curves qualitatively match these empirical trends.
The paper emphasizes that merely modeling agents’ internal states is insufficient; the topology and its evolution are crucial. Local rewiring naturally raises the clustering coefficient, reproducing the high triangle density observed in real social networks, and simultaneously drives network fragmentation, both of which are essential for matching real language‑diversity data.
Limitations are acknowledged: the trait‑value abstraction may oversimplify real linguistic structure; non‑social factors (policy, colonization, wars, epidemics) are omitted; and the specific rule of connecting only to second‑order neighbors may not capture all migration or contact patterns. Nonetheless, the study demonstrates that a simple co‑evolving network with high clustering and fragmentation can explain the observed scaling of language diversity with population size. Future work is suggested to incorporate additional sociocultural variables, multi‑language competence, and empirical social‑network data for finer validation.
Comments & Academic Discussion
Loading comments...
Leave a Comment