Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks with Existing Applications
Existing applications include a huge amount of knowledge that is out of reach for deep neural networks. This paper presents a novel approach for integrating calls to existing applications into deep learning architectures. Using this approach, we estimate each application’s functionality with an estimator, which is implemented as a deep neural network (DNN). The estimator is then embedded into a base network that we direct into complying with the application’s interface during an end-to-end optimization process. At inference time, we replace each estimator with its existing application counterpart and let the base network solve the task by interacting with the existing application. Using this ‘Estimate and Replace’ method, we were able to train a DNN end-to-end with less data and outperformed a matching DNN that did not interact with the external application.
💡 Research Summary
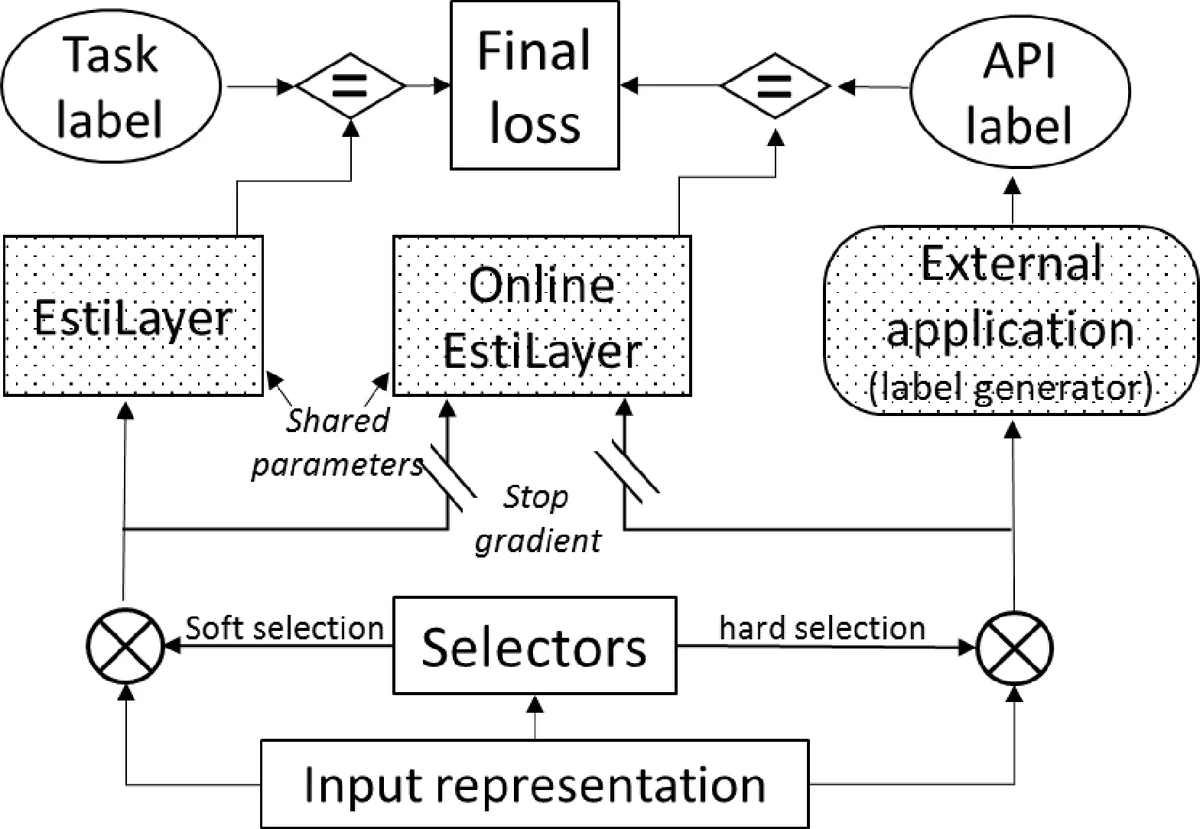
The paper introduces a novel framework called “Estimate and Replace” for integrating non‑differentiable legacy applications into deep neural network (DNN) pipelines. The central problem addressed is that end‑to‑end training of DNNs relies on gradient back‑propagation, which cannot directly incorporate external APIs that lack differentiable implementations. To overcome this, the authors propose to learn a differentiable surrogate for each external function, termed an EstiLayer, and embed these surrogates within a larger network called EstiNet. During training, EstiLayers approximate the behavior of the real APIs while the rest of the network learns to invoke them correctly. At inference time, each EstiLayer is swapped out for its actual counterpart, allowing the model to benefit from the exact, high‑precision computation of the legacy code.
EstiNet consists of three logical components: (1) an input representation module that encodes complex inputs (e.g., a natural‑language question together with a structured table), (2) a set of selector subnetworks that decide which API to call and which arguments to pass, and (3) the EstiLayers themselves, which are implemented as generic transformer‑style DNNs. The selectors produce probability distributions over candidate APIs and arguments; to make the inherently discrete selection differentiable, the authors employ Gumbel‑Softmax, which yields a smooth approximation during training and hard selections at test time.
Training is performed using two complementary strategies. In the offline approach, each EstiLayer is first pre‑trained on synthetic input‑output pairs generated from the real API, then frozen (or optionally fine‑tuned) while the rest of EstiNet is trained on the main task. The online approach, which the authors recommend, jointly optimizes the whole system with a multi‑task loss: the standard task loss (L_model) plus two auxiliary losses computed on the soft and hard selector outputs (L_online_soft, L_online_hard). The auxiliary losses are calculated against labels produced by the real API on the selector’s chosen inputs, but gradients are blocked when updating the EstiLayer parameters with respect to these labels, ensuring that the EstiLayer retains the true API functionality.
The authors evaluate the method on a synthetic table‑question answering benchmark (TAQ). Each example consists of a natural‑language question and a table; solving the question requires extracting a numeric or textual argument, selecting the appropriate column, and applying a non‑differentiable operation such as “greater‑than” or “equal‑to”. The EstiNet model learns to perform all three steps: the selector identifies the correct column and operation, the EstiLayer approximates the operation, and the final classifier produces the answer. Compared against a baseline DNN that lacks any external API integration, EstiNet achieves higher accuracy with substantially fewer training examples, demonstrating data efficiency. Moreover, when the EstiLayers are replaced by the actual APIs at inference time, performance improves further, confirming that the surrogate layers have successfully learned the correct interface while the real APIs provide exact computation.
Key contributions of the work are: (1) a general-purpose mechanism for embedding arbitrary legacy code into differentiable deep learning models without re‑implementing the code in a differentiable form; (2) a multi‑task training scheme that simultaneously teaches the network the primary task and enforces compliance with the API interface; (3) empirical evidence that the approach reduces data requirements and yields better inference performance than pure end‑to‑end learning. The paper suggests future extensions such as handling longer sequences of API calls, more complex interface contracts, and applying the technique to real‑world domains like database query processing, scientific simulations, or enterprise business logic.
Comments & Academic Discussion
Loading comments...
Leave a Comment