Efficient Soft-Output Gauss-Seidel Data Detector for Massive MIMO Systems
For massive multiple-input multiple-output (MIMO) systems, linear minimum mean-square error (MMSE) detection has been shown to achieve near-optimal performance but suffers from excessively high complexity due to the large-scale matrix inversion. Being matrix inversion free, detection algorithms based on the Gauss-Seidel (GS) method have been proved more efficient than conventional Neumann series expansion (NSE) based ones. In this paper, an efficient GS-based soft-output data detector for massive MIMO and a corresponding VLSI architecture are proposed. To accelerate the convergence of the GS method, a new initial solution is proposed. Several optimizations on the VLSI architecture level are proposed to further reduce the processing latency and area. Our reference implementation results on a Xilinx Virtex-7 XC7VX690T FPGA for a 128 base-station antenna and 8 user massive MIMO system show that our GS-based data detector achieves a throughput of 732 Mb/s with close-to-MMSE error-rate performance. Our implementation results demonstrate that the proposed solution has advantages over existing designs in terms of complexity and efficiency, especially under challenging propagation conditions.
💡 Research Summary
The paper addresses the prohibitive computational cost of linear minimum‑mean‑square‑error (MMSE) detection in massive multiple‑input multiple‑output (MIMO) systems, where the required matrix inversion scales as O(N³) with the number of antennas. To avoid this bottleneck, the authors propose a soft‑output detector based on the Gauss‑Seidel (GS) iterative method, together with a hardware‑friendly VLSI architecture.
Key contributions are:
-
Fast‑converging initial solution – By exploiting the diagonal‑dominance of the regularized Gram matrix W in massive MIMO, a two‑term Neumann series expansion (NSE) is used to approximate W⁻¹ as W⁻¹₂ = D⁻¹ – D⁻¹ E D⁻¹, where D is the diagonal part and E the off‑diagonal part. Multiplying this approximation with the matched‑filter output y_MF yields an initial estimate s(0) that is already close to the exact MMSE solution.
-
Improved GS (IGS) algorithm – After preprocessing (computing W and y_MF, and decomposing W = D + L + Lᴴ), the detector iteratively updates the estimate using s(k) = (D + L)⁻¹ (y_MF – Lᴴ s(k‑1)) for a small number K of iterations (typically 2–3). Because the initial point is accurate, convergence is rapid and the overall complexity becomes O((K+2) N_t²) complex multiplications, a dramatic reduction compared with O(N³).
-
Efficient soft‑output (LLR) computation – The log‑likelihood ratios needed for channel decoding are derived from the approximate effective channel gains μ_i. Instead of computing the exact inverse W⁻¹, the authors reuse the two‑term NSE approximation, obtaining μ_i ≈ 1 – N₀ W⁻¹₂_ii. This eliminates an extra matrix inversion while preserving the accuracy of the LLRs.
-
Hardware architecture – The detector is partitioned into five pipeline‑friendly blocks: Pre‑processing Unit (PU), Gauss‑Seidel Method Unit (GSMU), Initial Solution Computation Unit (ISCU), SINR Computation Unit (SCU), and LLR Computation Unit (LCU). The lower‑triangular solve (D + L)⁻¹ is implemented with a dedicated systolic array, and all matrix‑vector multiplications are performed with parallel complex multipliers. Memory accesses are carefully scheduled to avoid stalls, and the design is fully pipelined to achieve high throughput.
-
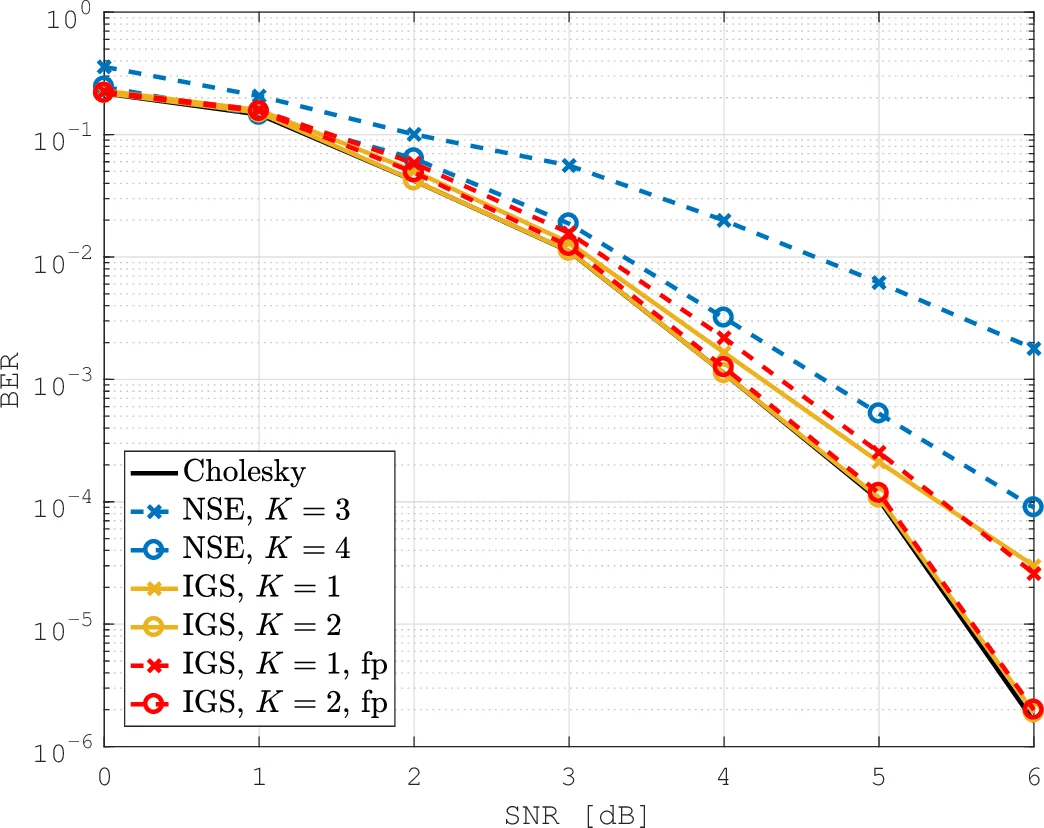
Complexity and performance analysis – Theoretical analysis shows that the total number of complex multiplications per detection is (K + 2) N_t². Simulation results for 64‑QAM with a 1/2‑rate convolutional code demonstrate that the IGS detector matches the BER of exact MMSE while requiring far fewer iterations. In correlated channel scenarios (e.g., receive correlation ζ_r = 0.4) the performance loss remains negligible.
-
FPGA implementation – A reference implementation on a Xilinx Virtex‑7 XC7VX690T FPGA for a 128‑antenna base station serving 8 users achieves 732 Mb/s throughput, with area and power consumption significantly lower than prior NSE‑based or Cholesky‑based designs.
The work shows that a carefully chosen NSE‑based initial point combined with a low‑complexity GS iteration yields a detector that is both algorithmically near‑optimal and hardware‑efficient. This makes it a strong candidate for real‑time massive MIMO receivers in 5G/6G base stations, massive IoT gateways, and ultra‑reliable low‑latency communication (URLLC) scenarios where latency, power, and silicon area are critical constraints. Future extensions could address multi‑stream users, quantization effects in ASIC implementations, and adaptive iteration control based on channel conditions.
Comments & Academic Discussion
Loading comments...
Leave a Comment