A Feature Selection Method Based on Shapley Value to False Alarm Reduction in ICUs, A Genetic-Algorithm Approach
High false alarm rate in intensive care units (ICUs) has been identified as one of the most critical medical challenges in recent years. This often results in overwhelming the clinical staff by numerous false or unurgent alarms and decreasing the qua…
Authors: Mohammad Zaeri-Amirani, Fatemeh Afghah, Sajad Mousavi
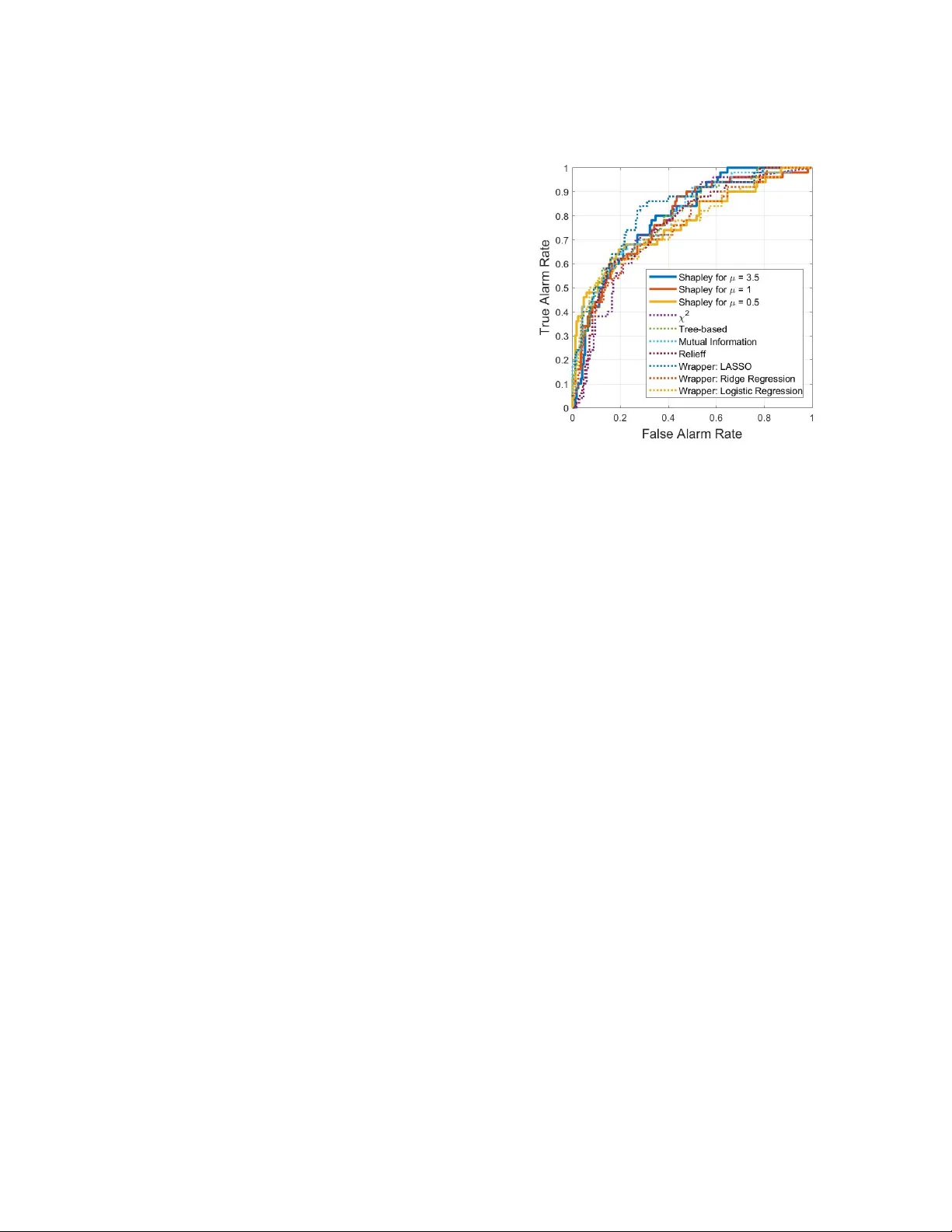
1 A Feature Selection Method Based on Shaple y V alue to F alse Alarm Reduction in ICUs, A Genetic-Algorithm Approach Mohammad Zaeri-Amirani, Fatemeh Afghah, Sajad Mousa vi School of Informatics, Computing and Cyber Systems, Northern Arizona Uni versity , Flagstaf f, AZ 86011 Email: { mohammad.zaeri-amirani,fatemeh.afghah, sajadmousa vi } @nau.edu Abstract —High false alarm rate in intensive care units (ICUs) has been identified as one of the most critical medical challenges in recent y ears. This often results in overwhelming the clinical staff by numer ous false or unurgent alarms and decreasing the quality of care through enhancing the probability of missing true alarms as well as causing delirium, str ess, sleep depriv ation and depr essed immune systems for patients. One major cause of false alarms in clinical practice is that the collected signals fr om different de vices are processed individually to trigger an alarm, while there exists a considerable chance that the signal collected fr om one device is corrupted by noise or motion artifacts. In this paper , we propose a low- computational complexity yet accurate game-theoretic fea- ture selection method which is based on a genetic algorithm that identifies the most informati ve biomarkers across the signals collected from various monitoring devices and can considerably reduce the rate of false alarms 1 . I . I N T RO D U C T I O N False alarms are widely considered the number one hazard imposed by the use of medical technologies. The Emergenc y Care Research Institute (ECRI) named alarm hazards as number 1 of the ”T op 10 Health T echnology Hazards” for sev eral years [1]. These false alarms can be due to se veral factors such as lo w threshold setting of the monitoring de vices, motion artifacts, and sensor detachment or malfunction causing alarm fatigue among caregi vers. This in turn results in desensitization to alarms, noise disturbances and the possibility of missing a true life-threatening ev ent lost among multiple alarms, a condition known as the cry-wolf ef fect [2], [3]. The false alarms can also result in care disruption, sleep depriv ation, patient anxiety , inferior sleep structure, and depressed immune systems [4]. While the majority of current studies in this area focus on determining the optimal level of sensitivity for sensors, designing more accurate monitoring devices or more sophisticated data 1 This work was partially sponsored by the National Science Foun- dation under grant 1657260. mining, and signal processing techniques to enhance the accuracy of false alarm detection using extracted information from individual monitoring devices, they often neglect the f act that most of the alarms triggered by individual sensors are considered false. This could be due to sev eral factors including sensor detachment or motion artifacts. Therefore, extracting the correlation of information across different collected signals can play a significant role in identifying the false alarms [5], [6]. One potential challenge of such correlation extrac- tion among multiple collected signals is enhancing the computational comple xity and the processing time of false alarm detection process as well as increasing the chance of ov er-fitting the trained model. Feature selection techniques can contribute to impro ving the prediction accuracy and reliability of such methods by removing irrelev ant or redundant attributes across the big datasets. Howe v er , these methods usually ev aluate indi vidual con- tribution of the features and overlook their group impact when clustered together . Therefore, con ventional feature selection techniques often discard the features that are highly correlated to the currently selected attributes, while these removed features can play a critical role in enhancing the accuracy of a model when grouped with other features. The concept of coalition game theory has been re- cently applied to the feature selection problem as a means to capture the effect of grouping the features [7], [8]. In these techniques, the impact of each feature is measured by calculating its Shapley value which is the average marginal contribution of each feature in enhancing the classification accuracy when it joins a coalition of selected features. Howe ver , the intensiv e computations in v olved in Shapley measurements make these methods impractical in predicti ve modeling appli- cations with a large number of features. The estimation methods currently proposed to reduce this computational complexity , instead of calculating the Shapley v alue 2 using all possible coalitions, only select a subset of these coalitions in a random manner . This approximation often compromises the performance of these techniques in ap- plications where a high le vel of accurac y and reliability is expected. In this paper , we propose a genetic-algorithm- based method to estimate the Shaple y value with a lower computational complexity in comparison to other Shapley estimation methods such as Monte-Carlo-based algorithms. In the proposed method, the most impactful coalitions of features are identified in a re volutionary process and are used to estimate the av erage impact of all coalitions. Such effecti ve coalition sampling reduces the computational complexity of Shapley estimation by not calculating the impact of a large number of possi- ble coalitions. Furthermore, in the previously reported game-theoretic based feature selection techniques, the contribution of each feature is measured based on its impact on enhancing the accuracy [7], [8]. Howe v er , in false alarm detection and many other medical diagnosis applications, capturing the true positi ves is imperati ve. Therefore, enhancing the sensiti vity is a more crucial factor to measure the performance of a predicti ve model. In this paper, we proposed a new metric to define the Shapley value of features that captures both sensitivity and specificity of a predictiv e model. I I . D A T A S E T D E S C R I P T I O N In this study , we use the publicly av ailable alarm dataset for ICUs by ”PhysioNet computing in cardiology challenge 2015” that focuses on fiv e life threatening arrhythmias including asystole, extreme bradycardia, ex- treme tachycardia, ventricular tachycardia, and ventricu- lar fibrillation [9], [10]. One objective of the proposed model is to reduce the rate of false alarms by considering the correlation among signals collected from different monitoring devices, therefore we considered 220 patients out of the entire training dataset with total of 750 patients for which three main signals of electrocardio- gram II(ECG II), arterial blood pressure (ABP), and photoplethysmogram (PPG or PLETH) were available. The signals were re-sampled to 12 bit and 250 Hz and filtered by a Finite Impulse Response (FIR) bandpass [0.05 to 40 Hz] and mains notch filters for denoising. The alarms were labeled with a team of expert to either ’true’ or ’f alse’. Among 220 reported alarms, 50 of those were true and the rest were false. Motiv ated by the noticeable performance of discrete wa velet transform (D WT) in e xtracting informative time- frequency components of the physiological signals [11], [12], we applied this method to the three input signals of ECG II, ABP and PLETH. Six lev el decomposition using db8 for ECGII and db4 for ABP and PLET signals is utilized. Therefore, the three 1-D signals of each patient is con verted into 18 vectors of wa velet coef fi- cients. Since such transform generates a large number of wa velet coefficients that in turn can result in over - fitting of the trained model, we extract 20 statistical and information theoretical-based features of each wavelet vector coef ficients. Some example features include mean, mode, median, range, variance, kurtosis, skewness, har- monic mean, interquartile range, Shannon entropy and log entropy . Moreov er , in order to employ the Heart Rate V ariation (HR V) information of the ECG II signals, a multi-resolution W avelet technique is used to detect R- peaks of the signal [13], [14]. Afterward, the in verse R-R intervals which is so-called HR V signal is calculated and 20 statistical and information theoretical-based features of this HR V signal are extracted. These 20 features are listed in T able I. T ABLE I S T A T I S TI C A L A N D I N F OR M A T I ON - T H EO R E TI C F E A T U R E S O F W A V EL E T V E C TO R S . No Feature No Feature No Feature 1 mean 8 std ( σ ) 15 Interquartile 2 mode 9 µ 3 Range 3 median 10 µ 4 16 Shannon Ent. 4 max 11 coef. of var 17 Log Ent. 5 min 12 kurtosis 18 n T ( max { X i } / 2) 6 range 13 ske wness 19 n T ( max { X i } / 3) 7 variance 14 H mean 20 n T ( max { X i } / 4) After extracting 380 statistical and information theoretical-based features of the wav elet coefficients and HR V signal, the feature sets of all the subjects are normalized. Considering the limited number of subjects compared to the number of features, we used a repeated k-fold method to e v aluate the performance of the pro- posed feature selection model. In this experiment, we set k = 5 and repeated k-fold for 2 times by a random sampling manner , where created 10 copy of the database, each contains 175 observations in the training set and 45 observations in the test set. I I I . I N T RO D U C T I O N T O C OA L I T I O N G A M E S Cooperativ e (coalition) games refer to a class of game-theoretical models, where a cooperativ e behavior is enforced to the players in a w ay that the players prefer to form coalitions to obtain a higher payoff [15], [16]. Let us consider a finite non-empty set of players I = { 1 , 2 , . . . , n f } , in which n f is the number of players and each player can participate in different sub-coalitions of I . The empty coalition is denoted by ∅ while the grand coalition, i. e. I , is the coalition of all players. Also, the power set P ( I ) is the family of all sub-coalitions of the grand coalition. A cooperativ e game for the player set I is defined by a characteristic function ν : P ( I ) → R + ∪ { 0 } with 3 ν ( ∅ ) = 0 , where ν ( T ∈ P ( I )) represents the v alue of coalition T . W e use the notation G ( I , ν ) to represent all cooperativ e games on players in I with characteristic function ν . A cooperati ve game ν is conv ex if for all T , S ∈ P ( I ) we hav e ν ( S ∪ T ) + ν ( S ∩ T ) ≥ ν ( S ) + ν ( T ) . The con ve x game ν is called super-additi ve if for all disjoint S , T ∈ P ( I ) we hav e ν ( S ∪ I ) ≥ ν ( S ) + ν ( T ) [15]. The marginal contribution of player i when it joins coalition T ⊆ I \{ i } is defined as: ∇ i ( T ) = ν ( T ∪ { i } ) − ν ( T ) . (1) Shaple y value is a well-known solution concept for ν ∈ G ( I , ν ) which measures the marginal contrib ution of each player i over all coalitions T ⊆ I \{ i } . Shapley function φ : G ( I , ν ) → ( R + ∪ { 0 } ) P ( I ) , also called Shapley value on G ( I , ν ) , needs to satisfy four axioms of coalition efficiency , dummy players, symmetry , and game additivity [7]. It has been prov en that the following function φ : G ( I , ν ) → ( R + ∪ { 0 } ) P ( I ) satisfies these aforementioned axioms: φ i ( ν ) = X T ⊆I \{ i } |T | ( n f − |T | − 1)! n f ! ( ν ( T ∪{ i } ) − ν ( T )) (2) Coalition games have been recently applied to feature selection applications, where the features are considered as the players of the game [17]–[19]. In these works, a coalition represents a group of features used for classi- fication, where Shaple y value of each feature measures the contribution of this feature in classification accuracy . Therefore, we can use Shapley value of each feature as its membership grade in the best coalition to identify the most salient features in the dataset. Howe ver , the considerable drawback of these methods is the associ- ated computational complexity , because computing the Shapley v alue for each feature requires calculating the marginal contrib utions of that feature over all possible coalitions of any size. Therefore, these Shapley value- based methods either in volv e an intractable computa- tional complexity for a large number of features or result in a degraded performance where a sub-group of all coalitions are randomly selected for Shapley calculation. In the next section, we propose a genetic-algorithm based method to distinguish an optimal set of coalitions to be utilized in estimating the features’ Shapley values with low computational complexity and high accuracy . I V . P RO P O S E D G A - BA S E D M O N T E - C A R L O M E T H O D F O R S H A P L E Y V A L U E S C A L C U L A T I O N Noting the definition of Shaple y value, the mathe- matical formulation of Shapely value of the i ’th player presented in (2) can be rewritten as: φ i ( ν ) = 1 n f n f − 1 X t =0 1 n f − 1 t X |T | = t,i 6∈T [ ν ( T [ { i } ) − ν ( T )] | {z } E ( X t i ) (3) where E ( X t i ) is the av erage marginal contribution of player i o ver all coalitions with size t not including i itself. This factor measures the effect of feature i in classification accuracy when grouped with other features in dif ferent coalitions. The term av erage leads us to reducing computational complexity by operating Monte Carlo simulations over the n f − 1 t possible coalitions of size t . Since there is no considerable correlation among the features in large-size coalitions; therefore we limit the calculation of marginal contrib ution of feature i to the coalitions with size less than a specific threshold, i. e. n max f − 1 . This in turn reduces the computational complexity of Shapley value calculation. Hence, the approximated shapely value of i ’th feature can be written as: ˆ φ i ( ν ) = 1 n max f n max f − 1 X t =0 E ( X t i ) . (4) In the following, we describe our proposed method to identify a subset of coalitions that provide higher marginal information in calculating Shapley v alue of user i . A. Pr oposed Genetic-algorithm based Shapley value cal- culation In order to estimate the Shaple y v alue of each fea- ture, we propose a genetic-algorithm (GA) method to generate the most effecti ve subset of coalition sample sets. Such GA-based method inv olves defining proper chromosomes, fitness of each chromosome, and a revolu- tionary process of generating ne w generations. Moreov er , parent selection, crossov er and mutation are essential operations for a rev olutionary process. The steps of the proposed GA are described in details as follows: a) Chr omosomes: The Shapley value estimation formula required an av erage on the marginal coalition values of the i ’ th feature over the coalitions of size t . Hence, we define each chromosome as a binary vector of length n f − 1 which has exactly t ones. By this, each chromosomes is mapped to a coalition with cardinality t . b) F itness Function: While the majority of the current game-theoretic based feature selection methods only focus on enhancing the accuracy of classification in dif ferent supervised learning applications, one ke y contribution of our proposed feature selection method is 4 to target elev ating the Receiv er-Operating Characteristic (R OC) curve as a measurement criterion for marginal contribution based on the rate history of the alarms. That enables us to not only increase the sensitivity of the classification but also enhance its specificity that is a particular interest to the false alarm reduction applica- tion. T o achiev e this goal, the value of a coalition, i.e. ν ( T ) , is proposed as a linear combination of specificity and sensitivity rates as defined in follow: ν ( T ) = (1 − F N R T ) + µ (1 − F P R T ) 1 + µ , (5) where F N R T and F P R T are the false negativ e and false positiv e rates obtained from the classifier , respec- tiv ely and µ is a constant design parameter based on the history of the alarms. This model is appropriate for the imbalance data such as the av ailable data for alarm dataset for ICUs. Now , we define the fitness function of the proposed genetic algorithm, for a giv en feature i , the chromosome corresponds to the coalition T which does not include i , and a given coalition value as f i ( ν )( chr ( T )) = ν ( T ∪ { i } ) − ν ( T ) . (6) In other w ord, the fitness of each chromosome for a gi v en feature, is defined as the marginal v alue of the feature ov er the corresponding coalition. c) P arent Selection: F or each feature, we randomly generate n p chromosomes, so called population, of the length n f − 1 which each contains exactly t ones. After calculating the population finesses, two chromosomes are being selected based on a random selection mechanism so called roulette mechanism. In the roulette mechanism, after normalizing the fitness set of population, a chromo- some is selected with the probability proportional to the normalized fitness of the chromosomes in the population. d) Cr ossover: In the crossov er operation, two par- ents chromosomes are combined to generate two off- springs chromosomes such that those inherent path from both parents. In our proposed chromosome type, the crossov er operation is done by finding non-unique same size chops of the parents chromosomes that locate in the same location, have the same number of ones, and have a length greater than one; then we randomly select one of those chops and e xchange the chops between two parents chromosomes. Howe ver , it is possible that such chops do not exist in the parents chromosomes. In that case, each parents chromosomes is updated via a hermaphrodite cross over operation in which a randomly selected chop of chromosome is chosen and after reversion, fit back to its location in the chromosome. e) Mutation: In most rev olutionary techniques, some randomness is required to obtain the div ersity in the field search. W e consider mutation of one bit 0 and one bit 1 in each offsprings’ chromosomes. After mutation we add the generated of fsprings’ chromosomes to the population, calculate their corresponding fitness, and update population by remo ving two chromosomes with lo west fitness from it. Ho we ver , we keep those chromosomes as a valid sample set for estimating the Shapley value of the i ’th feature. In follo w , we discuss the relation between statistical properties of the samples obtained from GA and statisti- cal properties of all possible feature coalitions with size t . B. Mean Adjustment of Samples The proposed GA algorithm for generating coalition samples tends to select the chromosomes with highest marginal contribution for i ’th feature. The marginal con- tribution of the selected coalitions for feature i can be modeled as random variable Y t i which is the maximum among M marginal contrib ution samples of all size- t coalitions, i. e. { X t i,m } M m =1 . This relation can be written as Y t i = max { X t i,m } M m =1 . The samples X t i,m are independent, so the Cumulative Density Function (CDF) of random v ariable Y t i , when M >> 1 , can be written as F Y t i ( y ) = exp( − exp( − y − u α )) , −∞ < y < ∞ , α > 0 [20], and the distribution of Y t i is called Extreme T ype 1 (EX1) distribution. The parameters α and u of the EX1 distribution are the root square v ariance and mean of the distribution X t i . The expected value and variance of EX1 can be estimated as E { Y t i } = u + 0 . 5722 α and V ar { Y t i } = 1 . 645 α 2 . Assuming n G is the number of generated samples from GA such that n G << n f − 1 t , then M = b ( n f − 1 t ) n G c is large enough and we can use the abov e mentioned approximation., which obtained from GA, by EX1 dis- tribution. Therefore, by extracting the statistical informa- tion of the samples Y t i , the mean (and variance) of all marginal information of size t coalitions for feature i will be estimated. Finally , the n f features with highest Shap- ley v alues are selected for the classification purposes. In the ne xt section, we analyze the complexity of the proposed feature selection algorithm. V . C O M P L E X I T Y A NA L Y S I S The Shapley v alue based feature selection methods in volv e an e xponential computational complexity that make them being classified as NP-hard problem. Hence, feature selection methods based on calculating Shapley values of the features are computationally intractable when the number of features is very large. Howe ver , 5 one may reduce the complexity order of this process by limiting the size of feature coalitions which are considered for Shapley v alue calculation [18]. In that scenario, the complexity of the algorithm is reduced to O ( n n max f f ) , ho we ver the performance is also degraded. One considerable advantage of our proposed method compared to previously reported game-theoretic based feature selection techniques is a lo wer computational complexity in estimating Shapley value by employing a GA-based Monte-Carlo method. This method reduces the complexity order of the estimation to O ( n f × n max f × n G ) . V I . N U M E R I C A L R E S U L T S In this section, we present the numerical results to ev aluate the performance of the proposed GA-based method in identifying the salient features. W e used the publicly av ailable alarm dataset for ICUs from PhysioNet challenge 2015 and extracted 380 features for each pa- tient as described in Section II. In the proposed method, we measured the impact of each feature over coalitions with size of less than 20 by getting the average of marginal contributions over 100 coalitions of each size that are selected by the proposed genetic algorithm. The Shapley v alue of each feature is then estimated by finding the average of the obtained marginal contributions for all coalition sizes. This process is repeated for three dif ferent values of µ = 0 . 5 , 1 . 0 and 3 . 5 in (5). The 20 features with highest Shapley values for each µ are selected for classification purposes. In T able II, the performance of the proposed feature selection method is compared with sev eral popular feature selection methods including χ 2 , T ree-based method in which forest of trees are used for calculating feature values [21], Mutual Gain Information, Relief, and three types of Wrapper feature selection approaches. The output of each feature selection method is then ev aluated using different classifiers including decision trees, discriminant analysis, logistic regression, Support V ector Machine (SVM), Nearest Neighbors, and ensemble classifiers. Howe ver among different classifica- tion methods, the R USBoosted T rees Ensemble method is reported since higher sensiti vity v alues for feature selection methods are achieved. This result also sho ws a balance between the sensi- tivity and specificity of the proposed model that can be obtained by tuning the µ value. As it can be seen from this table, the obtained sensiti vity from the pro- posed method has highest value among all other feature selection methods. Figure 1 compares the R OC curves of the proposed feature selection with other feature selection approaches. As it is shown in this figure, the R OC of the Shapley method with µ = 3 . 5 has highest values after false alarm Fig. 1. The R OC of different feature selection methods with their best classification in terms of A UC. 0.6, and the curve is above most of the other ROC’ s for false alarms less than 0.6. Another aspect of our work is employing dif ferent biomedical signals and different signal processing types (W av elet and HR V for ECG II signals) for the purpose of increasing the classification performance. T able III shows the frequency analysis of the number of features which are selected during dif ferent feature selection approaches from dif ferent biomedical signals or signal processing type. One of the interesting results from this is that the proposed algorithm which selects features with high mar ginal contrib utions, selects more features from W avelet features than the HR V features. This table also shows that employing different source of biomedical signal is useful. It can be also seen that most of the selected features in the proposed algorithm are from ECG II W avelet features and the PLETH W av elet features. It can be justified with the sense that if the number of signal sources increased, the chance of adding more correlated features is also increased. V I I . C O N C L U S I O N In this paper, a lo w-complexity feature selection method for false alarm reduction in ICUs is proposed, where the Shapley values of the features extracted from physiological signals are estimated through a GA-based algorithm. These Shapley values ev aluate the impact of grouping of multiple features in enhancing sensiti vity and specificity of the trained model. The numerical results sho w that the specificity of this propose method is comparable to other existing feature selection methods while it offers a higher sensiti vity as desired in alarm detection application to assure capturing the true alarms. 6 T ABLE II C O MPA R IS O N O F C LA S S I FIC A T I O N P E RF O R M AN C E F O R D I FF ER E N T F E A T U RE S E LE C T IO N M ET H O D S W I TH B E ST C L AS S I FI ER S I N T E RM S O F AC C U RA C Y A N D / O R AU C Feature Selection Accuracy A UC Sensiti vity Specificity Shapley µ = 3 . 5 0.77 0.81 0.73 0.75 Shapley µ = 1 . 0 0.75 0.80 0.72 0.75 Shapley µ = 0 . 5 0.76 0.80 0.70 0.77 χ 2 0.71 0.77 0.71 0.72 T ree Based 0.75 0.79 0.66 0.78 Mutual Gain Information 0.76 0.84 0.73 0.75 Relief 0.81 0.77 0.60 0.87 Wrapper: LASSO 0.76 0.82 0.66 0.79 Wrapper: Ridge Regression 0.73 0.77 0.62 0.76 Wrapper: Logit Regression 0.75 0.76 0.62 0.78 T ABLE III F R EQ U E NC Y A NA L Y S IS O F S E L EC T E D F E A T UR E S B A SE D O N S I GN A L T Y PE S A ND S I GN A L P RO C ES S I N G T Y PE S F OR D I FFE R E NT F E A T UR E S E LE C T I ON T E CH N I QU E S . Feature Selection T otal ECG II W av elet PLETH W av elet ABP W av elet ECG II HR V Shapley µ = 0 . 5 20 0 20 0 0 Shapley µ = 1 . 0 20 5 15 0 0 Shapley µ = 3 . 5 20 6 14 0 0 χ 2 20 0 14 6 0 Tree Based 139 47 53 33 6 Mutual Gain Information 20 17 0 0 0 Relief 20 2 16 2 0 Wrapper: LASSO 25 9 11 4 1 Wrapper: Ridge Regression 136 44 57 26 9 Wrapper: Logit Regression 148 50 55 32 11 R E F E R E N C E S [1] “T op 10 health technology hazards for 2015, ” Emergency Care Research Institute (ECRI), T ech. Rep., 2014. [2] S. Sendelbach and M. Funk, “ Alarm fatigue, a patient safety concern, ” AA CN Advanced Critical Car e , vol. 24, no. 4, pp. 378– 386, 2013. [3] G. D. Clif ford, I. Silva, B. Moody , Q. Li, D. Kella, A. Chahin, T . K ooistra, D. Perry , and R. G. Mark, “False alarm reduction in critical care, ” Physiolo gical Measur ement , vol. 37, no. 8, p. E5, 2016. [Online]. A v ailable: http: //stacks.iop.org/0967- 3334/37/i=8/a=E5 [4] M. Imhof f and S. K uhls, “ Alarm algorithms in critical care monitoring, ” Anesthesia & Analgesia , vol. 102, no. 5, pp. 1525– 1537, 2006. [5] Q. Li and G. D. Clif ford, “Suppress false arrhythmia alarms of icu monitors using heart rate estimation based on combined arterial blood pressure and ecg analysis, ” in 2008 2nd International Confer ence on Bioinformatics and Biomedical Engineering , May 2008, pp. 2185–2187. [6] N. Sadr, J. Huvanandana, D. T . Nguyen, C. Kalra, A. McEwan, and P . de Chazal, “Reducing false arrhythmia alarms in the icu by hilbert qrs detection, ” in Computing in Car diology Confer ence (CinC), 2015 . IEEE, 2015, pp. 1173–1176. [7] F . Afghah, A. Razi, S. R. Soroushmehr, S. Molaei, H. Ghanbari, and K. Najarian, “ A game theoretic predictive modeling approach to reduction of false alarm, ” in International Conference on Smart Health . Springer, 2015, pp. 118–130. [8] A. Razi, F . Afghah, and V . V aradan, “Identifying gene subnet- works associated with clinical outcome in ovarian cancer using network based coalition game, ” in 37th Annual International Confer ence of the IEEE Engineering in Medicine and Biology Confer ence (EMBC’15) , 2015. [9] PhysioNet, Reducing F alse Arrhythmia Alarms in the ICU , 2015, accessed July 28, 2016. [Online]. A vailable: http: //www .physionet.or g/challenge/2015/ [10] G. Clifford, I. Silv a, B. Moody , Q. Li, D. Kella, A. Chahin, T . K ooistra, D. Perry , and R. Mark, “False alarm reduction in critical care, ” Physiological Measurement , vol. 37, no. 8, pp. 5– 23, 2016. [11] C. Saritha, V . Sukanya, and Y . Narasimha Murthy , “Ecg signal analysis using wavelet transforms, ” Bulgarian Journal of Physics , vol. 35, pp. 68–77, 2008. [12] A. Prochazka, J. Kukal, and O. Vysata, “W avelet transform use for feature extraction and ee g signal segments classification, ” in Communications, Contr ol and Signal Pr ocessing, 2008. ISCCSP 2008. 3rd International Symposium on , March 2008, pp. 719–722. [13] S. Banerjee, R. Gupta, and M. Mitra, “Delineation of ecg charac- teristic features using multiresolution wavelet analysis method, ” Measur ement , v ol. 45, no. 3, pp. 474–487, 2012. [14] J. Chen, H. Peng, and A. Razi, “Remote E C G monitoring kit to predict patient-specific heart abnormalities, ” J ournal of Systemics, Cybernetics and Informatics , vol. 15, no. 4, pp. 82–89, 2017. [15] M. J. Osborne, An intr oduction to game theory . Oxford univ ersity press New Y ork, 2004, vol. 3, no. 3. [16] A. R. Korenda, M. Zaeri-Amirani, and F . Afghah, “ A hierarchical stackelberg-coalition formation game theoretic frame work for cooperativ e spectrum leasing, ” in 2017 51st Annual Conference on Information Sciences and Systems (CISS) , March 2017, pp. 1–6. [17] G. Cohen, S. Dror and G. Ruppin, “Feature selection via coali- tional game theory , ” Neural Computation , vol. 19, no. 7, pp. 1939–1961, 2007. [18] F . Afghah, A. Razi, and K. Najarian, “ A shapley value solution to game theoretic-based feature reduction in false alarm detection, ” arXiv preprint arXiv:1512.01680 , 2015. [19] A. Razi, F . Afghah, A. Belle, K. W ard, and K. Najarian, “Blood loss se verity prediction using game theoretic based feature selec- tion, ” in IEEE-EMBS International Conferences on Biomedical and Health Informatics (BHI’14) , 2014, pp. 776–780. [20] P . Jowitt, “The extreme-v alue type-1 distribution and the principle of maximum entropy , ” Journal of Hydr ology , vol. 42, no. 1-2, pp. 23–38, 1979. [21] F . Pedregosa, G. V aroquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P . Prettenhofer, R. W eiss, V . Dubourg et al. , “Scikit-learn: Machine learning in python, ” Journal of machine learning resear ch , vol. 12, no. Oct, pp. 2825–2830, 2011.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment